
مدلهای انتشار متن به تصویر قابلیتهای استثنایی در تولید تصاویر با کیفیت بالا از پیامهای متنی نشان دادهاند. با این حال، مدل های پیشرو دارای میلیاردها پارامتر هستند و در نتیجه برای اجرا گران هستند و به دسکتاپ یا سرورهای قدرتمندی نیاز دارند (به عنوان مثال، Stable Diffusion، DALL·E، و Imagen). در حالی که پیشرفت های اخیر در راه حل های استنتاج در اندروید از طریق MediaPipe و iOS از طریق Core ML در سال گذشته انجام شده است، تولید سریع متن به تصویر (زیر دوم) در دستگاه های تلفن همراه دور از دسترس باقی مانده است.
برای این منظور، در «MobileDiffusion: دومین تولید متن به تصویر در دستگاههای تلفن همراه»، رویکرد جدیدی را با پتانسیل تولید سریع متن به تصویر روی دستگاه معرفی میکنیم. MobileDiffusion یک مدل انتشار پنهان کارآمد است که به طور خاص برای دستگاه های تلفن همراه طراحی شده است. ما همچنین DiffusionGAN را برای دستیابی به نمونهبرداری یک مرحلهای در طول استنتاج اتخاذ میکنیم، که یک مدل انتشار از پیش آموزشدیده را تنظیم میکند و در عین حال از یک GAN برای مدلسازی مرحله حذف نویز استفاده میکند. ما MobileDiffusion را بر روی دستگاههای پریمیوم iOS و Android آزمایش کردهایم و میتواند در نیم ثانیه اجرا شود تا تصویری با کیفیت 512×512 ایجاد کند. اندازه مدل نسبتا کوچک آن با تنها 520 میلیون پارامتر، آن را به طور منحصر به فردی برای استقرار تلفن همراه مناسب می کند.
 |
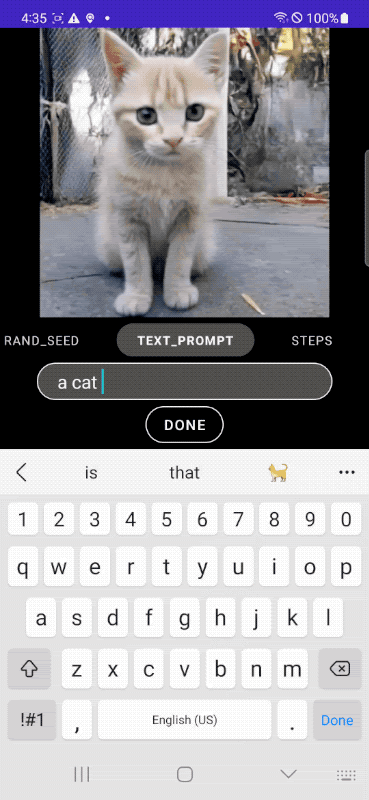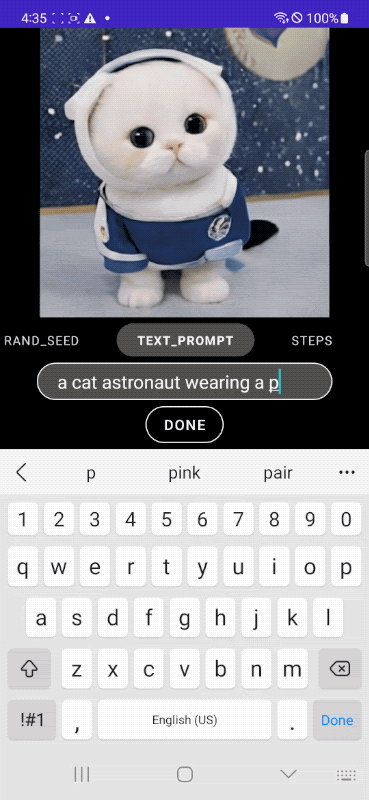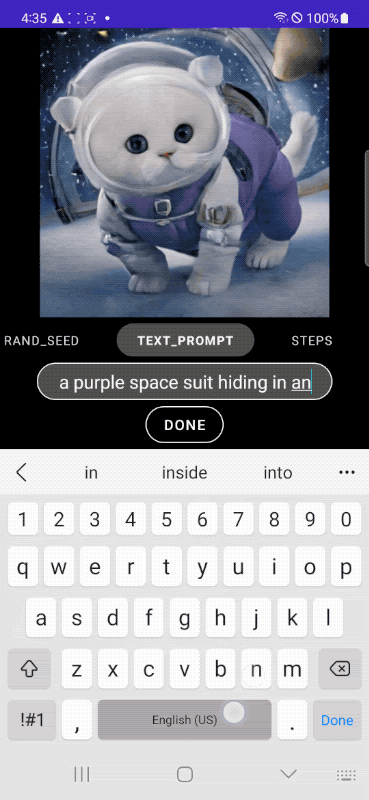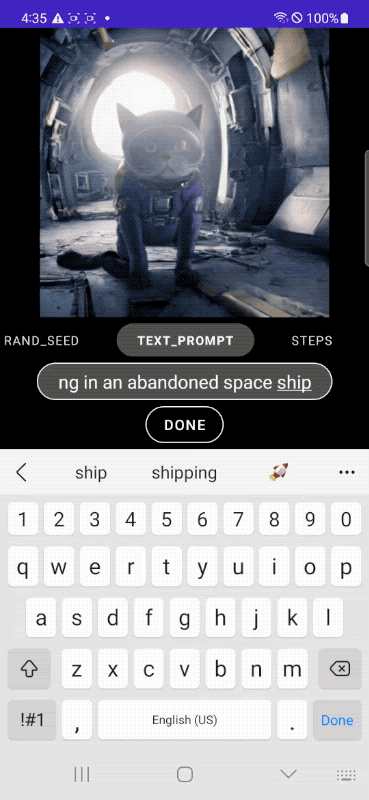 |
| تولید سریع متن به تصویر روی دستگاه. |
زمینه
