درختهای تصمیم، مدلهای یادگیری ماشینی پیشبینیکننده هستند که از قوانین باینری ساده برای پیشبینی مقدار یک متغیر هدف استفاده میکنند.
درخت تصمیم چیست؟
آ درخت تصمیم یک ساختار داده متشکل از سلسله مراتبی از گره ها است که می تواند برای یادگیری نظارت شده و مشکلات یادگیری بدون نظارت (طبقه بندی، رگرسیون، خوشه بندی، …) استفاده شود.
درختان تصمیم از الگوریتم های مختلفی برای تقسیم یک مجموعه داده به گره های فرعی همگن (یا خالص) استفاده می کنند.
مزایای درخت تصمیم
الگوریتم های درخت تصمیم دارای مزایای متعددی هستند:
- درک و تفسیر ساده است
- انعطاف پذیر هستند زیرا می توانند داده های غیر خطی را توصیف کنند
- ساده برای استفاده به عنوان بدون نیاز به پیش پردازش داده.
از سوی دیگر، درختان دارای معایبی هستند:
- به تغییرات کوچک در داده های آموزشی حساس است
- مستعد برازش بیش از حد در صورت عدم محدودیت
درک الگوریتم درخت تصمیم
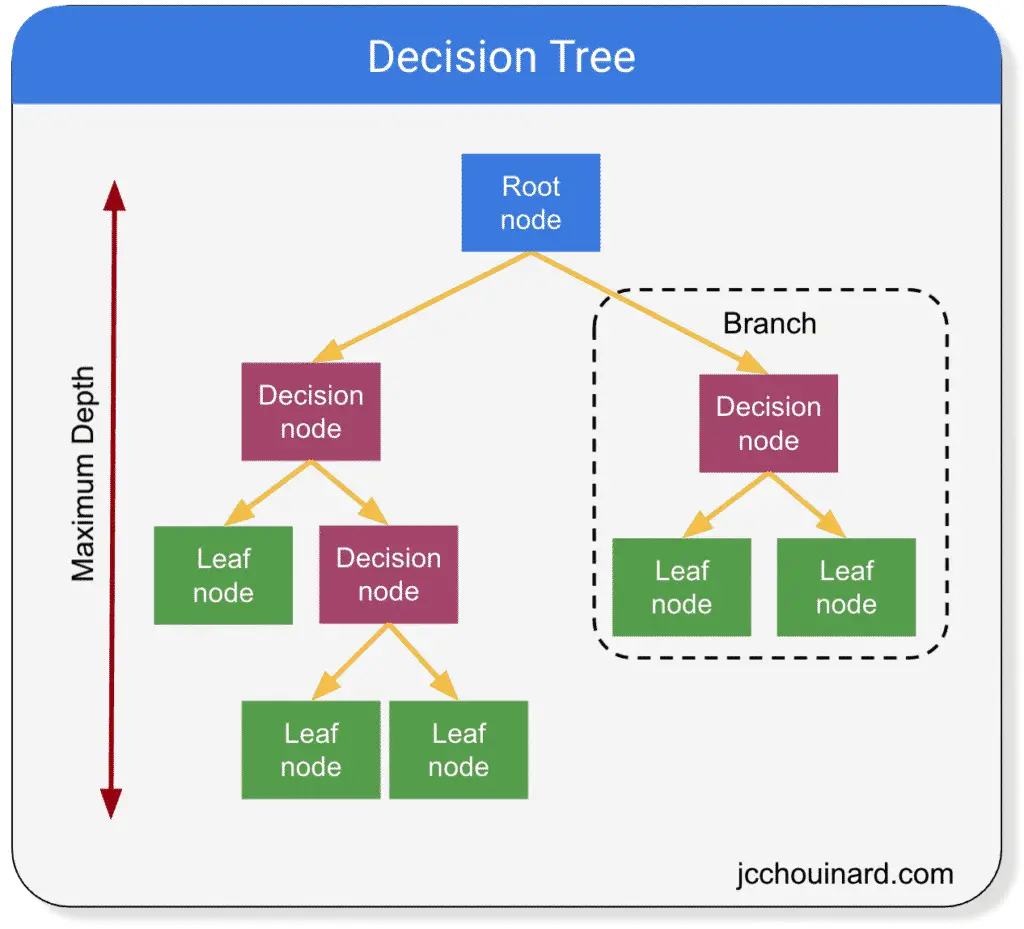
درختان تصمیم مدل های ساده ای هستند که دارند شاخه ها، گره ها و برگها و یک مجموعه داده را به زیرمجموعه های کوچکتر که حاوی نمونه هایی با مقادیر مشابه هستند تقسیم کنید.

