
یادگیری عمیق اخیراً در طیف گستردهای از مشکلات و برنامهها پیشرفت چشمگیری داشته است، اما مدلها اغلب بهطور غیرقابل پیشبینی زمانی که در دامنهها یا توزیعهای نادیده مستقر میشوند شکست میخورند. تطبیق دامنه بدون منبع (SFDA) حوزهای از تحقیقات است که هدف آن طراحی روشهایی برای تطبیق یک مدل از پیش آموزشدیده (آموزشگرفته در «دامنه منبع») به یک «دامنه هدف» جدید، با استفاده از دادههای بدون برچسب از دومی است.
طراحی روش های انطباق برای مدل های عمیق یک حوزه مهم تحقیق است. در حالی که افزایش مقیاس مدلها و مجموعه دادههای آموزشی یک عنصر کلیدی برای موفقیت آنها بوده است، یک پیامد منفی این روند این است که آموزش چنین مدلهایی از نظر محاسباتی به طور فزایندهای گران است، در برخی موارد آموزش مدلهای بزرگ را کمتر در دسترس قرار میدهد و ردپای کربن را به صورت غیرضروری افزایش میدهد. یکی از راههای کاهش این مشکل از طریق طراحی تکنیکهایی است که میتوانند از مدلهای آموزشدیده قبلی برای مقابله با وظایف جدید یا تعمیم به حوزههای جدید استفاده و استفاده مجدد کنند. در واقع، تطبیق مدلها با وظایف جدید به طور گسترده تحت چتر یادگیری انتقالی مورد مطالعه قرار میگیرد.
SFDA یک حوزه عملی خاص از این تحقیق است زیرا چندین برنامه کاربردی دنیای واقعی که در آن سازگاری مورد نظر است از در دسترس نبودن نمونه های برچسب گذاری شده از دامنه هدف رنج می برند. در واقع، SFDA از توجه فزاینده ای برخوردار است [1, 2, 3, 4]. با این حال، اگرچه با انگیزه اهداف بلندپروازانه، اکثر تحقیقات SFDA بر اساس یک چارچوب بسیار باریک، با در نظر گرفتن تغییرات توزیع ساده در وظایف طبقه بندی تصاویر، انجام می شود.
در یک انحراف قابل توجه از آن روند، ما توجه خود را به حوزه بیوآکوستیک معطوف میکنیم، جایی که تغییرات توزیع طبیعی در همه جا وجود دارد، اغلب با دادههای برچسبدار هدف ناکافی مشخص میشود و مانعی برای پزشکان است. بنابراین، مطالعه SFDA در این نرم افزار نه تنها می تواند جامعه دانشگاهی را در مورد تعمیم پذیری روش های موجود و شناسایی مسیرهای تحقیقاتی باز آگاه کند، بلکه می تواند به طور مستقیم به دست اندرکاران این حوزه کمک کند و به یکی از بزرگترین چالش های قرن ما کمک کند: تنوع زیستی. حفظ
در این پست، «در جستجوی روشی قابل تعمیم برای تطبیق دامنه بدون منبع» را اعلام میکنیم، که در ICML 2023 ظاهر میشود. نشان میدهیم که روشهای پیشرفته SFDA میتوانند در صورت مواجهه با تغییرات توزیع واقع بینانه عملکرد ضعیفی داشته باشند یا حتی از بین بروند. آکوستیک زیستی علاوه بر این، روشهای موجود نسبت به یکدیگر متفاوت از آنچه در معیارهای بینایی مشاهده میشود، عمل میکنند، و بهطور شگفتانگیزی، گاهی اوقات بدتر از عدم سازگاری عمل میکنند. ما همچنین NOTELA را پیشنهاد میکنیم، یک روش ساده جدید که در این جابجاییها از روشهای موجود بهتر عمل میکند، در حالی که عملکرد قوی را در طیف وسیعی از مجموعه دادههای بینایی نشان میدهد. به طور کلی، ما نتیجه میگیریم که ارزیابی روشهای SFDA (فقط) در مجموعه دادههای پرکاربرد و تغییرات توزیع، ما را با دیدی نزدیکبین از عملکرد نسبی و قابلیت تعمیم آنها مواجه میکند. برای عمل به وعدههایشان، روشهای SFDA باید روی طیف وسیعتری از تغییرات توزیع آزمایش شوند، و ما از در نظر گرفتن موارد طبیعی که میتوانند برای برنامههای کاربردی با تاثیر بالا مفید باشند، دفاع میکنیم.