ناکارآمدی نسبی مدلهای انتشار متن به تصویر از دو چالش اصلی ناشی میشود. اول، طراحی ذاتی مدلهای انتشار نیاز به حذف نویز تکراری برای تولید تصاویر دارد که نیاز به ارزیابیهای متعدد مدل دارد. دوم، پیچیدگی معماری شبکه در مدل های انتشار متن به تصویر شامل تعداد قابل توجهی از پارامترها است که به طور منظم به میلیاردها می رسد و منجر به ارزیابی های محاسباتی گران می شود. در نتیجه، علیرغم مزایای بالقوه استقرار مدلهای تولیدی در دستگاههای تلفن همراه، مانند افزایش تجربه کاربر و رسیدگی به نگرانیهای در حال ظهور حریم خصوصی، در ادبیات کنونی نسبتا ناشناخته باقی مانده است.
بهینه سازی کارایی استنتاج در مدل های انتشار متن به تصویر یک حوزه تحقیقاتی فعال بوده است. مطالعات قبلی عمدتاً بر روی پرداختن به اولین چالش متمرکز بوده و به دنبال کاهش تعداد ارزیابیهای عملکرد (NFE) هستند. با استفاده از حلکنندههای عددی پیشرفته (مثلاً DPM) یا تکنیکهای تقطیر (مثلاً تقطیر تدریجی، تقطیر قوام)، تعداد مراحل نمونهبرداری لازم به طور قابلتوجهی از چند صد به تک رقمی کاهش یافته است. برخی از تکنیکهای اخیر، مانند DiffusionGAN و Adversarial Diffusion Distillation، حتی به یک مرحله ضروری کاهش مییابند.
با این حال، در دستگاه های تلفن همراه، به دلیل پیچیدگی معماری مدل، حتی تعداد کمی از مراحل ارزیابی می تواند کند باشد. تا کنون، کارایی معماری مدل های انتشار متن به تصویر نسبتا کمتر مورد توجه قرار گرفته است. تعدادی از کارهای قبلی به طور مختصر به این موضوع می پردازند که شامل حذف بلوک های شبکه عصبی اضافی (مثلاً SnapFusion) می شود. با این حال، این تلاشها فاقد تجزیه و تحلیل جامع از هر جزء در معماری مدل هستند، در نتیجه در ارائه راهنمای جامع برای طراحی معماریهای بسیار کارآمد کوتاهی میکنند.
Mobile Diffusion
غلبه بر چالشهای تحمیلشده توسط قدرت محاسباتی محدود دستگاههای تلفن همراه، مستلزم کاوش عمیق و جامع در کارایی معماری مدل است. در تعقیب این هدف، تحقیق ما بررسی دقیق هر جزء و عملیات محاسباتی در معماری UNet Stable Diffusion را انجام می دهد. ما یک راهنمای جامع برای ایجاد مدلهای انتشار متن به تصویر بسیار کارآمد ارائه میکنیم که در MobileDiffusion به اوج خود میرسد.
