طبیعت دائماً در حال تغییر دنیای اطراف ما چالش مهمی را برای توسعه مدلهای هوش مصنوعی ایجاد میکند. اغلب، مدلها بر روی دادههای طولی آموزش داده میشوند با این امید که دادههای آموزشی مورد استفاده بهطور دقیق ورودیهایی را که مدل ممکن است در آینده دریافت کند، نشان دهد. به طور کلی، این فرض پیش فرض که همه داده های آموزشی به یک اندازه مرتبط هستند، اغلب در عمل شکسته می شود. به عنوان مثال، شکل زیر تصاویری از معیار یادگیری غیر ثابت CLEAR را نشان میدهد و نشان میدهد که چگونه ویژگیهای بصری اشیاء به طور قابلتوجهی در طول 10 سال تکامل مییابند (پدیدهای که ما به آن اشاره میکنیم. دریفت مفهومی آهسته)، چالشی را برای مدل های دسته بندی اشیا ایجاد می کند.
 |
| نمونه تصاویر از معیار CLEAR. (برگرفته از لین و همکاران) |
رویکردهای جایگزین، مانند یادگیری آنلاین و مداوم، به طور مکرر یک مدل را با مقادیر کمی از داده های اخیر به روز می کنند تا آن را به روز نگه دارند. این به طور ضمنی داده های اخیر را اولویت بندی می کند، زیرا آموخته های داده های گذشته به تدریج با به روز رسانی های بعدی پاک می شوند. با این حال، در دنیای واقعی، انواع مختلف اطلاعات با سرعت های مختلف ارتباط خود را از دست می دهند، بنابراین دو موضوع کلیدی وجود دارد: 1) بر اساس طراحی، آنها تمرکز می کنند. منحصرا بر روی جدیدترین داده ها و از دست دادن سیگنال از داده های قدیمی تر که پاک شده اند. 2) مشارکت از نمونه های داده کاهش می یابد یکنواخت در طول زمان صرف نظر از محتوای داده ها.
در کار اخیر ما، “مقیاس زمانی-مشروط زوال برای یادگیری غیر ثابت”، پیشنهاد می کنیم به هر نمونه یک امتیاز مهم در طول آموزش اختصاص دهیم تا عملکرد مدل را در داده های آینده به حداکثر برسانیم. برای انجام این کار، ما از یک مدل کمکی استفاده می کنیم که این نمرات را با استفاده از نمونه آموزشی و همچنین سن آن تولید می کند. این مدل به طور مشترک با مدل اولیه آموخته می شود. ما هر دو چالش فوق را بررسی می کنیم و به دستاوردهای قابل توجهی نسبت به سایر روش های یادگیری قوی در طیف وسیعی از مجموعه داده های معیار برای یادگیری غیر ثابت می رسیم. به عنوان مثال، در یک معیار اخیر در مقیاس بزرگ برای یادگیری غیر ثابت (~39 میلیون عکس در یک دوره 10 ساله)، ما تا 15٪ افزایش دقت نسبی را از طریق وزن دهی مجدد داده های آموزشی نشان می دهیم.
چالش رانش مفهومی برای یادگیری تحت نظارت
برای به دست آوردن بینش کمی در مورد رانش آهسته مفهوم، ما طبقهبندیکنندههایی را بر روی یک کار دستهبندی عکس اخیر ساختیم که شامل تقریباً 39 میلیون عکس است که از وبسایتهای رسانههای اجتماعی در یک دوره 10 ساله تهیه شده است. ما آموزش آفلاین را که بر روی تمام داده های آموزشی چندین بار به ترتیب تصادفی تکرار می شود و آموزش مداوم که چندین بار در هر ماه از داده ها به ترتیب (زمانی) تکرار می شود، مقایسه کردیم. ما دقت مدل را هم در طول دوره آموزشی و هم در دوره بعدی که هر دو مدل منجمد شده بودند، اندازهگیری کردیم، به عنوان مثال، بیشتر بر روی دادههای جدید بهروزرسانی نشدند (در زیر نشان داده شده است). در پایان دوره آموزشی (پانل سمت چپ، محور x = 0)، هر دو رویکرد مقدار یکسانی از داده ها را مشاهده کرده اند، اما شکاف عملکرد زیادی را نشان می دهند. این به دلیل فراموشی فاجعه آمیز است، مشکلی در یادگیری مستمر که در آن دانش مدل از داده ها از همان اوایل دوره آموزشی به شیوه ای کنترل نشده کاهش می یابد. از سوی دیگر، فراموشی مزایای خود را دارد – در طول دوره آزمایشی (نشان داده شده در سمت راست)، مدل آموزشدیده مداوم با سرعت بسیار کمتری نسبت به مدل آفلاین تخریب میشود، زیرا کمتر به دادههای قدیمیتر وابسته است. کاهش دقت هر دو مدل در دوره آزمایش تأییدی است بر این که داده ها واقعاً در طول زمان در حال تکامل هستند و هر دو مدل به طور فزاینده ای کمتر مرتبط می شوند.
