طی چند سال گذشته، قابلیت های سیستم های رباتیک به طور چشمگیری بهبود یافته است. از آنجایی که فناوری به پیشرفت خود ادامه میدهد و عوامل روباتیک به طور معمول در محیطهای دنیای واقعی مستقر میشوند، ظرفیت آنها برای کمک به فعالیتهای روزمره اهمیت فزایندهای پیدا میکند. کارهای تکراری مانند پاک کردن سطوح، تا کردن لباسها و تمیز کردن اتاق برای روباتها مناسب به نظر میرسند، اما همچنان برای سیستمهای روباتیک طراحیشده برای محیطهای ساختاریافته مانند کارخانهها چالشبرانگیز هستند. انجام این نوع کارها در محیطهای پیچیدهتر، مانند دفاتر یا خانهها، مستلزم پرداختن به سطوح بیشتری از تنوع محیطی است که توسط ورودیهای حسی با ابعاد بالا، از تصاویر بهعلاوه حسگرهای عمق و نیرو گرفته میشود.
به عنوان مثال، وظیفه پاک کردن میز را برای تمیز کردن مواد ریخته شده یا پاک کردن خرده های آن در نظر بگیرید. در حالی که این کار ممکن است ساده به نظر برسد، اما در عمل، چالش های جالب بسیاری را در بر می گیرد که در همه جا در رباتیک وجود دارند. در واقع، در سطح بالا، تصمیم گیری در مورد اینکه چگونه نشت را از مشاهده تصویر به بهترین نحو پاک کنیم، مستلزم حل یک مشکل برنامه ریزی چالش برانگیز با دینامیک تصادفی است: ربات چگونه باید پاک کند تا از پراکندگی نشت مشاهده شده توسط دوربین جلوگیری کند؟ اما در سطح پایین، اجرای موفقیت آمیز یک حرکت پاک کردن، همچنین مستلزم آن است که ربات خود را برای رسیدن به منطقه مشکل قرار دهد و در عین حال از موانع نزدیک مانند صندلی اجتناب کند و سپس حرکات خود را برای پاک کردن سطح و در عین حال حفظ تماس با میز هماهنگ کند. . حل این مشکل پاک کردن جدول به محققان کمک می کند تا به طیف وسیع تری از وظایف روباتیک، مانند تمیز کردن پنجره ها و باز کردن درها، رسیدگی کنند، که هم به برنامه ریزی سطح بالا از مشاهدات بصری و هم به کنترل دقیق غنی از تماس نیاز دارد.
 |
 |
تکنیک های مبتنی بر یادگیری مانند یادگیری تقویتی (RL) نوید حل این وظایف پیچیده دیداری- حرکتی را از مشاهدات با ابعاد بالا ارائه می دهد. با این حال، استفاده از روشهای یادگیری سرتاسر برای کارهای دستکاری موبایل به دلیل افزایش ابعاد و نیاز به کنترل دقیق سطح پایین، چالش برانگیز است. علاوه بر این، استقرار روی ربات یا مستلزم جمعآوری مقادیر زیادی داده، با استفاده از مدلهای دقیق اما از نظر محاسباتی گرانقیمت یا تنظیم دقیق سختافزاری است.
در “پاک کردن جدول رباتیک از طریق یادگیری تقویتی و بهینه سازی مسیر کل بدن”، ما یک رویکرد جدید را ارائه می دهیم تا یک ربات را قادر می سازد تا جداول را به طور قابل اعتماد پاک کند. با تجزیه دقیق کار، رویکرد ما نقاط قوت RL – ظرفیت برنامهریزی در فضاهای مشاهده با ابعاد بالا با دینامیک تصادفی پیچیده – و توانایی بهینهسازی مسیرها را ترکیب میکند و به طور موثر دستورات ربات کل بدن را پیدا میکند که رضایت از محدودیتها را تضمین میکند. مانند محدودیت های فیزیکی و اجتناب از برخورد. با توجه به مشاهدات بصری سطحی که باید تمیز شود، خط مشی RL اقدامات پاکسازی را انتخاب می کند که سپس با استفاده از بهینه سازی مسیر اجرا می شوند. با استفاده از یک شبیهساز جدید معادله دیفرانسیل تصادفی (SDE) برای آموزش خط مشی RL برای برنامهریزی سطح بالا، رویکرد پایان به انتها پیشنهادی از نیاز به دادههای آموزشی ویژه کار اجتناب میکند و قادر به انتقال صفر است. به سخت افزار شلیک شده است.
ترکیب نقاط قوت RL و کنترل بهینه
ما یک رویکرد انتها به انتها برای پاک کردن جدول پیشنهاد میکنیم که از چهار جزء تشکیل شده است: (1) سنجش محیط، (2) برنامهریزی نقاط بین راهی سطح بالا با RL، (3) مسیرهای محاسباتی برای سیستم کل بدن (یعنی برای هر مفصل) با روش های کنترل بهینه، و (4) اجرای مسیرهای پاکسازی برنامه ریزی شده با یک کنترل کننده سطح پایین.
