k-Nearest Neighbors یک الگوریتم یادگیری ماشینی است که در یادگیری نظارت شده برای پیشبینی برچسب نقاط داده با مشاهده اکثریت در نزدیکترین همسایهها استفاده میشود.
این یک رویکرد طبقه بندی است.
با توجه به تعدادی از همسایگان k، الگوریتم k-نزدیکترین همسایه به آنچه در اکثریت وجود دارد نگاه می کند و اکثریت را به نقاط داده جدید نسبت می دهد.
k-نزدیکترین همسایه ها را بیاموزید
این پست مروری بر الگوریتم k-Nearest Neighbors است و به هیچ وجه کامل نیست.
اگر میخواهید درباره الگوریتمهای k-Nearest Neighbors اطلاعات بیشتری کسب کنید، در اینجا چند آموزش Datacamp وجود دارد که به من کمک کرد.
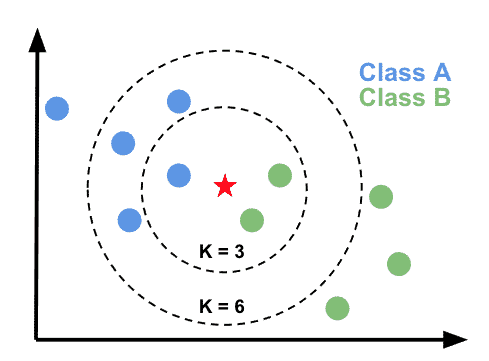
الگوریتم k-Nearest Neighbors را به صورت بصری درک کنید
این تجسم به درک نحوه عملکرد k-Nearest Neighbors کمک می کند. با توجه به الف k ارزش، پیش بینی چیست؟
- در
k=3دایره،greenاکثریت است، نقاط داده جدید به عنوان پیش بینی خواهد شدgreen; - در
k=6دایره،blueاکثریت است، نقاط داده جدید به عنوان پیش بینی خواهد شدblue;

مزایا و معایب رویکرد KNN
مزایای: الگوریتم k-Nearest Neighbors برای پیاده سازی ساده و داده های آموزشی پر سر و صدا است.
معایب: هزینه محاسبات بالا در مقایسه با الگوریتم های دیگر. ذخیره سازی داده ها: مبتنی بر حافظه، بنابراین کارایی کمتری دارد. باید تعریف کرد کدام k ارزش استفاده
چه زمانی از الگوریتم KNN استفاده کنیم؟
- تشخیص تصویر و ویدئو
- فیلتر کردن سیستم های توصیه گر
k-Nearest Neighbors را با Scikit-learn اجرا کنید
بیایید الگوریتم k-Nearest Neighbors را با Scikit-learn اجرا کنیم.
- بارگذاری داده ها
- داده ها را به مجموعه های آموزشی و آزمایشی تقسیم کنید
- مدل طبقه بندی کننده را در مجموعه آموزشی آموزش دهید و روی مجموعه آزمایشی پیش بینی کنید
- مدل را با نگاه کردن به برچسب های شناخته شده ارزیابی کنید.
- مدل را دقیق تنظیم کنید
بارگذاری داده ها
Sklearn مجموعه ای از مجموعه داده های داخلی دارد که می توانیم از آنها استفاده کنیم. در اینجا ما مجموعه داده سرطان سینه را بارگذاری می کنیم.
import pandas as pd
from sklearn import datasets
dataset = datasets.load_breast_cancer()
df = pd.DataFrame(dataset.data,columns=dataset.feature_names)
df['target'] = pd.Series(dataset.target)
df.head()