تغییرات توزیع در بیوآکوستیک
تغییرات توزیع طبیعی در بیوآکوستیک همه جا وجود دارد. بزرگترین مجموعه داده برچسبگذاری شده برای آواز پرندگان، Xeno-Canto (XC)، مجموعهای از ضبطهای ثبت شده توسط کاربران از پرندگان وحشی از سراسر جهان است. ضبطها در XC “کانونی” هستند: آنها فردی را هدف میگیرند که در شرایط طبیعی اسیر شده است، جایی که آواز پرنده شناساییشده در پیشزمینه است. با این حال، برای اهداف نظارت و ردیابی مستمر، پزشکان اغلب به شناسایی پرندگان علاقه مند هستند ضبط های غیرفعال (“صوتی”)، که از طریق میکروفون های همه جهته به دست می آید. این یک مشکل مستند است که کار اخیر نشان می دهد بسیار چالش برانگیز است. با الهام از این کاربرد واقعی، ما SFDA را در بیوآکوستیک با استفاده از طبقهبندیکننده گونههای پرنده که از قبل در XC به عنوان مدل منبع آموزش داده شده بود، و چندین “منظره صوتی” که از مکانهای جغرافیایی مختلف میآیند – Sierra Nevada (S. Nevada) مطالعه میکنیم. ذخیرهگاه طبیعی پودر آسیاب، پنسیلوانیا، ایالات متحده آمریکا. هاوایی؛ Caples Watershed، کالیفرنیا، ایالات متحده آمریکا; ساپساکر وودز، نیویورک، ایالات متحده آمریکا (SSW)؛ و کلمبیا – به عنوان دامنه های هدف ما.
این تغییر از حوزه کانونی شده به حوزه غیرفعال قابل توجه است: ضبطهای موجود در دومی اغلب دارای نسبت سیگنال به نویز بسیار پایینتر، صدا زدن چندین پرنده در یک زمان، و عوامل حواسپرتی و نویز محیطی مانند باران یا باد هستند. علاوه بر این، مناظر صوتی مختلف از مکانهای جغرافیایی مختلف سرچشمه میگیرند، که باعث تغییرات شدید برچسب میشود، زیرا بخش بسیار کوچکی از گونهها در XC در یک مکان مشخص ظاهر میشوند. علاوه بر این، همانطور که در داده های دنیای واقعی معمول است، هر دو حوزه منبع و هدف به طور قابل توجهی در کلاس نامتعادل هستند، زیرا برخی از گونه ها به طور قابل توجهی رایج تر از سایرین هستند. علاوه بر این، یک را در نظر می گیریم چند برچسبی مشکل طبقه بندی از آنجایی که ممکن است چندین پرنده در هر ضبط شناسایی شود، انحراف قابل توجهی از سناریوی طبقه بندی تصویر تک برچسب استاندارد که در آن SFDA معمولاً مورد مطالعه قرار می گیرد.
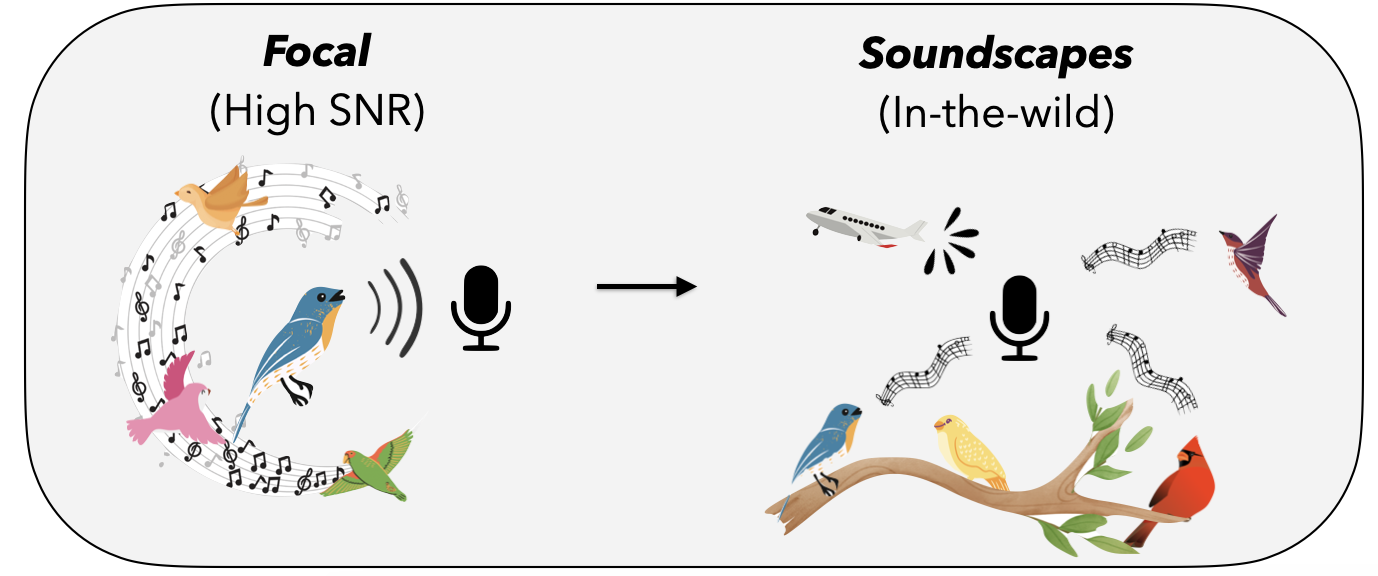 |