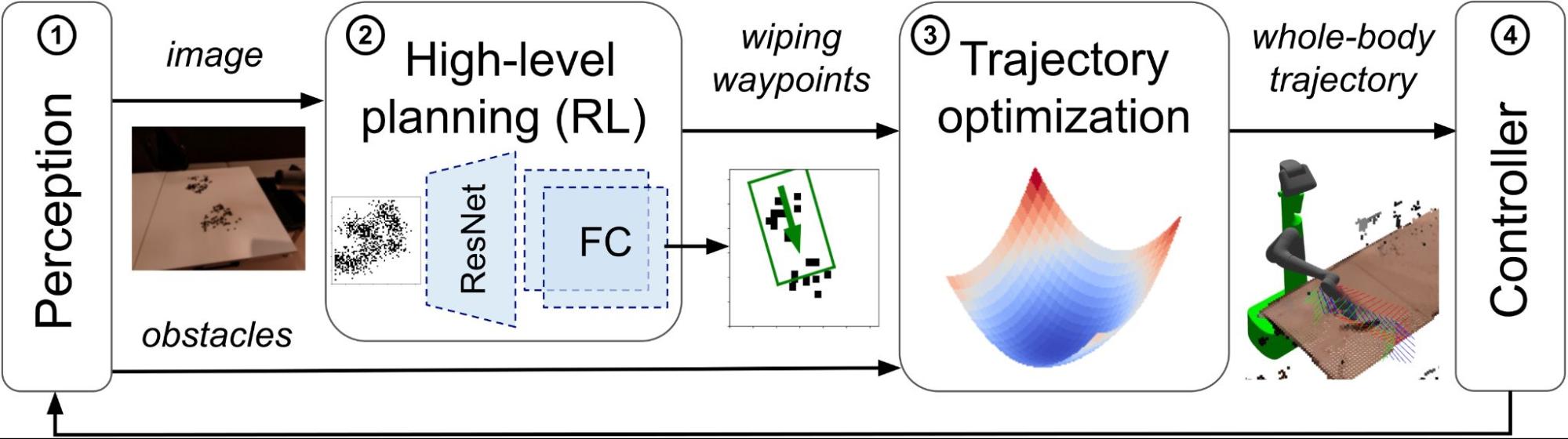 |
| معماری سیستم |
مؤلفه جدید این رویکرد یک خط مشی RL است که به طور مؤثر نقاط بین راهی را با توجه به مشاهدات تصویری ریخته شده و خرده نشت ها برنامه ریزی می کند. برای آموزش خط مشی RL، مشکل جمع آوری مقادیر زیادی داده در سیستم روباتیک را به طور کامل دور می زنیم و از استفاده از یک شبیه ساز فیزیک دقیق اما از نظر محاسباتی گران قیمت اجتناب می کنیم. رویکرد پیشنهادی ما بر یک معادله دیفرانسیل تصادفی (SDE) برای مدلسازی دینامیک پنهان خردهها و ریختهها متکی است که یک شبیهساز SDE با چهار ویژگی کلیدی به دست میدهد:
- این می تواند هم اجسام خشک را که توسط برف پاک کن فشار داده می شوند و هم مایعات جذب شده در حین پاک کردن را توصیف کند.
- می تواند به طور همزمان چندین نشت جدا شده را بگیرد.
- این مدل عدم قطعیت تغییرات در توزیع ریختهها و خردهها را در تعامل ربات با آنها انجام میدهد.
- این سریعتر از زمان واقعی است: شبیه سازی پاک کردن تنها چند میلی ثانیه طول می کشد.
 |
 |
| شبیه ساز SDE امکان شبیه سازی خرده های خشک (ترک کرد، که در طول هر پاک کردن فشار داده می شوند و ریخته می شونددرست) که در حین پاک کردن جذب می شوند. شبیه ساز اجازه می دهد تا ذرات با ویژگی های مختلف، مانند با ضرایب جذب و چسبندگی مختلف و سطوح عدم قطعیت مختلف، مدل سازی شود. |
این شبیه ساز SDE قادر است به سرعت مقادیر زیادی داده برای آموزش RL تولید کند. ما شبیهساز SDE را با استفاده از مشاهدات ربات با پیشبینی تکامل ذرات درک شده برای یک پاکسازی مشخص اعتبار میدهیم. با مقایسه نتیجه با ذرات درک شده پس از اجرای پاک کردن، مشاهده می کنیم که مدل به درستی روند کلی دینامیک ذرات را پیش بینی می کند. یک سیاست آموزش دیده با این مدل SDE باید بتواند در دنیای واقعی به خوبی عمل کند.
 |
با استفاده از این مدل SDE، ما یک مشکل برنامه ریزی پاک کردن سطح بالا را فرموله می کنیم و یک خط مشی پاک کردن مبتنی بر دید را با استفاده از RL آموزش می دهیم. ما به طور کامل شبیه سازی را بدون جمع آوری مجموعه داده با استفاده از ربات آموزش می دهیم. ما به سادگی حالت اولیه SDE را تصادفی می کنیم تا طیف گسترده ای از دینامیک ذرات و اشکال ریخته شده را که ممکن است در دنیای واقعی ببینیم پوشش دهیم.
