رگرسیون خطی در یادگیری ماشین یک رویکرد یادگیری نظارت شده است که در آن برنامه های کامپیوتری سعی می کنند روی متغیرهای پیوسته پیش بینی کنند.
به بیان ساده، هدف الگوریتم رگرسیون خطی ترسیم بهترین خط (یا منحنی) بین متغیرهای وابسته (هدف) و مستقل (ویژگی/پیشبینیکننده) است.
رگرسیون خطی چیست؟
رگرسیون خطی از یک خط مستقیم برای مقایسه رابطه بین دو متغیر استفاده می کند. انواع دیگر رگرسیون ها مانند مدل های رگرسیون لجستیک از خط منحنی استفاده می کنند.
هدف از رگرسیون خطی این است که یک خط را در یک نمودار پراکنده از دو متغیر پیوسته قرار دهیم به گونه ای که نقاط داده به طور جمعی تا حد امکان به خط نزدیک شوند.
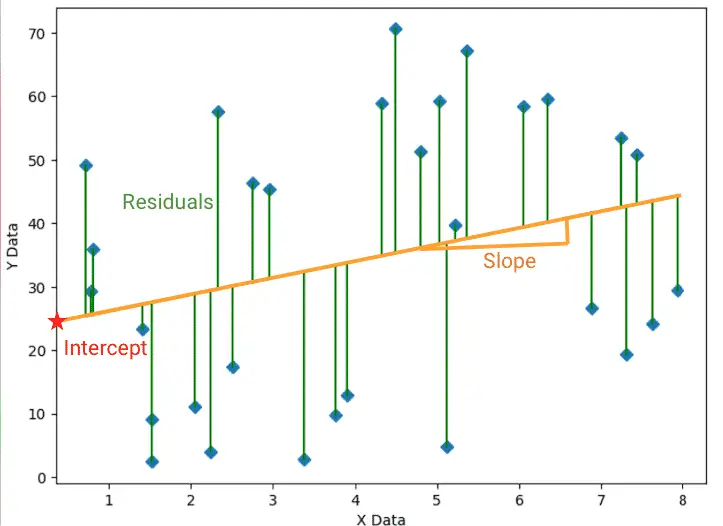
رگرسیون خطی یکی از چندین مدل رگرسیون مورد استفاده در یادگیری ماشین است.
انواع رگرسیون خطی
- رگرسیون خطی ساده
- رگرسیون خطی چندگانه
رگرسیون خطی ساده
را رگرسیون خطی ساده با استفاده از روش حداقل مربعات معمولی (OLS) تخمین زده می شود.
دارای یک متغیر وابسته و یک متغیر مستقل است و می توان از آن برای تخمین رابطه بین این دو متغیر استفاده کرد.
چه زمانی از رگرسیون خطی ساده استفاده کنیم؟
- مشخص کنید که این دو متغیر چقدر به هم مرتبط هستند. (مثلاً فروش بستنی و دما).
- زمانی که متغیر مستقل تغییر می کند، مقدار متغیر وابسته را پیش بینی کنید. (مثلا تعداد فروش بستنی در دمای معین).
فرمول مدل رگرسیون خطی ساده
فرمول مدل رگرسیون خطی ساده به این صورت است.
? = β₀ + β₁?₁ + ε?متغیر وابسته/هدف است که ما سعی در پیش بینی آن داریم.?یک متغیر مستقل است.- β1 ضریبی است که اثر ?1 را بر روی ? تعیین می کند.
- β0 نقطه قطع خط رگرسیون است
- ε (epsilon) خطا است
یا رایج ترین عبارت:
y = aX + byمختصات متغیر وابسته است (همچنین به عنوان متغیر پاسخ یا هدف نیز شناخته می شود)xمختصات متغیر مستقل استaشیب خط استbرهگیری که در آن استxملاقات می کندy
رگرسیون خطی ساده یک طرفه است
برای اینکه رگرسیون خطی ساده کار کند:
