خوشه بندی موضوع کلمات کلیدی با SEO Python (Sklearn TF-IDF + Affinity Propagation)
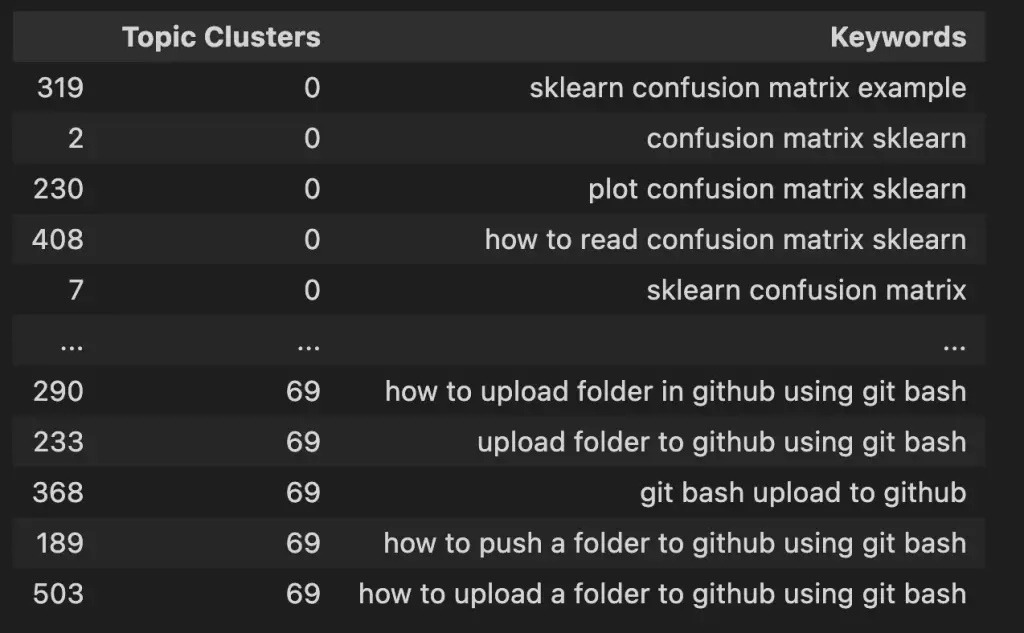
در این آموزش SEO Python، نحوه گروه بندی کلمات کلیدی را در کلاسترهای موضوعی با استفاده از Python و کتابخانه Scikit-learn خواهیم آموخت. اسکریپت پایتون از طریق فهرستی از کلمات کلیدی ذخیره شده در یک فایل متنی استفاده می کند TfidfVectorizer() برای ایجاد یک نمایش TF-IDF از لیست کلمات کلیدی و سپس اعمال آن AffinityPropagation() …