تعاریف درخت تصمیم
- گره ریشه: اولین گره در مسیری که ابتدا همه تصمیمات از آن شروع شده اند. هیچ گره والد و 2 گره فرزند ندارد
- گره های تصمیم گیری: گره هایی که 1 گره والد دارند و به گره های فرزند (گره تصمیم یا برگ) تقسیم می شوند.
- گره های برگ: گره هایی که 1 والد دارند، اما بیشتر تقسیم نمی شوند (به عنوان گره های پایانه نیز شناخته می شوند). آنها گره هایی هستند که پیش بینی را تولید می کنند.
- شاخه ها: زیربخشی از کل درخت (همچنین به عنوان درخت فرعی نیز شناخته می شود)
- گره های والد/فرزند: گره ای که به گره های فرعی تقسیم می شود، گره والد نامیده می شود. گره های فرعی گره های فرزند والد هستند که از آنها تقسیم شده اند.
- حداکثر عمق: حداکثر تعداد انشعابات بین بالا و انتهای پایین
انواع الگوریتم درخت تصمیم
چندین الگوریتم درخت تصمیم وجود دارد:
- ID3 (تکرار کننده Dichotomiser 3)
- C4.5 (پسوند ID3)
- سبد خرید (درخت طبقه بندی و رگرسیون)
- Chi-square (تشخیص تعامل خودکار Chi-square)
- مریخ (Splines رگرسیون تطبیقی چند متغیره)
2 درخت تصمیم وجود دارد که در زیر گروه بندی شده اند درخت طبقه بندی و تصمیم گیری (CART).
- درخت تصمیم طبقه بندی (برای داده های طبقه بندی استفاده می شود)
- درخت تصمیم رگرسیون (برای داده های پیوسته استفاده می شود)
برخی از تکنیک ها از بیش از یک درخت تصمیم استفاده می کنند. آنها را الگوریتم های یادگیری گروهی می نامند.
متریک درخت تصمیم
درختان تصمیم سعی می کنند خالص ترین برگ ها را به روش بازگشتی با تقسیم گره ها به گره های فرعی کوچکتر تولید کنند.
اما چگونه نحوه تقسیم گره ها، ارزیابی خلوص برگ یا تصمیم گیری در مورد زمان توقف را انتخاب می کند؟
- اندازه گیری کیفیت یک تقسیم: جینی یا آنتروپی
- با ویژگی و کدام نقطه تقسیم را مشخص کنید: افزایش اطلاعات (IG)، کاهش واریانس
برای مشکلات طبقه بندی درخت تصمیم در متغیرهای طبقه بندی:
- آنتروپی و افزایش اطلاعات (IG)
- ناخالصی جینی
برای مشکلات رگرسیون درخت تصمیم در متغیرهای پیوسته:
افزایش اطلاعات (IG)
برای تولید “بهترین” نتیجه، هدف درختان تصمیم به حداکثر رساندن سود اطلاعات (IG) پس از هر تقسیم است.
به دست آوردن اطلاعات یک گره با کم کردن آنتروپی به 1 محاسبه می شود.

به دست آوردن اطلاعات کمک می کند تا مشخص شود که آیا تقسیم شده است یا خیر شامل گره های خالص بیشتری در مقایسه با گره والد است.
برای اندازه گیری سود اطلاعاتی والدین در برابر فرزندانش، باید آنتروپی وزنی فرزندان را از آنتروپی والدین کم کنیم.

