خوشهبندی Kmeans یک الگوریتم یادگیری ماشینی است که اغلب در یادگیری بدون نظارت برای مشکلات خوشهبندی استفاده میشود.
این روشی است که فاصله اقلیدسی را محاسبه می کند تا مشاهدات را به k خوشه تقسیم کند که در آن هر مشاهده به خوشه ای با نزدیک ترین میانگین (مرکز خوشه ای) نسبت داده می شود.
در این آموزش، نحوه عملکرد الگوریتم خوشه بندی KMeans و نحوه استفاده از Python و Scikit-learn را برای اجرای مدل و طبقه بندی داده ها مانند مثال زیر خواهیم آموخت.

در نهایت، من یک برگه تقلب ارائه می کنم که به شما کمک می کند تا نحوه عملکرد الگوریتم را در انتهای مقاله به یاد بیاورید.
الگوریتم خوشه بندی KMeans چگونه کار می کند؟
الگوریتم خوشه بندی KMeans در چند مرحله کار می کند که توسط سراج راوال به خوبی توضیح داده شده است.
- انتخاب تعداد خوشه ها (K)
- به طور تصادفی تعدادی از نقاط داده را انتخاب کنید که با تعداد خوشه ها مطابقت دارد
- فاصله بین هر نقطه تا خوشه اولیه آن را اندازه گیری کنید
- هر نقطه داده را به نزدیکترین خوشه اولیه آن اختصاص دهید
- محاسبات را برای هر نقطه تکرار کنید
- میانگین هر خوشه را محاسبه کنید
- میانگین را به عنوان مرکز خوشه جدید اختصاص دهید
- هر نقطه را با مرکز خوشه جدید اندازه گیری کنید
- خوشه ها را دوباره تعریف کنید و میانگین جدید را به عنوان مرکز خوشه بعدی اختصاص دهید
- فرآیند را تا زمان همگرایی تکرار کنید
1. تعداد خوشه ها را انتخاب کنید (K)
در خوشهبندی KMeans، تعداد خوشهها (K) باید تعریف شود.
این «K» در «خوشهبندی K-Means» است.
در زیر یک مثال وجود دارد که در آن به وضوح می توانیم 3 خوشه را در داده ها ببینیم. در این مورد K=3.

2. به طور تصادفی تعدادی از نقاط داده را انتخاب کنید که با تعداد خوشه ها مطابقت دارد
الگوریتم KMeans تعدادی از نقاط داده تصادفی را انتخاب می کند که با مقدار K (تعداد خوشه ها) مطابقت دارند.
اینها به خوشه های اولیه (مرکز خوشه ای) تبدیل خواهند شد.

3. فواصل بین هر نقطه تا خوشه اولیه آن را اندازه گیری کنید
الگوریتم خوشه بندی فواصل اقلیدسی بین هر نقطه تا هر نقطه خوشه را محاسبه می کند.

در KMeans، فاصله اقلیدسی بین تمام نقاط تا مرکز با اندازه گیری فاصله مختصات Y و X تا مرکز محاسبه می شود. با مجذور کردن نتایج، مقدار را محاسبه می کنیم.
به عنوان مثال، برای یک نقطه A (1،2) و یک مرکز C (3،4)، فاصله اقلیدسی با فرمول s = (1-3)² + (2-4)² داده می شود.
4. هر نقطه داده را به نزدیکترین خوشه اولیه آن اختصاص دهید
اولین نقطه را به نزدیکترین خوشه اولیه اختصاص دهید.

5. محاسبات را برای هر نقطه تکرار کنید

6. میانگین هر خوشه را محاسبه کنید
مرحله بعدی اضافه کردن تمام نقاط داده در هر خوشه و تقسیم آنها بر تعداد نقاط خوشه است که اساساً میانگین خوشه محاسبه می شود.
از این رو “میانگین” در “K-Means” است.
7. تعیین میانگین به عنوان مرکز خوشه جدید
سپس، میانگین به عنوان مرکز خوشه بعدی انتخاب می شود.

8. هر نقطه را با مرکز خوشه جدید اندازه گیری کنید

9. خوشه ها را دوباره تعریف کنید و میانگین جدید را به عنوان مرکز خوشه بعدی اختصاص دهید

10. فرآیند را تا زمان همگرایی تکرار کنید
این روند را تکرار کنید تا کلاسترها دیگر تغییر نکنند.
همچنین امکان تعریف حداکثر تعداد تکرار در مجموعه داده های بزرگ برای کاهش منابع محاسباتی وجود دارد.