- باید یک متغیر وابسته (X) و یک متغیر مستقل (Y) وجود داشته باشد.
- باید یک متغیر مستقل وجود داشته باشد.
- Y باید به X وابسته باشد.
- X نمی تواند به Y وابسته باشد.
می توان گفت که فروش قیفی بستنی (Y) تحت تأثیر دمای بیرون (x) است.
با این حال، گفتن اینکه دمای بیرون (Y) تحت تأثیر تعداد بسته های بستنی فروخته شده (X) است، یک فرض اشتباه است. در این صورت، فرمول کار نمی کند. این به این دلیل است که طبیعت مادر به توانایی بن و جری برای تبلیغ محصولات خود وابسته نیست.
هنگامی که از دو یا چند متغیر مستقل در تحلیل رگرسیون استفاده می شود، مدل دیگر یک مدل خطی ساده نیست. این به عنوان رگرسیون چندگانه شناخته می شود.
رگرسیون خطی چندگانه
رگرسیون خطی چندگانه مشابه مدل رگرسیون خطی ساده است اما دارای چندین متغیر مستقل است که به متغیر وابسته کمک می کنند.
رگرسیون خطی چندگانه با رگرسیون خطی چند متغیره که در آن چندین متغیر وابسته همبسته پیشبینی میشود، یکسان نیست، نه یک متغیر اسکالر.
- چندگانه رگرسیون خطی:
yاسکالر است. - چند متغیره رگرسیون خطی:
yیک بردار است.
فرمول رگرسیون خطی چندگانه
با داشتن چندین متغیر مستقل، ضرایب متعددی به تابع خطی اضافه میشود تا هر متغیر مستقل را متناسب کند.
y = β₀ + β1?1 + β2?2 + … + βnXn + ε- Y متغیر وابسته / متغیر هدف است
- β0 وقفه خط رگرسیون است
- β1، β2، … βn شیب خطوط رگرسیون هر ویژگی است
- X1، X2، ….Xn متغیرهای مستقل / ویژگی هستند
- ε (epsilon) خطا است
یک رگرسیون خطی در پایتون ایجاد کنید
رگرسیون خطی ساده با استفاده از make_regression
ایجاد یک رگرسیون خطی ساده در پایتون با استفاده از Scikit-learn و seaborn بسیار آسان است. regplot.
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import make_regression
sns.set()
X, y = make_regression(n_samples=200, n_features=1, n_targets=1, noise=30, random_state=0)
sns.regplot(x=X, y=y)
plt.title('Simple Linear Regression', fontsize=20)
plt.show()