 |
| مقایسه مدلهای آفلاین و آموزشدیده مداوم در کار طبقهبندی عکس. |
وزن دهی مجدد داده های آموزشی حساس به زمان
ما روشی را طراحی میکنیم که مزایای یادگیری آفلاین (انعطاف پذیری استفاده مجدد مؤثر از همه دادههای موجود) و یادگیری مستمر (قابلیت کمرنگشدن دادههای قدیمیتر) را برای رسیدگی به روند آهسته مفاهیم طراحی میکند. ما بر یادگیری آفلاین بنا میکنیم، سپس کنترل دقیقی بر تأثیر دادههای گذشته و هدف بهینهسازی اضافه میکنیم، که هر دو برای کاهش زوال مدل در آینده طراحی شدهاند.
فرض کنید می خواهیم یک مدل تربیت کنیم، م، با توجه به برخی از داده های آموزشی جمع آوری شده در طول زمان. ما پیشنهاد میکنیم یک مدل کمکی نیز آموزش دهیم که بر اساس محتویات و سن هر نقطه وزنی را تعیین میکند. این وزن سهم را از آن نقطه داده در هدف تمرینی برای م. هدف از وزنه ها بهبود عملکرد است م در مورد داده های آینده
در کارمان، توضیح میدهیم که چگونه مدل کمکی میتواند باشد فرا آموخته شده، یعنی در کنارش یاد گرفت م به نحوی که به یادگیری مدل کمک کند م خود یک انتخاب کلیدی طراحی مدل کمکی این است که ما مشارکتهای مربوط به نمونه و سن را به روشی فاکتورگیری از هم جدا کردیم. به طور خاص، ما وزن را با ترکیب مشارکتهای چند مقیاس زمانی ثابت مختلف زوال تعیین میکنیم و یک «تخصیص» تقریبی یک نمونه معین را به مناسبترین مقیاسهای زمانی آن میآموزیم. ما در آزمایشهای خود متوجه شدیم که این شکل از مدل کمکی به دلیل ترکیبی از سادگی و بیان، از بسیاری از گزینههای دیگر که در نظر گرفتیم، از توابع مفصل بدون محدودیت گرفته تا مقیاس زمانی منفرد (نمایی یا خطی)، بهتر عمل میکند. جزئیات کامل را می توان در مقاله یافت.
به عنوان مثال نمره گذاری وزن
شکل بالای زیر نشان میدهد که مدل کمکی آموختهشده ما واقعاً اشیاء مدرنتری را در چالش تشخیص شیء CLEAR وزن میکند. اشیایی که ظاهر قدیمیتری دارند به همین نسبت وزنشان کم است. در بررسی دقیقتر (شکل پایین زیر، ارزیابی اهمیت ویژگی مبتنی بر گرادیان)، میبینیم که مدل کمکی بر روی شی اصلی درون تصویر تمرکز میکند، در مقابل، به عنوان مثال، ویژگیهای پسزمینه که ممکن است به طور جعلی با سن نمونه مرتبط باشند.
