یادگیری تقویتی عمیق (RL) همچنان به پیشرفت های بزرگی در حل مسائل تصمیم گیری متوالی در دنیای واقعی مانند ناوبری با بالون، فیزیک هسته ای، رباتیک و بازی ها ادامه می دهد. علیرغم وعده آن، یکی از عوامل محدود کننده آن زمان طولانی تمرین است. در حالی که رویکرد فعلی برای سرعت بخشیدن به آموزش RL در کارهای پیچیده و دشوار، مقیاس آموزشی توزیع شده را تا صدها یا حتی هزاران گره محاسباتی افزایش می دهد، اما همچنان به استفاده از منابع سخت افزاری قابل توجهی نیاز دارد که آموزش RL را گران می کند و در عین حال تأثیر زیست محیطی آن را افزایش می دهد. با این حال، کار اخیر [1, 2] نشان می دهد که بهینه سازی عملکرد بر روی سخت افزار موجود می تواند ردپای کربن (یعنی کل انتشار گازهای گلخانه ای) آموزش و استنتاج را کاهش دهد.
RL همچنین می تواند از تکنیک های بهینه سازی سیستم مشابهی بهره مند شود که می تواند زمان آموزش را کاهش دهد، استفاده از سخت افزار را بهبود بخشد و دی اکسید کربن (CO) را کاهش دهد.2) انتشارات یکی از این تکنیکها کوانتیزاسیون است، فرآیندی که اعداد نقطه شناور با دقت کامل (FP32) را به اعداد با دقت کمتر (int8) تبدیل میکند و سپس محاسبات را با استفاده از اعداد با دقت پایینتر انجام میدهد. کوانتیزاسیون میتواند در هزینه و پهنای باند ذخیرهسازی حافظه برای محاسبات سریعتر و کارآمدتر صرفهجویی کند. کوانتیزاسیون با موفقیت در یادگیری تحت نظارت اعمال شده است تا امکان استقرار لبههای مدلهای یادگیری ماشین (ML) و دستیابی به آموزش سریعتر را فراهم کند. با این حال، فرصتی برای اعمال کوانتیزاسیون در آموزش RL وجود دارد.
برای این منظور، ما “QuaRL: Quantization for Fast and Environmentally Sustainable Reinforcement Learning” را ارائه می کنیم که در نشریه معاملات تحقیق یادگیری ماشین مجله، که معرفی می کند پارادایم جدیدی به نام ActorQ که کوانتیزاسیون را برای افزایش سرعت آموزش RL بین 1.5-5.4 برابر و در عین حال حفظ عملکرد اعمال می کند. علاوه بر این، نشان میدهیم که در مقایسه با تمرین با دقت کامل، ردپای کربن نیز به میزان قابل توجهی با ضریب 1.9-3.8 برابر کاهش مییابد.
استفاده از Quantization در آموزش RL
در آموزش سنتی RL، الف یادگیرنده سیاست در مورد یک اعمال می شود بازیگر، که از این خط مشی برای کشف محیط و جمع آوری نمونه داده ها استفاده می کند. نمونه های جمع آوری شده توسط بازیگر سپس توسط یادگیرنده به طور مداوم سیاست اولیه را اصلاح کنید. به طور دوره ای، خط مشی آموزش دیده در سمت یادگیرنده برای به روز رسانی استفاده می شود بازیگران خط مشی. برای اعمال کوانتیزاسیون در آموزش RL، پارادایم ActorQ را توسعه میدهیم. ActorQ همان دنباله ای را انجام می دهد که در بالا توضیح داده شد، با یک تفاوت کلیدی این است که به روز رسانی خط مشی از یادگیرنده به بازیگر، کوانتیزه می شود، و بازیگر محیط را با استفاده از خط مشی کوانتیزه int8 برای جمع آوری نمونه ها بررسی می کند.