| تصویر تغییر “کانونی → مناظر صوتی”. در حوزه کانونی، ضبطها معمولاً از یک صدای پرنده در پیشزمینه تشکیل میشوند که با نسبت سیگنال به نویز بالا (SNR) ضبط میشود، اگرچه ممکن است پرندگان دیگری در پسزمینه صدا کنند. از سوی دیگر، مناظر صوتی حاوی ضبطهایی از میکروفونهای همه جانبه هستند و میتوانند از چندین پرنده که به طور همزمان صدا میکنند و همچنین صداهای محیطی ناشی از حشرات، باران، اتومبیلها، هواپیماها و غیره تشکیل شوند. |
| فایل های صوتی |
حوزه کانونی
|
دامنه Soundscape1 |
||
| تصاویر اسپکتوگرام |  |
 |
| تصویر تغییر توزیع از حوزه کانونی (ترک کرد) به دامنه صدا (درست، از نظر فایل های صوتی (بالا) و تصاویر طیف نگاری (پایین) از یک ضبط نماینده از هر مجموعه داده. توجه داشته باشید که در کلیپ صوتی دوم، آهنگ پرنده بسیار کمرنگ است. یک ویژگی رایج در ضبطهای منظره صوتی که در آن تماس پرندگان در «پیشزمینه» نیست. وام: ترک کرد: ضبط XC توسط Sue Riffe (مجوز CC-BY-NC). درست: گزیده ای از ضبطی که توسط Kahl، Charif و Klinck در دسترس است. (2022) “مجموعه ای از صداهای ضبط شده با حاشیه نویسی کامل از شمال شرقی ایالات متحده” از مجموعه داده SSW soundscape (مجوز CC-BY). |
مدل های پیشرفته SFDA در شیفت های بیوآکوستیک عملکرد ضعیفی دارند
به عنوان یک نقطه شروع، ما شش روش پیشرفته SFDA را در معیار زیست آکوستیک خود محک زده و آنها را با غیر سازگار خط مبنا (مدل منبع). یافتههای ما شگفتانگیز است: بدون استثنا، روشهای موجود قادر به عملکرد بهتر از مدل منبع در همه حوزههای هدف نیستند. در واقع، آنها اغلب به طور قابل توجهی از آن ضعیف عمل می کنند.
به عنوان مثال، Tent، یک روش جدید، با کاهش عدم قطعیت احتمالات خروجی مدل، قصد دارد مدلها را برای هر مثال پیشبینی مطمئنی تولید کند. در حالی که چادر در کارهای مختلف به خوبی عمل می کند، برای کار بیوآکوستیک ما به طور موثر کار نمی کند. در سناریوی تک برچسب، به حداقل رساندن آنتروپی، مدل را مجبور میکند تا یک کلاس واحد را برای هر مثال با اطمینان انتخاب کند. با این حال، در سناریوی چند برچسبی ما، چنین محدودیتی وجود ندارد که هر کلاسی باید به عنوان موجود انتخاب شود. همراه با جابجایی های قابل توجه توزیع، این می تواند باعث فروپاشی مدل شود که منجر به صفر شدن احتمالات برای همه کلاس ها می شود. سایر روشهای محکشده مانند SHOT، AdaBN، Tent، NRC، DUST و Pseudo-Labelling، که پایههای قوی برای معیارهای استاندارد SFDA هستند، نیز با این وظیفه بیواکوستیک مبارزه میکنند.