طراحی MobileDiffusion از مدل های انتشار پنهان پیروی می کند. این شامل سه جزء است: یک رمزگذار متن، یک UNet انتشار، و یک رمزگشای تصویر. برای رمزگذار متن از CLIP-ViT/L14 استفاده می کنیم که یک مدل کوچک (125M پارامتر) مناسب برای موبایل است. سپس تمرکز خود را به UNet انتشار و رمزگشای تصویر معطوف می کنیم.
پخش UNet
همانطور که در شکل زیر نشان داده شده است، UNets انتشار معمولاً بلوکهای ترانسفورماتور و بلوکهای پیچشی را به هم میپیوندند. ما یک بررسی جامع از این دو بلوک ساختمانی اساسی انجام می دهیم. در طول مطالعه، ما خط لوله آموزشی (به عنوان مثال، داده، بهینه ساز) را برای مطالعه اثرات معماری های مختلف کنترل می کنیم.
در مدلهای انتشار متن به تصویر کلاسیک، یک بلوک ترانسفورماتور از یک لایه خودتوجه (SA) برای مدلسازی وابستگیهای دوربرد بین ویژگیهای بصری، یک لایه توجه متقابل (CA) برای ثبت تعاملات بین شرطیسازی متن و ویژگیهای بصری تشکیل شده است. و یک لایه فید فوروارد (FF) برای پس پردازش خروجی لایه های توجه. این بلوک های ترانسفورماتور نقش محوری در مدل های انتشار متن به تصویر دارند و به عنوان اجزای اصلی مسئول درک متن هستند. با این حال، آنها همچنین با توجه به هزینه محاسباتی عملیات توجه، که درجه دوم طول دنباله است، چالش کارایی قابل توجهی را ایجاد می کنند. ما از ایده معماری UViT پیروی می کنیم که بلوک های ترانسفورماتور بیشتری را در گلوگاه UNet قرار می دهد. انگیزه این انتخاب طراحی با این واقعیت است که محاسبات توجه به دلیل ابعاد پایینتر، در تنگنا به منابع کمتری نیاز دارد.
 |
| معماری UNet ما از ترانسفورماتورهای بیشتری در وسط استفاده میکند و از لایههای توجه به خود (SA) با وضوح بالاتر عبور میکند. |
بلوک های پیچیدگی، به ویژه بلوک های ResNet، در هر سطح از UNet مستقر هستند. در حالی که این بلوک ها برای استخراج ویژگی و جریان اطلاعات مفید هستند، هزینه های محاسباتی مرتبط، به ویژه در سطوح با وضوح بالا، می تواند قابل توجه باشد. یکی از رویکردهای اثبات شده در این زمینه، پیچیدگی قابل تفکیک است. ما مشاهده کردیم که جایگزینی لایههای پیچشی منظم با لایههای پیچشی قابل جداسازی سبک وزن در بخشهای عمیقتر UNet عملکرد مشابهی را به همراه دارد.
در شکل زیر UNets چند مدل انتشار را با هم مقایسه می کنیم. MobileDiffusion ما از نظر FLOP (عملیات ممیز شناور) و تعداد پارامترها کارایی برتری را نشان می دهد.
 |
| مقایسه برخی از یونیت های انتشار. |
رمزگشای تصویر
علاوه بر UNet، رمزگشای تصویر را نیز بهینه کردیم. ما یک رمزگذار خودکار متغیر (VAE) را آموزش دادیم تا یک تصویر RGB را به یک متغیر نهفته 8 کانالی با اندازه فضایی 8× کوچکتر رمزگذاری کند. یک متغیر پنهان را می توان در یک تصویر رمزگشایی کرد و اندازه آن 8× بزرگتر می شود. برای افزایش بیشتر کارایی، ما یک معماری رمزگشای سبک وزن را با هرس کردن عرض و عمق اصلی طراحی میکنیم. رمزگشای سبک وزن منجر به افزایش عملکرد قابل توجهی با نزدیک به 50٪ بهبود تاخیر و کیفیت بهتر می شود. برای جزئیات بیشتر، لطفاً به مقاله ما مراجعه کنید.