در استقرار، ابتدا مشاهدات تصویری ربات را به سیاه و سفید تبدیل می کنیم تا ریزش ها و ذرات خرد شده را بهتر جدا کنیم. سپس از این تصاویر “آستانه” به عنوان ورودی خط مشی RL استفاده می کنیم. با این رویکرد، ما نیازی به شبیهساز بصری واقعی نداریم، که توسعه آن پیچیده و بالقوه دشوار است، و میتوانیم شکاف سیم به واقعی را به حداقل برسانیم.
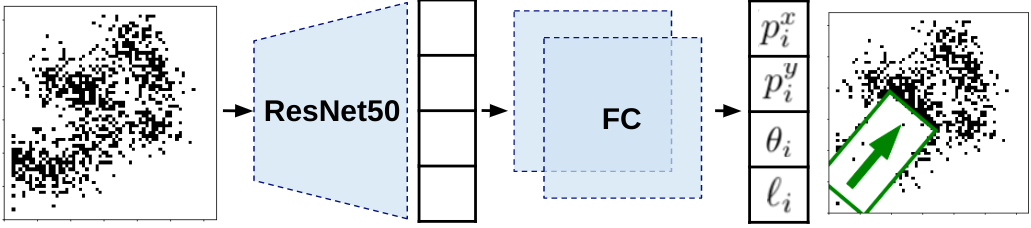 |
| ورودی های خط مشی RL مشاهدات تصویر آستانه ای از وضعیت تمیزی جدول است. خروجی آن اقدامات پاکسازی مورد نظر است. این خط مشی از معماری شبکه عصبی ResNet50 و به دنبال آن دو لایه کاملاً متصل (FC) استفاده می کند. |
حرکات پاک کردن مورد نظر از خط مشی RL با یک بهینه ساز مسیر کل بدن اجرا می شود که به طور موثر مسیرهای مفصل پایه و بازو را محاسبه می کند. این رویکرد محدودیتهای برآوردهکنندهای مانند اجتناب از برخورد را امکانپذیر میکند و استقرار عکسبرداری به صورت واقعی را امکانپذیر میکند.
 |
 |
نتایج تجربی
ما به طور گسترده ای رویکرد خود را در شبیه سازی و سخت افزار تأیید می کنیم. در شبیهسازی، خطمشیهای RL ما از خطوط پایه مبتنی بر اکتشاف بهتر عمل میکنند، و برای تمیز کردن ریختهها و خردههای ریز به دستمالهای کمتری نیاز دارند. ما همچنین خطمشیهای خود را در مورد مشکلاتی که در زمان آموزش مشاهده نشد، آزمایش میکنیم، مانند چندین منطقه نشتشده جدا شده روی میز، و متوجه میشویم که خطمشیهای RL به خوبی به این مشکلات جدید تعمیم میدهند.
| نمونه ای از اقدامات پاک کردن انتخاب شده توسط خط مشی RL (ترک کرد) و عملکرد پاک کردن در مقایسه با خط پایه (وسط، درست). خط پایه به مرکز میز پاک می شود و بعد از هر بار پاک کردن می چرخد. ما کل سطح کثیف جدول را گزارش می کنیم (وسط) و پخش ذرات خرده نان (درست) بعد از هر پاک کردن اضافی. |
رویکرد ما ربات را قادر میسازد تا بهطور قابلاعتماد نشتها و خردهها را پاک کند (بدون فشار تصادفی زبالهها از روی میز) و در عین حال از برخورد با موانعی مانند صندلی جلوگیری کند.
 |
برای نتایج بیشتر، لطفا ویدیو زیر را ببینید:
نتیجه
نتایج حاصل از این کار نشان می دهد که وظایف پیچیده دیداری-موتور مانند پاک کردن جدول را می توان بدون آموزش گران قیمت و جمع آوری داده های روی ربات به طور قابل اعتماد انجام داد. کلید شامل تجزیه کار و ترکیب نقاط قوت RL است که با استفاده از مدل SDE دینامیک ریختن و خردهریزی آموزش داده شده است، با نقاط قوت بهینهسازی مسیر. ما این کار را گامی مهم به سوی روبات های کمکی خانگی همه منظوره می دانیم. برای جزئیات بیشتر، لطفاً مقاله اصلی را بررسی کنید.
سپاسگزاریها
مایلیم از نویسندگان همکار خود، سومیت سینگ، ماریو پراتس، جفری بینگام، جاناتان وایز، بنجی هولسون، شیائوهان ژانگ، ویکاس سیندوانی، یائو لو، فی شیا، پنگ زو، تینگنان ژانگ و جی تان تشکر کنیم. ما همچنین میخواهیم از بنجی هولسون، جیک لی، آوریل زیتکوویچ و لیندا لو برای کمک و حمایتشان در جنبههای مختلف پروژه تشکر کنیم. ما به ویژه از کل تیم در Everyday Robots برای مشارکت در این کار، و برای توسعه پلتفرمی که این آزمایشها بر روی آن انجام شد، سپاسگزاریم.