استفاده از کوانتیزاسیون در آموزش RL به این روش دو مزیت کلیدی دارد. اول، ردپای حافظه سیاست را کاهش می دهد. برای همان اوج پهنای باند، داده کمتری بین یادگیرندگان و بازیگران منتقل میشود، که هزینه ارتباط برای بهروزرسانی خطمشی را از یادگیرندگان به بازیگران کاهش میدهد. دوم، بازیگران استنتاج روی خط مشی کوانتیزه شده برای ایجاد اقدامات برای یک وضعیت محیطی معین انجام می دهند. فرآیند استنتاج کوانتیزه در مقایسه با انجام استنتاج با دقت کامل بسیار سریعتر است.
 |
| مروری بر آموزش سنتی RL (ترک کرد) و آموزش ActorQ RL (درست). |
در ActorQ از چارچوب RL توزیع شده ACME استفاده می کنیم. بلوک کوانتایزر کوانتیزاسیون یکنواختی را انجام می دهد که سیاست FP32 را به int8 تبدیل می کند. بازیگر استنتاج را با استفاده از محاسبات بهینه سازی شده int8 انجام می دهد. اگرچه هنگام طراحی بلوک کوانتایزر از کوانتیزاسیون یکنواخت استفاده میکنیم، اما معتقدیم که سایر تکنیکهای کوانتیزهسازی میتوانند جایگزین کوانتیزاسیون یکنواخت شوند و نتایج مشابهی را ایجاد کنند. نمونه های جمع آوری شده توسط بازیگران توسط یادگیرنده برای آموزش خط مشی شبکه عصبی استفاده می شود. به طور متناوب خط مشی آموخته شده توسط بلوک کوانتایزر کوانتیزه می شود و برای بازیگران پخش می شود.
Quantization زمان و عملکرد آموزش RL را بهبود می بخشد