11. پارامترهایی را با کوچکترین SSE انتخاب کنید
هدف الگوریتمهای خوشهبندی یادگیری ماشینی یافتن خوشههایی است که خطاها را به حداقل میرسانند. در مورد KMeans، خطا اغلب با مجموع مربعات خطاها (یا SSE) محاسبه می شود.
چگونه از تعداد مناسب خوشه ها (K) استفاده کنیم؟
تعداد بهینه خوشه ها معمولاً با تعداد کلاس ها برابر است. اگر این تعداد کلاس را می دانید، از آن به عنوان تعداد خوشه های خود استفاده کنید.
به عنوان مثال، اگر می دانید که صفحات وب را در 5 دسته مختلف دسته بندی می کنید، می توانید از 5 به عنوان تعداد خوشه های خود استفاده کنید.
در غیر این صورت، اگر تعداد کلاس ها را نمی دانید، می توانید از روش Elbow برای تعریف تعداد کلاسترها استفاده کنید.
روش آرنج
روش زانویی در تحلیل خوشه ای برای کمک به تعیین تعداد بهینه خوشه ها در یک مجموعه داده استفاده می شود.
این کار توسط:
- تعریف محدوده ای از مقادیر K برای اجرای خوشه بندی K-Means
- ارزیابی مجموع مربعات خطا (SSE) برای مدل با استفاده از هر یک از اعداد تعریف شده خوشه.
مقدار K بهینه معمولاً در «زانو» یافت میشود، جایی که منحنی شروع به ثابتتر شدن میکند.

قوانین روش آرنج
- حداکثر خوشه هایی که می توانید داشته باشید برابر با تعداد امتیازات فردی است.
- هنگامی که تعداد خوشه ها با تعداد نقاط برابر باشد، اعوجاج (مجموع مجذور فواصل) برابر با 0 است.
- خوشه های بیشتر مستلزم هزینه های محاسباتی بیشتر است.
جایگزین های طرح آرنج
هنگامی که داده ها به طور مساوی توزیع می شوند، روش زانویی K بهینه را به وضوح تعریف نمی کند.