 |
| تصاویر نمونه از معیار CLEAR (دستههای دوربین و کامپیوتر) که به ترتیب بیشترین و کمترین وزنها را توسط مدل کمکی ما اختصاص دادهاند. |
 |
| تجزیه و تحلیل اهمیت ویژگی مدل کمکی ما بر روی تصاویر نمونه از معیار CLEAR. |
نتایج
سود حاصل از داده های در مقیاس بزرگ
ما ابتدا وظیفه طبقهبندی عکس در مقیاس بزرگ (PCAT) را بر روی مجموعه داده YFCC100M که قبلاً مورد بحث قرار گرفت، مطالعه میکنیم و از پنج سال اول دادهها برای آموزش و پنج سال آینده به عنوان دادههای آزمایشی استفاده میکنیم. روش ما (در زیر با رنگ قرمز نشان داده شده است) به طور قابل توجهی نسبت به خط پایه بدون وزن کردن (سیاه) و همچنین بسیاری از تکنیک های یادگیری قوی دیگر بهبود می یابد. جالب توجه است، روش ما عمداً دقت را در گذشته دور (اطلاعات آموزشی بعید است در آینده تکرار شود) در ازای بهبودهای قابل توجه در دوره آزمایشی تغییر می دهد. همچنین، همانطور که می خواهید، روش ما کمتر از سایر خطوط پایه در دوره آزمایش تنزل می یابد.
 |
| مقایسه روش ما و خطوط پایه مربوطه در مجموعه داده PCAT. |
کاربرد گسترده
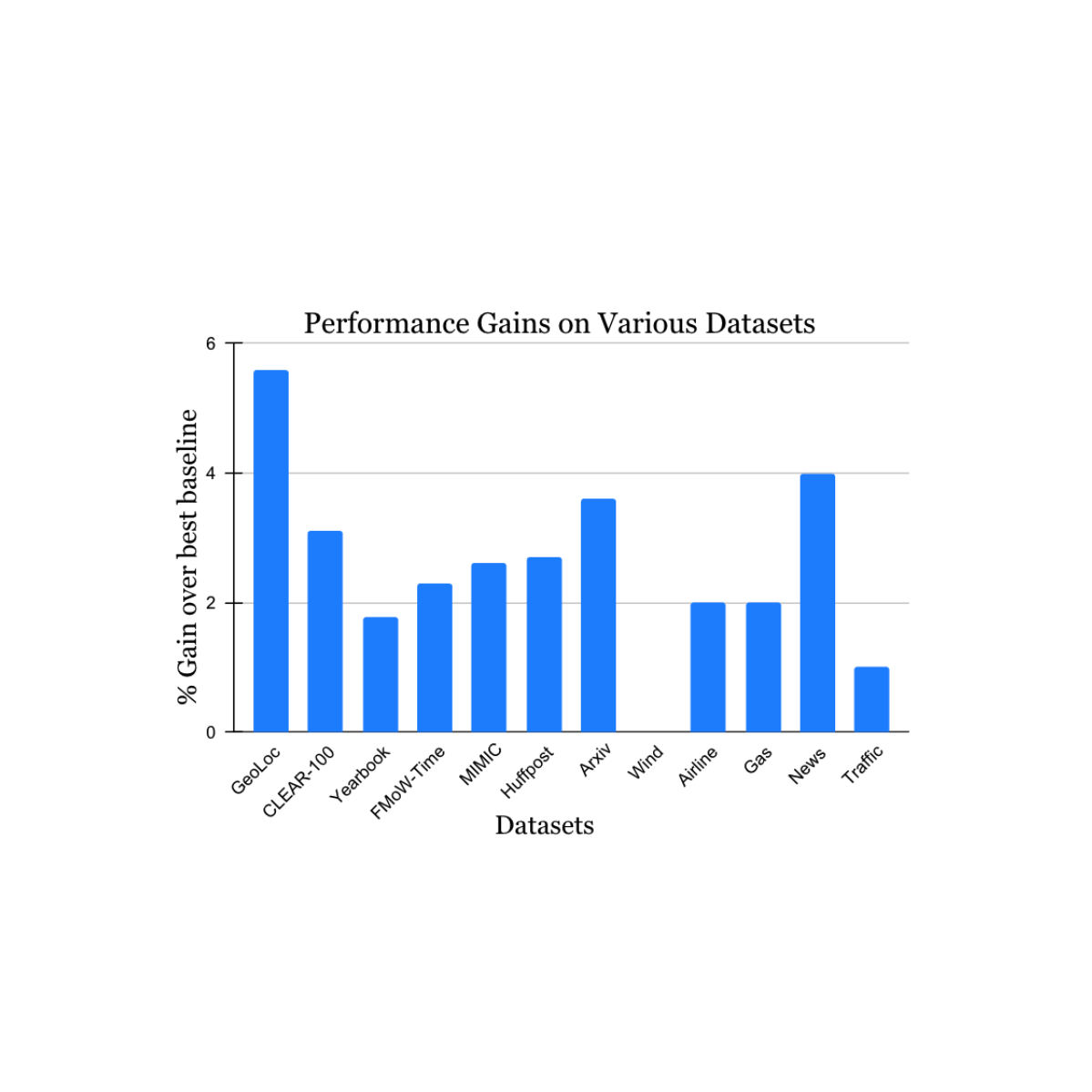
ما یافتههای خود را بر روی طیف گستردهای از مجموعه دادههای چالش یادگیری غیر ثابت که از ادبیات آکادمیک منشأ میگیرند (برای جزئیات بیشتر به 1، 2، 3، 4 مراجعه کنید) که منابع دادهها و روشها (عکسها، تصاویر ماهوارهای، متن رسانههای اجتماعی، سوابق پزشکی، حسگرها را در بر میگیرد) تأیید کردیم. قرائت ها، داده های جدولی) و اندازه ها (از 10 هزار تا 39 میلیون نمونه). ما دستاوردهای قابل توجهی را در دوره آزمایشی در مقایسه با نزدیکترین روش معیار منتشر شده برای هر مجموعه داده (در زیر نشان داده شده) گزارش می کنیم. توجه داشته باشید که بهترین روش شناخته شده قبلی ممکن است برای هر مجموعه داده متفاوت باشد. این نتایج کاربرد گسترده رویکرد ما را نشان می دهد.
 |
| افزایش عملکرد روش ما در انواع وظایف مطالعه دریفت مفهوم طبیعی. دستاوردهای گزارش شده ما بیش از بهترین روش شناخته شده قبلی برای هر مجموعه داده است. |