ما ActorQ را در طیف وسیعی از محیطها، از جمله Deepmind Control Suite و OpenAI Gym ارزیابی میکنیم. ما سرعت و عملکرد بهبود یافته D4PG و DQN را نشان می دهیم. ما D4PG را به عنوان بهترین الگوریتم یادگیری در ACME برای کارهای Deepmind Control Suite انتخاب کردیم و DQN یک الگوریتم RL استاندارد و پرکاربرد است.
ما سرعت قابل توجهی (بین 1.5x و 5.41x) را در سیاست های آموزشی RL مشاهده می کنیم. مهمتر از آن، عملکرد حتی زمانی که بازیگران استنتاج کوانتیزه int8 را انجام می دهند حفظ می شود. شکلهای زیر این موضوع را برای عوامل D4PG و DQN برای کارهای Deepmind Control Suite و OpenAI Gym نشان میدهد.
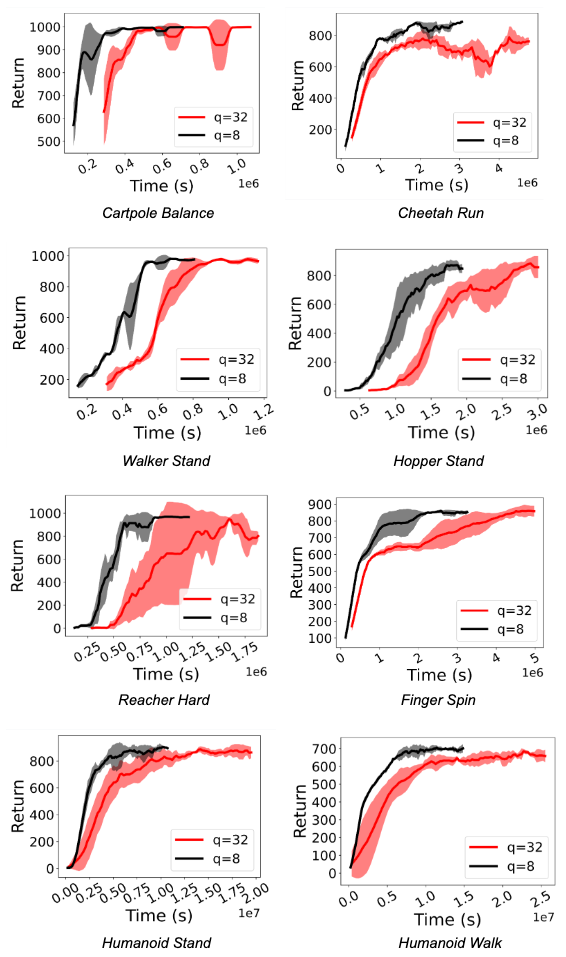 |
| مقایسه آموزش RL با استفاده از سیاست FP32 (q=32) و خط مشی int8 کوانتیزه شده (q=8) برای عوامل D4PG در وظایف مختلف Deepmind Control Suite. Quantization به سرعت 1.5x تا 3.06x دست می یابد. |
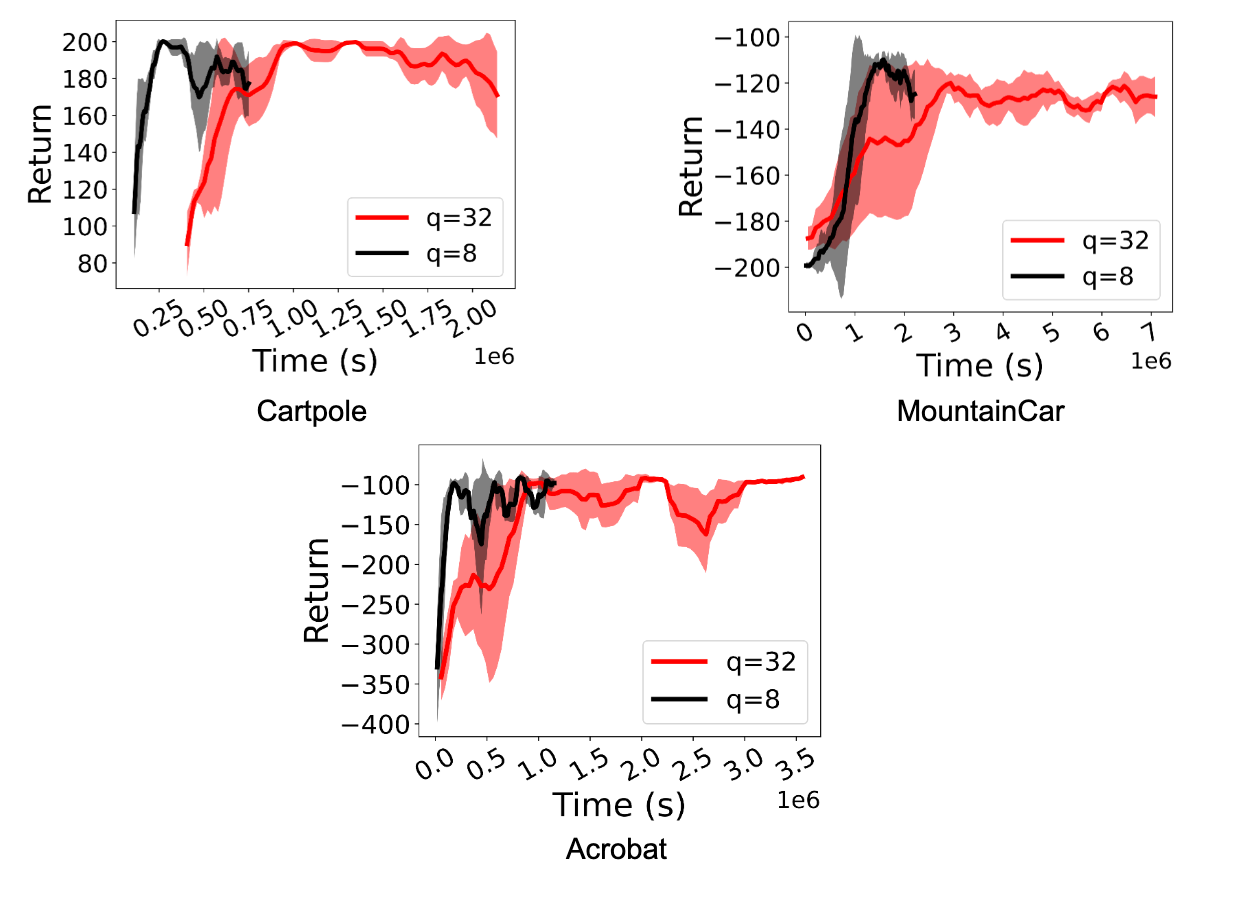 |
| مقایسه آموزش RL با استفاده از سیاست FP32 (q=32) و خط مشی int8 کوانتیزه شده (q=8) برای عوامل DQN در محیط OpenAI Gym. Quantization به سرعت 2.2x تا 5.41x دست می یابد. |
کوانتیزاسیون انتشار کربن را کاهش می دهد
اعمال کوانتیزاسیون در RL با استفاده از ActorQ زمان آموزش را بدون تأثیر بر عملکرد بهبود می بخشد. پیامد مستقیم استفاده کارآمدتر از سخت افزار، ردپای کربن کمتر است. ما بهبود ردپای کربن را با در نظر گرفتن نسبت انتشار کربن هنگام استفاده از خطمشی FP32 در حین آموزش نسبت به انتشار کربن هنگام استفاده از خط مشی int8 در طول آموزش اندازهگیری میکنیم.