اما، آنتروپی چیست؟
آنتروپی
آنتروپی برای اندازه گیری کیفیت یک تقسیم استفاده می شود اهداف طبقه بندی شده.
فرمول آنتروپی در درخت های تصمیم به صورت زیر است:

جایی که pi نشان دهنده درصد کلاس در گره است.
در زیر نمایشی از محاسبه آنتروپی در یک مجموعه داده است که در آن 2 مقدار در کلاس تقسیم شده در 30٪ -70٪ وجود دارد.

هر چه آنتروپی کوچکتر باشد، همگنی گره ها بیشتر می شود.

برای محاسبه آنتروپی یک تقسیم، ما:
- آنتروپی گره والد را محاسبه کنید
- آنتروپی گره های فرزند را محاسبه کنید
- میانگین وزنی آنتروپی تقسیم را محاسبه کنید

اگر آنتروپی وزنی کوچکتر از آنتروپی گره والد باشد، در این صورت سود اطلاعات بیشتر است.
در بالا، آنتروپی والد برابر است 1 و آنتروپی وزنی برابر است 1.09.
بنابراین، در فرمول:
سود اطلاعات برابر است با:
تفسیر به دست آوردن اطلاعات
تقسیمی مانند آنچه در بالا وجود دارد، آنتروپی را کاهش می دهد.
درخت تصمیم تلاش می کند تا سود اطلاعات را به حداکثر برساند.
بنابراین، تقسیم انجام نمی شود.
ناخالصی جینی
ناخالصی جینی به عنوان جایگزینی برای به دست آوردن اطلاعات (IG) برای محاسبه همگنی یک برگ به روشی کمتر محاسباتی استفاده می شود.
هر چه یک گره خالص تر یا همگن باشد، ناخالصی جینی کوچکتر است.
نحوه عملکرد ناخالصی جینی به شرح زیر است:
- انتخاب عناصر به صورت تصادفی و نسبت دادن همان کلاس
- محاسبه احتمال نادرستی طبقه بندی یک عنصر به طور تصادفی انتخاب شده
جینی مجموع مجذورات احتمالات برای هر کلاس است.

و سپس، دوباره، مدل خلوص تقسیم را با محاسبه وزن ناخالصی جینی هر دو برگ فرزند در مقایسه با ناخالصی جینی والد تخمین میزند.

کاهش واریانس
کاهش واریانسیا میانگین مربعات خطا، تکنیکی است که برای تخمین خلوص برگها در درخت تصمیم در هنگام برخورد با متغیرهای پیوسته استفاده می شود.
در حالی که درختان تصمیم می توانند همگنی برگ ها را با استفاده از آنتروپی / کسب اطلاعات یا ناخالصی جینی بر روی متغیرهای طبقهای، کاهش واریانس را برای تخمین خلوص برگها بر روی متغیرهای پیوسته محاسبه میکنند.

طبقه بندی درخت تصمیم در Scikit-Learn
هدف طبقه بندی درخت تصمیم استنتاج برچسب های کلاس است.

همانطور که در نمودار بالا می بینید، درخت تصمیم یک مرز تصمیم متعامد (نه منحنی) را برمی گرداند و به پیش بینی برچسب ها در یک مجموعه داده غیرخطی کمک می کند.
طبقه بندی درخت تصمیم، مناطق تصمیم را بر اساس مرزهای تصمیم تا حدودی مستطیلی تعریف می کند.
استفاده کنید DecisionTreeClassifier برای ایجاد طبقه بندی درخت تصمیم در Scikit-learn.
زیر:
max_depth: مدل را به سطوح X از اعماق محدود می کند، حتی اگر خلوص به حداکثر برسدcriterion: اجازه دهید روش تخمین خلوص برگ را تعریف کنیم (مثلاًginiیاentropy)
import numpy as np
from sklearn.datasets import make_classification
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
# Define random state for reproducible results
np.random.seed(1)
# Generate dummy dataset
X, y = make_classification(
n_samples=200,
n_features=4,
n_classes=2)
# Split into training and test sets
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
stratify=y)
# Instantiate a decision tree classifier
# And choose a 'critierion' to estimate
# the impurity of a node
dt = DecisionTreeClassifier(
max_depth=3,
criterion='gini'
)
# Train the classifier
dt.fit(X_train, y_train)
# Predict the labels of the test set
y_pred = dt.predict(X_test)
# Evaluate the accuracy score
accuracy_score(y_test, y_pred)
رگرسیون درخت تصمیم
رگرسیون درخت تصمیم بر اساس الگوریتم درخت تصمیم است.
رگرسیون درخت تصمیم یک منحنی سینوسی با داده ها برای تعریف قوانین طبقه بندی یا رگرسیون منطبق می کند.