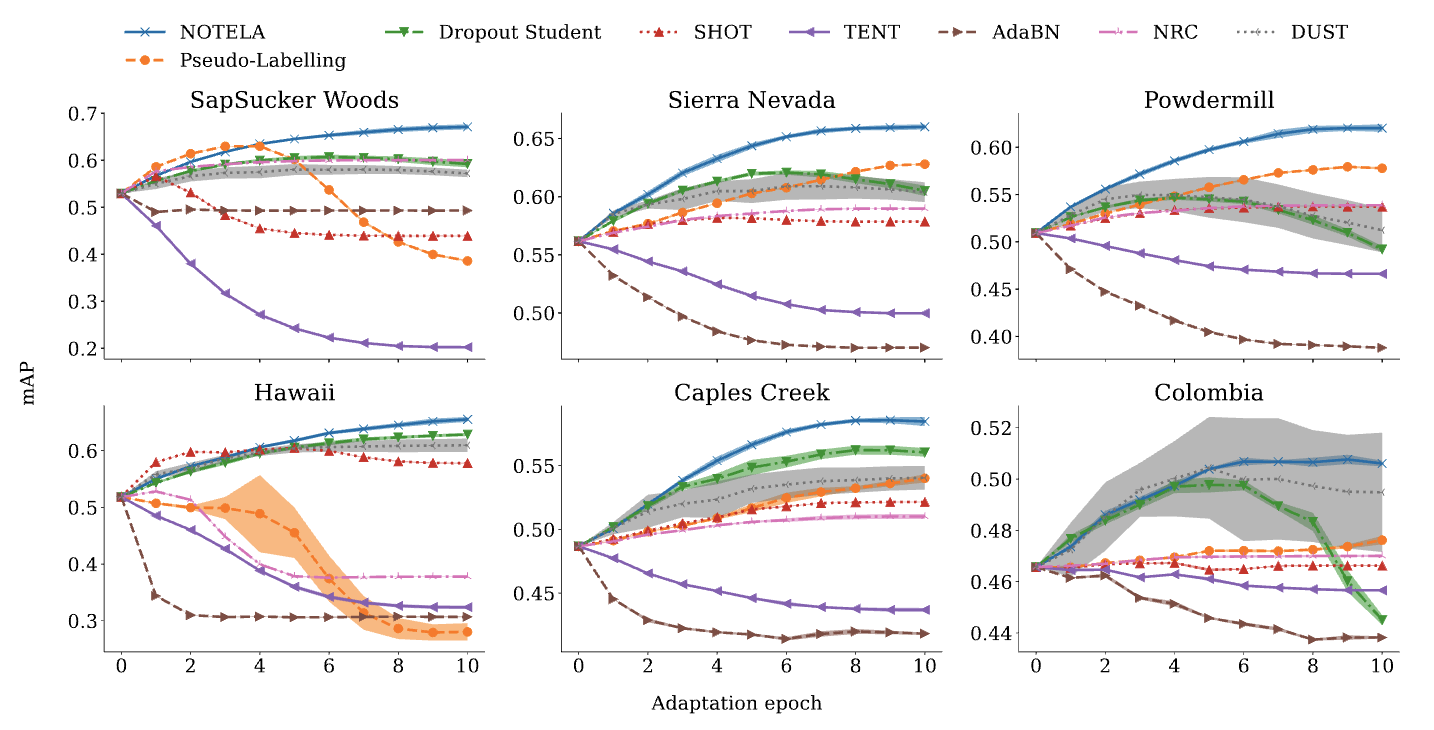 |
| تکامل میانگین دقت میانگین آزمون (mAP)، یک معیار استاندارد برای طبقهبندی چند برچسبی، در سراسر روند انطباق بر روی شش مجموعه داده صدا. ما NOTELA و دانشجوی انصرافی پیشنهادی خود را محک می زنیم (به زیر مراجعه کنید)، و همچنین SHOT، AdaBN، Tent، NRC، DUST و Pseudo-Labeling. به غیر از NOTELA، همه روش های دیگر در بهبود مداوم مدل منبع شکست خورده اند. |
معرفی معلم دانش آموز پر سر و صدا با تنظیم لاپلاسی (NOTELA)
با این وجود، یک نتیجه شگفت آور مثبت برجسته است: اصل دانشجوی پر سر و صدا که کمتر شناخته شده است امیدوارکننده به نظر می رسد. این رویکرد بدون نظارت، مدل را تشویق میکند تا پیشبینیهای خود را بر روی برخی از دادههای هدف، اما تحت استفاده از نویز تصادفی بازسازی کند. در حالی که نویز ممکن است از طریق کانال های مختلف معرفی شود، ما برای سادگی تلاش می کنیم و از حذف مدل به عنوان تنها منبع نویز استفاده می کنیم: بنابراین به این روش به عنوان دانشجوی ترک تحصیل (DS). به طور خلاصه، این مدل را تشویق میکند تا تأثیر نورونها (یا فیلترها) فردی را هنگام پیشبینی روی یک مجموعه داده هدف خاص محدود کند.