رگرسیون خطی ساده را بر روی داده های دنیای واقعی ترسیم کنید
شما همچنین می توانید رگرسیون خطی را روی یک مجموعه داده واقعی مانند مجموعه داده دیابت انجام دهید.
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
from sklearn.datasets import load_diabetes
sns.set()
X, y = load_diabetes(return_X_y=True, as_frame=True)
X = X[['bmi']]
sns.regplot(x=X, y=y)
plt.title('Simple Linear Regression on Diabetes', fontsize=20)
plt.show()

یک مدل رگرسیون خطی بسازید
اکنون با استفاده از Scikit-learn میتوانیم یک مدل رگرسیون خطی ایجاد کنیم تا بر اساس متغیرهای ویژگی ورودی، متغیر هدف را پیشبینی کنیم.
ما از ماژول متریک Scikit-learn برای ارزیابی عملکرد مدل استفاده خواهیم کرد.
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn import metrics
X, y = load_diabetes(return_X_y=True, as_frame=True)
X = X[['bmi']]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
lin_reg = LinearRegression()
lin_reg.fit(X_train, y_train)
y_pred = lin_reg.predict(X_test)
print('Intercept:', lin_reg.intercept_)
print('Coefficients:', lin_reg.coef_)
print('Mean absolute error:', metrics.mean_absolute_error(y_test, y_pred))
print('Mean squared error:', metrics.mean_squared_error(y_test, y_pred))
print('Coefficient of determination (r2 Score):', metrics.r2_score(y_test, y_pred))
نتیجه پیش بینی چیزی شبیه به این خواهد بود.
Intercept: 153.4350903922729
Coefficients: [1013.17358257]
Mean absolute error: 51.340840560752476
Mean squared error: 3921.3720274248517
Coefficient of determination (r2 Score): 0.23132831307953805
رگرسیون خطی چندگانه انجام دهید
ایجاد یک رگرسیون خطی چندگانه شامل مراحلی مشابه با ایجاد یک رگرسیون خطی ساده است.
تفاوت در ارزیابی است.
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn import metrics
sns.set()
X, y = load_diabetes(return_X_y=True, as_frame=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
lin_reg = LinearRegression()
lin_reg.fit(X_train, y_train)
y_pred = lin_reg.predict(X_test)
coef_df = pd.DataFrame(lin_reg.coef_, X.columns, columns=['Coefficient'])
coef_df.plot(kind='barh')
plt.title('Feature importance of linear regression')
plt.show()
هر ویژگی سطح متفاوتی از تأثیر بر مقادیر پیش بینی شده خواهد داشت. برخی بیشتر تأثیر خواهند گذاشت، برخی کمتر تأثیر خواهند گذاشت.

در یک رگرسیون خطی ساده، یک نوار روی نمودار ضریب وجود خواهد داشت.
نمرات ارزیابی رگرسیون خطی را درک کنید
میانگین خطای مطلق (MAE)
تفاوت مطلق بین داده ها و پیش بینی های مدل
MAE = مقادیر واقعی – مقادیر پیش بینی شده.
میانگین مربعات خطا (MSE)
مربع تفاوت بین داده ها و پیش بینی های مدل.
مشکل میانگین خطای مطلق این است که تفاوت منفی تفاوت های مثبت را خنثی می کند.
مربع کردن این مقادیر احساس اهمیت خطا را ارائه می دهد.
مثلا:
(real_value_1 - pred_value_1) + (real_value_2 - pred_value_2)
MAE = (3 - 5) + (7 - 4) = -2 + 3 = 1
MSE = (3 - 5)^2 + (7 - 4)^2 = -2^2 + 3^2 = 4 + 9 = 13
ضریب تعیین (امتیاز r2)
امتیاز r^2 کیفیت توضیحی را که می توانید از یک مدل دریافت کنید اندازه گیری می کند. هر چه فاکتورهای بیشتری را در نظر بگیرید، r-squared بالاتر خواهد بود.
- SSR: مجموع مربعات خطاهای باقیمانده.
- SST: مجموع کل خطاها.
r-squared اندازه گیری نسبت به تنوع کل است. مقادیری از 0 تا 1 را می گیرد.
- وقتی R^2 = 0، رگرسیون هیچ یک از متغیرهای داده ها را توضیح نمی دهد.
- هنگامی که r^2 = 1، رگرسیون همه تنوع داده ها را توضیح می دهد.

کار جالب در جامعه
نتیجه
مشاهده کردیم که رگرسیون خطی یک رویکرد تحلیل آماری برای مدلسازی رابطه بین متغیرهای وابسته و مستقل است.
ما همچنین آموختیم که رگرسیون خطی انجام شده بر روی یک متغیر توضیحی (مستقل) منفرد، رگرسیون خطی ساده نامیده می شود. آنهایی که بر روی چندین متغیر مستقل انجام میشوند، رگرسیون خطی چندگانه نامیده میشوند.
برای درک بیشتر خود، با خیال راحت روش های تخمین رگرسیون خطی را مطالعه کنید.

استراتژیست سئو در Tripadvisor، Seek سابق (ملبورن، استرالیا). متخصص در سئو فنی. در تلاش برای سئوی برنامهریزی شده برای سازمانهای بزرگ از طریق استفاده از پایتون، R و یادگیری ماشین.