به منظور اندازه گیری انتشار کربن برای آزمایش آموزشی RL، ما از آزمایش-ضربه-ردیاب پیشنهاد شده در کار قبلی استفاده می کنیم. ما سیستم ActorQ را با رابطهای برنامهنویسی مانیتور کربن برای اندازهگیری انرژی و انتشار کربن برای هر آزمایش آموزشی ابزار میکنیم.
در مقایسه با انتشار کربن هنگام اجرا با دقت کامل (FP32)، مشاهده می کنیم که کمی سازی سیاست ها، بسته به کار، انتشار کربن را از 1.9 برابر به 3.76 برابر کاهش می دهد. از آنجایی که سیستم های RL برای اجرا بر روی هزاران هسته سخت افزاری و شتاب دهنده های توزیع شده مقیاس بندی شده اند، ما معتقدیم که کاهش مطلق کربن (برحسب کیلوگرم CO اندازه گیری می شود.2) می تواند بسیار مهم باشد.
 |
| مقایسه انتشار کربن بین آموزش با استفاده از سیاست FP32 و سیاست int8. مقیاس محور X با انتشار کربن سیاست FP32 نرمال شده است. ActorQ که با نوارهای قرمز بزرگتر از 1 نشان داده می شود، انتشار کربن را کاهش می دهد. |
نتیجه گیری و مسیرهای آینده
ما ActorQ را معرفی میکنیم، یک الگوی جدید که کوانتیزهسازی را در آموزش RL اعمال میکند و با حفظ عملکرد، به بهبودهای سرعت 1.5-5.4 برابری میرسد. علاوه بر این، ما نشان میدهیم که ActorQ میتواند ردپای کربن آموزش RL را در مقایسه با تمرین با دقت کامل بدون کوانتیزه کردن، ضریب 1.9-3.8 برابر کاهش دهد.
ActorQ نشان می دهد که کوانتیزاسیون را می توان به طور موثر در بسیاری از جنبه های RL، از به دست آوردن سیاست های کوانتیزه با کیفیت بالا و کارآمد گرفته تا کاهش زمان آموزش و انتشار کربن، اعمال کرد. از آنجایی که RL به برداشتن گام های بزرگ در حل مشکلات دنیای واقعی ادامه می دهد، ما معتقدیم که پایدار کردن آموزش RL برای پذیرش بسیار مهم است. همانطور که ما آموزش RL را به هزاران هسته و پردازنده گرافیکی تقسیم می کنیم، حتی یک بهبود 50 درصدی (همانطور که به طور تجربی نشان داده ایم) باعث صرفه جویی قابل توجهی در هزینه دلار مطلق، انرژی و انتشار کربن می شود. کار ما اولین قدم به سوی استفاده از کوانتیزه کردن در آموزش RL برای دستیابی به آموزش کارآمد و پایدار از نظر زیست محیطی است.
در حالی که طراحی ما از کوانتایزر در ActorQ متکی بر کوانتیزاسیون یکنواخت ساده است، ما معتقدیم که سایر اشکال کوانتیزاسیون، فشرده سازی و پراکندگی را می توان اعمال کرد (به عنوان مثال، تقطیر، تقطیر، پراکندگی و غیره). ما امیدواریم که کار آینده به کارگیری روشهای کوانتیزهسازی و فشردهسازی تهاجمیتر را مد نظر قرار دهد، که ممکن است مزایای بیشتری برای عملکرد و دقت بهدستآمده از سیاستهای آموزشدیده RL داشته باشد.
قدردانی
مایلیم از نویسندگان همکارمان مکس لام، شاراد چیتلانگیا، زیشن وان و ویجی جاناپا ردی (دانشگاه هاروارد) و گابریل بارت مارون (دیپ مایند) به خاطر مشارکتشان در این کار تشکر کنیم. ما همچنین از تیم Google Cloud برای ارائه اعتبارات تحقیقاتی برای شروع این کار تشکر می کنیم.