گزارش طبقه بندی اغلب در یادگیری ماشین برای محاسبه دقت مدل طبقه بندی بر اساس مقادیر ماتریس سردرگمی استفاده می شود.
تفسیر معیارهای گزارش طبقه بندی
جدول زیر از یک الگوریتم طبقه بندی می آید که از آن استفاده می کند KNeighborsClassifier کلاس از Scikit-Learn برای طبقه بندی سرطان سینه (کد پایتون زیر).
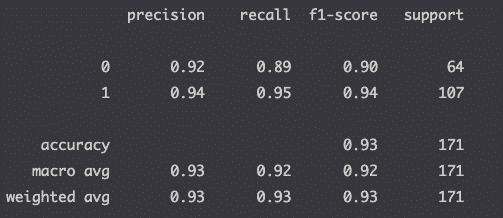
گزارش طبقه بندی با استفاده از classification_report() تابع از ماژول متریک Scikit-learn.
from sklearn.metrics import classification_report
classification_report(y_test, y_pred)دقت در گزارش طبقه بندی چگونه محاسبه می شود؟
دقت به ما می گوید دقت از پیش بینی های مثبت
وقتی True را پیشبینی میکنیم، چند بار واقعاً درست است؟ این عدد باید تا حد امکان زیاد باشد.
دقت بالا: بسیاری از مقادیر True به عنوان False پیشبینی نشده بودند

مثبت واقعی / (مثبت واقعی + مثبت کاذب)
Recall چیست؟
فراخوان، همچنین به نام sensivity، یا hit rate، به ما می گوید کسر از پیش بینی های مثبت به درستی شناسایی شده است.
چه کسری از پیشبینیهای درست واقعاً درست بود؟این عدد باید تا حد امکان زیاد باشد.
یادآوری بالا: اکثر مقادیر True را به درستی پیش بینی کرد.

مثبت واقعی / (مثبت واقعی + منفی کاذب)
توجه داشته باشید که از metrics.recall_score (واقعی، پیشبینیشده، pos_label=0) میتوان برای محاسبه ویژگی مدل استفاده کرد.
ویژگی اساساً مخالف یادآوری است:
منفی واقعی / (منفی واقعی + مثبت کاذب)
امتیاز f1 چیست؟
را f1-score، یا F measure، معیارهای precision و recall همزمان با یافتن میانگین هارمونیک دو مقدار.
این امتیاز زمانی مفید است که شما نمرات مخالف دارید precision و recall.

2 * ((یادآوری * دقت) / (دقت + فراخوان))
دقت در گزارش طبقه بندی چیست؟
دقت اندازه گیری می شود دقت از همه پیش بینی ها (مثبت و منفی).
دقت باید تا حد امکان بالا باشد.

(مثبت واقعی + منفی واقعی) / کل پیش بینی ها
پشتیبانی در گزارش طبقه بندی چیست؟
پشتیبانی تعداد رخدادهای هر کلاس در شما است y_test
نحوه محاسبه گزارش طبقه بندی با Scikit-learn
در اینجا نحوه محاسبه یک گزارش طبقه بندی بر روی الگوریتم k-نزدیکترین همسایه آورده شده است.
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
def to_target(x):
"""Map targets to target names"""
return list(dataset.target_names)[x]
# Load data
dataset = load_breast_cancer()
df = pd.DataFrame(dataset.data,columns=dataset.feature_names)
df['target'] = pd.Series(dataset.target)
df['target_names'] = df['target'].apply(to_target)
# Define predictor and predicted datasets
X = df.drop(['target','target_names'], axis=1).values
y = df['target_names'].values
# split taining and test set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42, stratify=y)
# train the model
knn = KNeighborsClassifier(n_neighbors=8)
knn.fit(X_train, y_train)
y_pred = knn.predict(X_test)
# compute accuracy of the model
knn.score(X_test, y_test)
# compute the classification report
print(classification_report(y_test, y_pred))
تعاریف
| گزارش طبقه بندی | محاسبه دقت یک مدل طبقه بندی |
| Scikit- Learn | بسته یادگیری ماشین در پایتون |
| دقت، درستی | دقت پیش بینی های مثبت |
| به خاطر آوردن | کسری از پیش بینی های مثبت که به درستی شناسایی شده اند |
| f1-امتیاز | میانگین هارمونیک دقت و یادآوری |
نتیجه
اکنون نحوه تفسیر و محاسبه گزارش طبقه بندی را برای اندازه گیری دقت الگوریتم طبقه بندی توضیح دادیم.

استراتژیست سئو در Tripadvisor، Seek سابق (ملبورن، استرالیا). متخصص در سئو فنی. در تلاش برای سئوی برنامهریزی شده برای سازمانهای بزرگ از طریق استفاده از پایتون، R و یادگیری ماشین.