همچنین می توانید بهترین مقدار K را به صورت برنامه ریزی شده یا با استفاده از ضریب silhouette یا به طور متناوب با استفاده از آمار شکاف انتخاب کنید.
معنی اینرسی KMeans (مجموع مربعات خطا) چیست؟
اینرسی KMeans که به عنوان مجموع مربعات خطا (یا SSE) نیز شناخته می شود، مجموع فواصل تمام نقاط یک خوشه را از مرکز نقطه محاسبه می کند.
این تفاوت بین مقدار مشاهده شده و مقدار پیش بینی شده است. با استفاده از مجموع مقادیر منهای میانگین، مجذور محاسبه می شود.
(point_1 - mean)^2 + (point_2 - mean)^2 + (point_N - mean)^2
مجموع مربعات خطاها اغلب نام های مختلفی به خود می گیرد:
چه زمانی از KMeans استفاده کنیم؟
KMeans برای موارد زیر مناسب است:
- مشکلات یادگیری بدون نظارت
- با داده های عددی، روی داده های دسته بندی کار نمی کند
- برای مجموعه داده های خطی مناسب تر است
مزایای
معایب
- باید خوشه ها را تعریف کرد
- زمان سختی برای رسیدگی به موارد پرت
- در مجموعه داده های غیر خطی شکست می خورد
- به سمت خوشه های هم اندازه سوگیری دارد
- دانه ها بر نتایج خوشه بندی تأثیر می گذارند (مثلاً
np.random.seed())
از طرف دیگر، می توانید از DBSCAN یا خوشه بندی سلسله مراتبی استفاده کنید.
اگر KMeans شکست بخورد چه؟
هنگامی که شکل خوشه ها گرد، به اندازه / متراکم یکسان نیستند یا زمانی که نقاط پرت زیادی وجود دارد، KMeans می تواند عملکرد ضعیفی داشته باشد.
در این صورت می توانیم از الگوریتم خوشه بندی HDBSCAN و تعبیه برای مقایسه اسناد استفاده کنیم. HDBSCAN معنای معنایی را برای کمک به خوشه بندی اسناد درک می کند.
KMeans Clustering با Python و Scikit-learn
در ادامه این مقاله، خوشهبندی KMeans را با استفاده از Scikit-learn انجام خواهیم داد.
ما خواهیم کرد:
- داده های ساختگی برای خوشه بندی ایجاد کنید
- آموزش و خوشهبندی دادهها با استفاده از KMeans
- داده های خوشه ای را رسم کنید
- با استفاده از روش Elbow بهترین مقدار را برای K انتخاب کنید.
داده های ساختگی برای خوشه بندی ایجاد کنید
ابتدا مجموعه داده را با استفاده از آن ایجاد می کنیم make_blobs.
from sklearn.datasets import make_blobs
# create a dataset of 200 samples
# and 5 clusters
features, labels = make_blobs(
n_samples=200,
centers=5
)
آموزش و خوشهبندی دادهها با استفاده از KMeans
در مرحله بعد، مدل را با استفاده از 5 خوشه آموزش می دهیم و آن را به 10 تکرار با دانه های مرکزی مختلف محدود می کنیم.
from sklearn.cluster import KMeans
# Instanciate the model with 5 'K' clusters
# and 10 iterations with different
# centroid seed
model = KMeans(
n_clusters=5,
n_init=10,
random_state=42
)
# train the model
model.fit(features)
# make a prediction on the data
p_labels = model.predict(features)
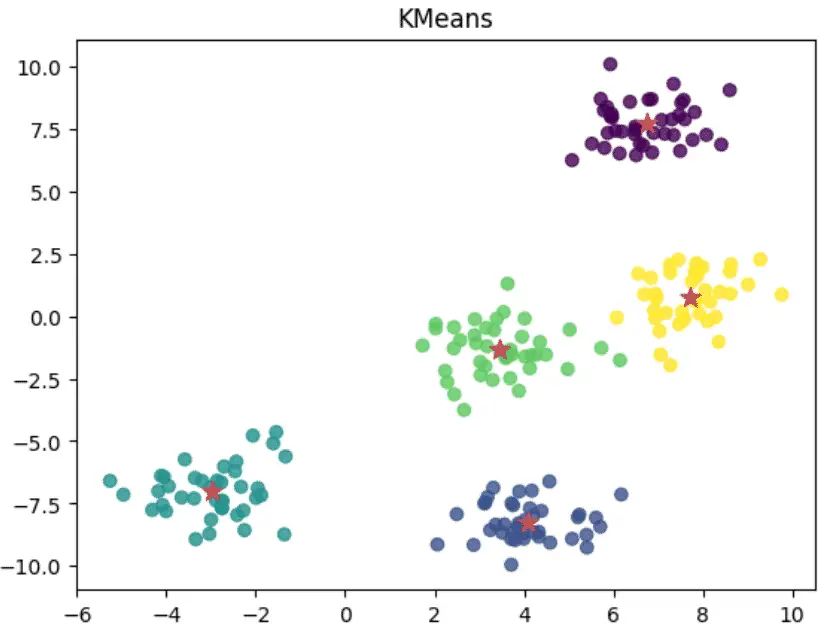
داده های خوشه ای را رسم کنید
سپس از matplotlib برای رسم نمودارهای پراکندگی KMeans و مرکزهای خوشه ای استفاده می کنیم.
import matplotlib.pyplot as plt
plt.style.use('default')
X = features[:,0]
y = features[:,1]
plt.scatter(X, y, c=p_labels, alpha=0.8)
cluster_centers = model.cluster_centers_
cs_x = cluster_centers[:,0]
cs_y = cluster_centers[:,1]
plt.scatter(cs_x, cs_y, marker='*', s=100, c='r')
plt.title('KMeans')
plt.show()
بهترین مقدار را برای K (kmeans.inertia_) انتخاب کنید
در نهایت نمودار روش elbow را رسم می کنیم تا ببینیم بهترین عدد خوشه را انتخاب کرده ایم یا خیر.
ما از قبل می دانیم که پاسخ در این مورد مثبت است زیرا تعداد خوشه ها را بر اساس داده هایی که تولید کرده ایم انتخاب کرده ایم.
در اینجا، Seaborn اختیاری است. برای تعریف سبک طرح استفاده می شود.
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
ks = range(1, 10)
ssr = []
# For each cluster K
for k in ks:
# create model instance of K clusters
model = KMeans(n_clusters=k)
# fit the model
model.fit(features)
# append the inertial to a list
ssr.append(model.inertia_)
# Plot
plt.plot(ks, ssr, '-o')
plt.xlabel('Clusters (k)')
plt.ylabel('SSR')
plt.xticks(ks)
plt.title('Elbow method for optimal K')
plt.axvline(x=5,linestyle='--',c='grey')
plt.show()
KMeans Clustering با SciPy
Scikit Learn تنها کتابخانه یادگیری ماشینی نیست که قادر به اجرای الگوریتم Kmeans است.
در زیر مثالی از نحوه اجرای الگوریتم KMeans در SciPy آورده شده است.
نتیجه در یک Pandas DataFrame ذخیره می شود و با استفاده از کتابخانه Seaborn پایتون رسم می شود.
import matplotlib.pyplot as plt
from numpy import vstack,array
from numpy.random import rand
import pandas as pd
import seaborn as sns
from scipy.cluster.vq import kmeans,vq,whiten
# Generate data
data = vstack((
(rand(30,2)+1),(rand(30,2)+2.5),(rand(30,2)+4)
))
# standardize the features
data = whiten(data)
# Run KMeans with 3 clusters
centroids, _ = kmeans(data, 3)
# Predict labels
labels, _ = vq(
data, centroids
)
# Create DataFrame
df = pd.DataFrame(data, columns=['x','y'])
df['labels'] = labels
# Plot Clusters
sns.scatterplot(
x='x',
y='y',
hue='labels',
data=df
)
# Plot cluster centers
cs_x = centroids[:,0]
cs_y = centroids[:,1]
plt.scatter(cs_x, cs_y, marker='*', s=100, c='r')
plt.title('Kmeans Clustering with SciPy')
plt.show()