بیایید به برچسب هایی نگاه کنیم که سعی خواهیم کرد پیش بینی کنیم.
بر اساس تمام ویژگی هایی که ما داریم:
print(dataset.feature_names)
# [
# 'mean radius',
# 'mean texture',
# 'mean perimeter',
# ...,
# 'worst fractal dimension'
# ]
ما سعی خواهیم کرد شدت سرطان سینه را پیش بینی کنیم.
print(dataset.target_names)
# ['malignant', 'benign']
داده ها را به مجموعه های آموزشی و آزمایشی تقسیم کنید
هر زمان که یک مدل یادگیری ماشین می سازیم، می خواهیم دقت آن را بررسی کنیم.
شما باید داده های خود را به دو قسمت تقسیم کنید مجموعه داده های آموزشی و آزمایشی با استفاده از train_test_split مدول.
- مجموعه داده آموزشی برای جا دادن (یا آموزش) مدل استفاده می شود.
- مجموعه داده آزمایشی از آموزش حذف می شود. داده های برچسب گذاری شده ای است که برای مقایسه با پیش بینی های انجام شده توسط مدل استفاده می شود.
from sklearn.model_selection import train_test_split
# Define independent (features) and dependent (targets) variables
X = dataset['data']
y = dataset['target']
# split taining and test set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42, stratify=y)
مدل را آموزش دهید و پیش بینی کنید
حال، برای پیشبینی بر اساس دادههای برچسبگذاری شده، این کار را انجام میدهیم:
- را آغاز کنید
KNeighborsClassifierمدل یادگیری ماشینی - استفاده کنید
.fit()روش برای آموزش حالت - استفاده کنید
.predict()روشی برای پیش بینی
from sklearn.neighbors import KNeighborsClassifier
# train the model
knn = KNeighborsClassifier(n_neighbors=8)
knn.fit(X_train, y_train)
y_pred = knn.predict(X_test)
مدل را ارزیابی کنید
ارزیابی دقت مدل بسیار مهم است. ما می توانیم این کار را با استفاده از .score() روش بر روی knn هدف – شی.
# compute accuracy of the model
knn.score(X_test, y_test)
دقت مدل است
که در این مورد نتیجه بسیار خوبی است.
مقادیر K مختلف را تست کنید
همچنین میتوانیم به دقت مدل چندگانه نگاه کنیم k ارزش های.
import numpy as np
import matplotlib.pyplot as plt
neighbors = np.arange(1, 25)
accuracy = np.empty(len(neighbors))
for i, k in enumerate(neighbors):
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(X_train, y_train)
accuracy[i] = knn.score(X_test, y_test)
plt.title('k-NN accuracy by number of Neighbors')
plt.plot(neighbors, accuracy)
plt.xlabel('Number of Neighbors')
plt.ylabel('Accuracy')
plt.show()

در اینجا می بینیم که با افزایش دقت مدل شروع به کاهش می کند k ارزش.
بهترین مقدار K را برای مدل انتخاب کنید
انتخاب بهترین هایپرپارامتر برای انتخاب بهترین مدل حیاتی است.
طرح بالا عالی است، اما باید انتخاب کنید 8 یا 13، یا حتی بزرگتر n_neighbors ارزش های؟
استفاده كردن GridSearchCV از model_selection ماژول، می توانید بهترین پارامتر را برای مدل خود بررسی کنید.
import numpy as np
from sklearn.model_selection import GridSearchCV
param_grid = {'n_neighbors':np.arange(1, 50)}
knn_cv = GridSearchCV(knn, param_grid, cv=5)
knn_cv.fit(X_train, y_train)
print(knn_cv.best_params_)
print(knn_cv.best_score_)
نتیجه به شما می گوید کدام k ارزشی که باید در نظر بگیرید تا بهترین تناسب با داده های شما داشته باشد. در این صورت باید تنظیم کنید n_neighbors بودن 13.
{'n_neighbors': 6}
0.9498417721518987
ماتریس سردرگمی را بررسی کنید
این امکان وجود دارد که دقت به طور کامل نماینده نباشد. اکنون سعی خواهیم کرد ببینیم چند پیشبینی درست و چند پیشبینی نادرست است.
ما این کار را با استفاده از:
یادآوری سریع، در توطئه های آینده ما اهداف را ترسیم خواهیم کرد (0شن 1s) و نه نام های هدف. به یاد بیاور:
ماتریس سردرگمی
برای رسم ماتریس سردرگمی، از confusion_matrix و plot_confusion_matrix روش های از sklearn.metrics مدول.
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix, plot_confusion_matrix
cm = confusion_matrix(y_test,y_pred)
print(cm)
color = 'white'
matrix = plot_confusion_matrix(knn, X_test, y_test, cmap=plt.cm.Blues)
matrix.ax_.set_title('Confusion Matrix', color=color)
plt.xlabel('Predicted Label', color=color)
plt.ylabel('True Label', color=color)
plt.gcf().axes[0].tick_params(colors=color)
plt.gcf().axes[1].tick_params(colors=color)
plt.show()

اگر نمی دانید چگونه این را تفسیر کنید، فقط پست من در مورد ماتریس سردرگمی را بخوانید.
گزارش طبقه بندی
بیایید گزارش طبقه بندی را برای ارزیابی کیفیت پیش بینی ها محاسبه کنیم.
from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred))

اگر نمی دانید چگونه این را تفسیر کنید، فقط پست من در گزارش طبقه بندی را بخوانید.
نتیجه
این پروژه در حال حاضر انجام شده است. ما دقت الگوریتم k-Nearest Neighbors خود را در Scikit-learn پیاده سازی و بررسی کرده ایم.

استراتژیست سئو در Tripadvisor، Seek سابق (ملبورن، استرالیا). متخصص در سئو فنی. در تلاش برای سئوی برنامهریزی شده برای سازمانهای بزرگ از طریق استفاده از پایتون، R و یادگیری ماشین.