با این حال، درختهای تصمیم میتوانند با تفسیر جزئیات بیش از حد دانهای از دادههای آموزشی بسته به فراپارامترهای انتخابی، مدل را بیش از حد برازش دهند.

این بیش از حد برازش را می توان با استفاده از روش های گروهی به حداقل رساند (مثلاً جنگل تصادفی).
استفاده کنید DecisionTreeRegressor برای ایجاد یک رگرسیون درخت تصمیم در Scikit-learn.
ابتدا داده های رگرسیون را ایجاد و تجسم کنید.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_regression
# Define random state for reproducible results
np.random.seed(1)
# Generate dummy dataset
X, y = make_regression(
n_samples=200,
n_features=4,
n_targets=4,
bias=2,
noise=20)
# Plot the data
plt.scatter(X, y, alpha=0.5)
plt.xlabel('X')
plt.ylabel('y')
plt.title('Scatter of X and y')
plt.show()

سپس به مجموعه های تست و تمرین تقسیم شده و اجرا کنید DecisionTreeRegressor الگوریتم
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeRegressor
# Split into training and test sets
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size=0.3
)
# Instantiate a decision tree regressor
dt = DecisionTreeRegressor(
max_depth=5
)
# Train the classifier
dt.fit(X_train, y_train)
# Predict the labels of the test set
y_pred = dt.predict(X_test)
در نهایت، عملکرد مدل را با استفاده از mean_squared_error.
from sklearn.metrics import mean_squared_error as MSE
# Compute mean squared error
mse_dt = MSE(y_test, y_pred)
# Compute Root Mean Squared Error (RMSE)
rmse_dt = mse_dt ** (1/2)
# Results
print(f'Mean_squared_error of dt: {mse_dt:.2f}')
print(f'Root mean_square_error of dt: {rmse_dt:.2f}')

جایگزینی برای درختان تصمیم
درختهای تصمیم اغلب میتوانند دادهها را بیش از حد برازش دهند.
یک جایگزین عالی برای درخت های تصمیم گیری، یادگیری گروهی با الگوریتم هایی مانند:
- جنگل های تصادفی
- ماشین های تقویت کننده گرادیان (GBM)
- تجمع بوت استرپ
- آدابوست
نتیجه
براوو تا اینجا پیش رفتی
ما خیلی چیزها را پوشش داده ایم.
ما یاد گرفته ایم:
- اصول درختان تصمیم
- الگوریتم های درخت تصمیم مختلف که می توانند برای طبقه بندی و مسائل رگرسیون استفاده شوند.
- چگونه هر مدل خلوص برگ را تخمین می زند.
- چگونه هر مدل می تواند سوگیری داشته باشد و منجر به برازش بیش از حد داده ها شود
- نحوه اجرای مدل های یادگیری ماشین درخت تصمیم با استفاده از Python و Scikit-learn.
در ادامه به الگوریتم های یادگیری گروهی خواهیم پرداخت.

استراتژیست سئو در Tripadvisor، Seek سابق (ملبورن، استرالیا). متخصص در سئو فنی. در تلاش برای سئوی برنامهریزی شده برای سازمانهای بزرگ از طریق استفاده از پایتون، R و یادگیری ماشین.