روش های KMeans در پایتون
بر اساس مستندات رسمی، در اینجا لیستی از روشهایی است که میتوان روی شی KMeans در پایتون استفاده کرد.
| مناسب() | محاسبه k-به معنی خوشه بندی است. |
| fit_predict() | مراکز خوشه را محاسبه کنید و شاخص خوشه را برای هر نمونه پیش بینی کنید. |
| fit_transform() | خوشه بندی را محاسبه کنید و X را به فضای فاصله خوشه ای تبدیل کنید. |
| get_feature_names_out() | دریافت نام ویژگی های خروجی برای تبدیل. |
| get_params() | پارامترهای این برآوردگر را دریافت کنید. |
| پیش بینی() | نزدیکترین خوشه را پیش بینی کنید که هر نمونه در X به آن تعلق دارد. |
| نمره() | مخالف مقدار X در هدف K-means. |
| set_params() | پارامترهای این برآوردگر را تنظیم کنید. |
| تبدیل() | X را به فضایی با فاصله خوشه ای تبدیل کنید. |
برگه تقلب الگوریتم KMeans

پروژه های یادگیری ماشین با KMeans
سوالات متداول KMeans
K-Means یک الگوریتم یادگیری بدون نظارت است. بدون نظارت است زیرا نقاط برچسب خارجی ندارند.
KMeans یک الگوریتم خوشهبندی است که بدون نیاز به دادههای برچسبگذاریشده قبلی، گروهها را به یک مجموعه داده اختصاص میدهد.
بسته به داده هایی که در دسترس دارید، هر کدام ممکن است مدل بهتری باشد. تفاوت در این واقعیت نهفته است که KNN (K-نزدیکترین همسایه) یک الگوریتم یادگیری نظارت شده است (نیاز به دادههای برچسبگذاری شده) است که در وظایف طبقهبندی استفاده میشود و KMeans یک الگوریتم یادگیری بدون نظارت است (بدون نیاز به برچسب) که در وظایف خوشهبندی استفاده میشود.
KMeans از تکنیکی استفاده می کند که از فاصله اقلیدسی و میانگین نقاط داده انتخاب شده به عنوان مرکز خوشه استفاده می کند و مرکز را همراه با میانگین جدید تا همگرایی حرکت می دهد.
KMeans Clustering در کاربردهای مختلفی مانند خوشهبندی اسناد در بازیابی اطلاعات و سئو، تقسیمبندی مشتری، سیستمهای توصیهکننده در پلتفرمهای وب، شناسایی الگو استفاده میشود. اغلب در بازاریابی برای بهبود تجربه کاربر یا به دست آوردن بینش از داده ها استفاده می شود.
یکی از دلایلی که کاربر ممکن است Sklearn را به SciPy ترجیح دهد این است که مستندات بهتر و ابزارهای بیشتری دارد (به عنوان مثال GridsearchCV). در مورد استفاده خاص از KMeans، کلاس SKlearn پارامترهای بیشتری نسبت به SciPy دارد. از طرف دیگر، SciPy اجازه می دهد تا centroids را تنظیم کنید.
فاصله اقلیدسی بین تا نقاط، طول یک خط بین دو نقطه است.
KMeans Clustering
نتیجه
ما در این مقاله به موارد زیادی پرداخته ایم. اکنون می دانیم که خوشه بندی KMeans چیست و الگوریتم چگونه کار می کند. ما همچنین می دانیم که چگونه داده های عددی را با Scikit-learn خوشه بندی کنیم.

استراتژیست سئو در Tripadvisor، Seek سابق (ملبورن، استرالیا). متخصص در سئو فنی. در تلاش برای سئوی برنامهریزی شده برای سازمانهای بزرگ از طریق استفاده از پایتون، R و یادگیری ماشین.