برنامه های افزودنی برای یادگیری مستمر
در نهایت، ما یک توسعه جالب از کار خود را در نظر می گیریم. کار بالا توضیح داد که چگونه یادگیری آفلاین را می توان برای مدیریت تغییر مفهوم با استفاده از ایده های الهام گرفته از یادگیری مستمر گسترش داد. با این حال، گاهی اوقات یادگیری آفلاین غیر ممکن است – برای مثال، اگر مقدار داده های آموزشی در دسترس برای نگهداری یا پردازش بیش از حد زیاد باشد. ما رویکرد خود را با استفاده از وزندهی مجدد زمانی به یادگیری مستمر به روشی ساده تطبیق دادیم در چارچوب هر سطل داده برای به روز رسانی متوالی مدل استفاده می شود. این پیشنهاد همچنان برخی از محدودیتهای یادگیری مستمر را حفظ میکند، بهعنوان مثال، بهروزرسانیهای مدل فقط بر روی دادههای اخیر انجام میشود و تمام تصمیمهای بهینهسازی (از جمله وزندهی مجدد ما) فقط بر روی آن دادهها گرفته میشود. با این وجود، رویکرد ما به طور مداوم یادگیری مداوم منظم و همچنین طیف گسترده ای از الگوریتم های یادگیری مداوم دیگر را در معیار طبقه بندی عکس شکست می دهد (به زیر مراجعه کنید). از آنجایی که رویکرد ما مکمل ایدههایی است که در بسیاری از خطوط پایه در اینجا مقایسه شدهاند، در صورت ترکیب با آنها، سودهای بزرگتری را پیشبینی میکنیم.
 |
| نتایج روش ما با یادگیری مستمر، در مقایسه با آخرین خطوط پایه، سازگار است. |
نتیجه
ما با ترکیب نقاط قوت رویکردهای قبلی – یادگیری آفلاین با استفاده مجدد مؤثر از دادهها و یادگیری مستمر با تأکید بر دادههای جدیدتر، به چالش جابهجایی دادهها در یادگیری پرداختیم. ما امیدواریم که کار ما به بهبود استحکام مدل نسبت به رانش مفهومی در عمل کمک کند، و علاقه و ایدههای جدیدی را در پرداختن به مشکل فراگیر رانش کند مفهوم ایجاد کند.
سپاسگزاریها
ما از مایک موزر برای بسیاری از بحث های جالب در مرحله اولیه این کار، و همچنین توصیه ها و بازخوردهای بسیار مفید در طول توسعه آن تشکر می کنیم.