DS، در حالی که موثر است، با یک مشکل فروپاشی مدل در حوزه های مختلف هدف مواجه است. ما فرض می کنیم که این اتفاق می افتد زیرا مدل منبع در ابتدا به آن حوزه های هدف اعتماد ندارد. ما بهبود پایداری DS را با استفاده مستقیم از فضای ویژگی به عنوان منبع کمکی حقیقت پیشنهاد می کنیم. NOTELA این کار را با تشویق شبهبرچسبهای مشابه برای نقاط مجاور در فضای ویژگی، با الهام از روش NRC و منظمسازی لاپلاسی انجام میدهد. این رویکرد ساده در زیر تجسم شده است و به طور مداوم و قابل توجهی از مدل منبع در هر دو کار صوتی و تصویری بهتر عمل می کند.
 |
 |
| NOTELA در عمل ضبطهای صوتی از طریق مدل کامل ارسال میشوند تا اولین مجموعه پیشبینیها به دست آید، که سپس از طریق منظمسازی لاپلاسی، نوعی پردازش پسپردازی بر اساس خوشهبندی نقاط نزدیک، پالایش میشوند. در نهایت، پیشبینیهای تصفیهشده بهعنوان اهداف مورد استفاده قرار میگیرند مدل پر سر و صدا برای بازسازی |
نتیجه
معیارهای استاندارد طبقه بندی تصویر مصنوعی به طور ناخواسته درک ما را از تعمیم پذیری و استحکام واقعی روش های SFDA محدود کرده است. ما از گسترش دامنه دفاع می کنیم و یک چارچوب ارزیابی جدید را اتخاذ می کنیم که تغییرات توزیع طبیعی را از آکوستیک زیستی ترکیب می کند. ما همچنین امیدواریم که NOTELA به عنوان یک خط پایه قوی برای تسهیل تحقیقات در این جهت عمل کند. عملکرد قوی NOTELA احتمالاً به دو عامل اشاره می کند که می تواند به توسعه مدل های قابل تعمیم تر منجر شود: اول، توسعه روش هایی با توجه به مشکلات سخت تر و دوم، ترجیح دادن اصول مدل سازی ساده. با این حال، هنوز کار آینده برای مشخص کردن و درک حالت های شکست روش های موجود در مشکلات سخت تر وجود دارد. ما معتقدیم که تحقیقات ما نشان دهنده گامی مهم در این جهت است و به عنوان پایه ای برای طراحی روش های SFDA با قابلیت تعمیم بیشتر عمل می کند.
سپاسگزاریها
یکی از نویسندگان این پست، النی تریانتافیلو، اکنون در گوگل دیپ مایند است. ما این پست وبلاگ را از طرف نویسندگان مقاله NOTELA ارسال می کنیم: مالیک بودیاف، تام دنتون، بارت ون مرینبور، وینسنت دومولن*، النی تریانتافیلو* (که در آن * نشان دهنده مشارکت برابر است). ما از نویسندگان همکارمان برای کار سخت روی این مقاله و بقیه اعضای تیم پرچ برای حمایت و بازخوردشان تشکر می کنیم.
1توجه داشته باشید که در این کلیپ صوتی آواز پرنده بسیار کمرنگ است. یک ویژگی رایج در ضبطهای منظره صوتی که در آن تماس پرندگان در «پیشزمینه» نیست. ↩