 |
| بازسازی VAE. رسیورهای VAE ما کیفیت بصری بهتری نسبت به SD (Stable Diffusion) دارند. |
| رمزگشا | #پارامز (M) | PSNR↑ | SSIM↑ | LPIPS↓ |
| SD | 49.5 | 26.7 | 0.76 | 0.037 |
| مال ما | 39.3 | 30.0 | 0.83 | 0.032 |
| ما – Lite | 9.8 | 30.2 | 0.84 | 0.032 |
نمونه گیری یک مرحله ای
علاوه بر بهینه سازی معماری مدل، ما یک ترکیبی DiffusionGAN را برای دستیابی به نمونه برداری یک مرحله ای اتخاذ می کنیم. آموزش مدلهای ترکیبی DiffusionGAN برای تولید متن به تصویر با پیچیدگیهای متعددی روبرو میشود. قابل ذکر است، تمایزکننده، طبقهبندیکنندهای که دادههای واقعی و دادههای تولید شده را متمایز میکند، باید بر اساس بافت و معنایی قضاوت کند. علاوه بر این، هزینه آموزش مدلهای متن به تصویر میتواند بسیار بالا باشد، به ویژه در مورد مدلهای مبتنی بر GAN، که در آن تمایزکننده پارامترهای اضافی را معرفی میکند. مدلهای متن به تصویر مبتنی بر GAN (مانند StyleGAN-T، GigaGAN) با پیچیدگیهای مشابهی روبرو هستند که در نتیجه آموزش بسیار پیچیده و پرهزینه ای به همراه دارد.
برای غلبه بر این چالشها، از یک UNet انتشار از پیش آموزشدیده برای مقداردهی اولیه مولد و تفکیککننده استفاده میکنیم. این طراحی، مقدار دهی اولیه بدون درز را با مدل انتشار از پیش آموزش دیده امکان پذیر می کند. ما فرض می کنیم که ویژگی های داخلی در مدل انتشار حاوی اطلاعات غنی از تعامل پیچیده بین داده های متنی و بصری است. این استراتژی اولیه به طور قابل توجهی آموزش را ساده می کند.
شکل زیر روند آموزش را نشان می دهد. پس از مقداردهی اولیه، یک تصویر نویزدار برای انتشار یک مرحله ای به ژنراتور ارسال می شود. نتیجه در برابر حقیقت زمین با از دست دادن بازسازی، مشابه آموزش مدل انتشار، ارزیابی میشود. سپس نویز را به خروجی اضافه میکنیم و آن را به تفکیککننده میفرستیم، که نتیجه آن با از دست دادن GAN ارزیابی میشود، و به طور موثر GAN را برای مدلسازی مرحله حذف نویز اتخاذ میکنیم. با استفاده از وزنه های از پیش آموزش داده شده برای مقداردهی اولیه مولد و تفکیک کننده، آموزش به یک فرآیند تنظیم دقیق تبدیل می شود که در کمتر از 10K تکرار همگرا می شود.
 |
| تصویر تنظیم دقیق DiffusionGAN. |
نتایج
در زیر تصاویر نمونه تولید شده توسط MobileDiffusion ما با نمونهبرداری یک مرحلهای DiffusionGAN را نشان میدهیم. با چنین مدل جمع و جور (در مجموع 520 میلیون پارامتر)، MobileDiffusion می تواند تصاویر متنوع با کیفیت بالا را برای دامنه های مختلف تولید کند.
 |
| تصاویر تولید شده توسط MobileDiffusion ما |
ما عملکرد MobileDiffusion خود را در دستگاههای iOS و Android با استفاده از بهینهسازهای زمان اجرا مختلف اندازهگیری کردیم. اعداد تاخیر در زیر گزارش شده است. می بینیم که MobileDiffusion بسیار کارآمد است و می تواند در عرض نیم ثانیه اجرا شود و یک تصویر 512×512 ایجاد کند. این سرعت رعد و برق به طور بالقوه بسیاری از موارد استفاده جالب را در دستگاه های تلفن همراه امکان پذیر می کند.
 |
| اندازه گیری تاخیر (س) در دستگاه های تلفن همراه. |
نتیجه
MobileDiffusion با بهره وری برتر از نظر تأخیر و اندازه، این پتانسیل را دارد که گزینه بسیار دوستانه ای برای استقرار تلفن همراه باشد، با توجه به توانایی آن برای ایجاد تجربه تولید سریع تصویر در حین تایپ پیام های متنی. و ما مطمئن خواهیم شد که هر گونه کاربرد این فناوری مطابق با شیوههای هوش مصنوعی مسئول Google خواهد بود.
قدردانی
مایلیم از همکاران و همکاران خود که به ارائه MobileDiffusion به روی دستگاه کمک کردند تشکر کنیم: Zhisheng Xiao، Yanwu Xu، Jiuqiang Tang، Haolin Jia، Lutz Justen، Daniel Fenner، Ronald Wotzlaw، Jianing Wei، Raman Sarokin، Juhyun Lee، Andrei Kulik، چو لینگ چانگ و ماتیاس گروندمن.