
درک زیبایی شناختی و کیفیت فنی تصاویر برای ارائه یک تجربه بصری بهتر کاربر مهم است. ارزیابی کیفیت تصویر (IQA) از مدل ها برای ایجاد پلی بین تصویر و درک ذهنی کاربر از کیفیت آن استفاده می کند. در عصر یادگیری عمیق، بسیاری از رویکردهای IQA، مانند NIMA، با استفاده از قدرت شبکههای عصبی کانولوشنال (CNN) به موفقیت دست یافتهاند. با این حال، مدلهای IQA مبتنی بر CNN اغلب توسط نیاز ورودی با اندازه ثابت در آموزش دستهای محدود میشوند، به عنوان مثال، اندازه تصاویر ورودی باید تغییر اندازه داده شود یا به یک شکل اندازه ثابت برش داده شود. این پیش پردازش برای IQA مشکل ساز است زیرا تصاویر می توانند نسبت ابعاد و وضوح بسیار متفاوتی داشته باشند. تغییر اندازه و برش می تواند بر ترکیب تصویر تأثیر بگذارد یا اعوجاج ایجاد کند، بنابراین کیفیت تصویر را تغییر می دهد.
 |
| در مدلهای مبتنی بر CNN، برای آموزش دستهای، اندازه تصاویر باید تغییر اندازه داده یا به شکل ثابتی برش داده شوند. با این حال، چنین پیش پردازشی می تواند نسبت ابعاد و ترکیب تصویر را تغییر دهد و در نتیجه بر کیفیت تصویر تأثیر بگذارد. تصویر اصلی تحت مجوز CC BY 2.0 استفاده شده است. |
در “MUSIQ: Multi-scale Image Quality Transformer” منتشر شده در ICCV 2021، ما یک ترانسفورماتور کیفیت تصویر چند مقیاسی مبتنی بر وصله (MUSIQ) را برای دور زدن محدودیت های CNN در اندازه ورودی ثابت و پیش بینی کیفیت تصویر به طور موثر در بومی پیشنهاد می کنیم. تصاویر با وضوح مدل MUSIQ از پردازش ورودیهای تصویر با اندازه کامل با نسبتها و وضوحهای متفاوت پشتیبانی میکند و امکان استخراج ویژگیهای چند مقیاسی را برای ثبت کیفیت تصویر در دانهبندیهای مختلف فراهم میکند. برای پشتیبانی از رمزگذاری موقعیتی در نمایش چند مقیاسی، ما یک جاسازی فضایی دوبعدی مبتنی بر هش جدید همراه با تعبیهای که مقیاس تصویر را ثبت میکند، پیشنهاد میکنیم. ما MUSIQ را روی چهار مجموعه داده IQA در مقیاس بزرگ به کار میبریم، و نتایج پیشرفتهای را در سه مجموعه داده با کیفیت فنی (PaQ-2-PiQ، KonIQ-10k و SPAQ) و عملکرد قابل مقایسه با عملکرد پیشرفته نشان میدهیم. مدلهای هنری در مجموعه دادههای با کیفیت زیباشناختی AVA.
 |
| مدل MUSIQ مبتنی بر پچ میتواند تصویر در اندازه کامل را پردازش کند و ویژگیهای چند مقیاسی را استخراج کند، که بهتر با پاسخ بصری معمولی یک فرد هماهنگ میشود. |
در شکل زیر، نمونه ای از تصاویر، امتیاز MUSIQ و میانگین امتیاز نظر آنها (MOS) را از چندین ارزیابی کننده انسانی در پرانتز نشان می دهیم. دامنه امتیاز از 0 تا 100 است که 100 بالاترین کیفیت درک شده است. همانطور که از شکل می بینیم، MUSIQ امتیازات بالایی را برای تصاویری با کیفیت زیبایی شناختی بالا و کیفیت فنی بالا پیش بینی می کند و برای تصاویری که از نظر زیبایی خوشایند نیستند (کیفیت زیبایی شناسی پایین) یا حاوی اعوجاج های قابل مشاهده (کیفیت فنی پایین) امتیاز پایین را پیش بینی می کند. .
| امتیاز MUSIQ پیش بینی شده (و حقیقت پایه) روی تصاویر مجموعه داده KonIQ-10k. بالا: MUSIQ نمرات بالا را برای تصاویر با کیفیت بالا پیش بینی می کند. میانه: MUSIQ امتیازات پایینی را برای تصاویر با کیفیت زیبایی شناختی پایین، مانند تصاویر با ترکیب بندی یا نور ضعیف، پیش بینی می کند. پایین: MUSIQ نمرات پایین را برای تصاویر با کیفیت فنی پایین، مانند تصاویر با مصنوعات اعوجاج قابل مشاهده (به عنوان مثال، تار، نویز) پیش بینی می کند. |
ترانسفورماتور کیفیت تصویر چند مقیاسی
MUSIQ با چالش یادگیری IQA در تصاویر با اندازه کامل مقابله می کند. برخلاف مدلهای CNN که اغلب محدود به وضوح ثابت هستند، MUSIQ میتواند ورودیهایی را با نسبتها و وضوحهای دلخواه مدیریت کند.
برای انجام این کار، ابتدا یک نمایش چند مقیاسی از تصویر ورودی ایجاد میکنیم که حاوی تصویر وضوح اصلی و انواع تغییر اندازه آن است. برای حفظ ترکیب بندی تصویر، نسبت تصویر آن را در طول تغییر اندازه حفظ می کنیم. پس از به دست آوردن هرم تصاویر، تصاویر را در مقیاس های مختلف به تکه هایی با اندازه ثابت تقسیم می کنیم که به مدل وارد می شوند.
 |
| تصویر نمایش تصویر چند مقیاسی در MUSIQ. |
از آنجایی که وصلهها از تصاویری با وضوحهای مختلف هستند، ما باید ورودی چند مقیاسی با نسبت چند وجهی را به طور مؤثری در یک دنباله از نشانهها رمزگذاری کنیم و اطلاعات پیکسل، فضایی و مقیاس را ضبط کنیم. برای رسیدن به این هدف، ما سه جزء رمزگذاری را در MUSIQ طراحی میکنیم، از جمله: 1) یک ماژول رمزگذاری وصله برای رمزگذاری وصلههای استخراج شده از نمایش چند مقیاسی. 2) یک ماژول جاسازی فضایی مبتنی بر هش جدید برای رمزگذاری موقعیت فضایی دو بعدی برای هر پچ. و 3) تعبیه مقیاس قابل یادگیری برای رمزگذاری مقیاس های مختلف. به این ترتیب، میتوانیم ورودی چند مقیاسی را بهعنوان دنبالهای از توکنها، بهعنوان ورودی رمزگذار Transformer رمزگذاری کنیم.
برای پیشبینی امتیاز نهایی کیفیت تصویر، از رویکرد استاندارد آماده کردن یک «نشان طبقهبندی» (CLS) اضافی استفاده میکنیم. وضعیت نشانه CLS در خروجی رمزگذار ترانسفورماتور به عنوان نمایش تصویر نهایی عمل می کند. سپس یک لایه کاملا متصل در بالا اضافه می کنیم تا IQS را پیش بینی کنیم. شکل زیر نمای کلی از مدل MUSIQ را نشان می دهد.
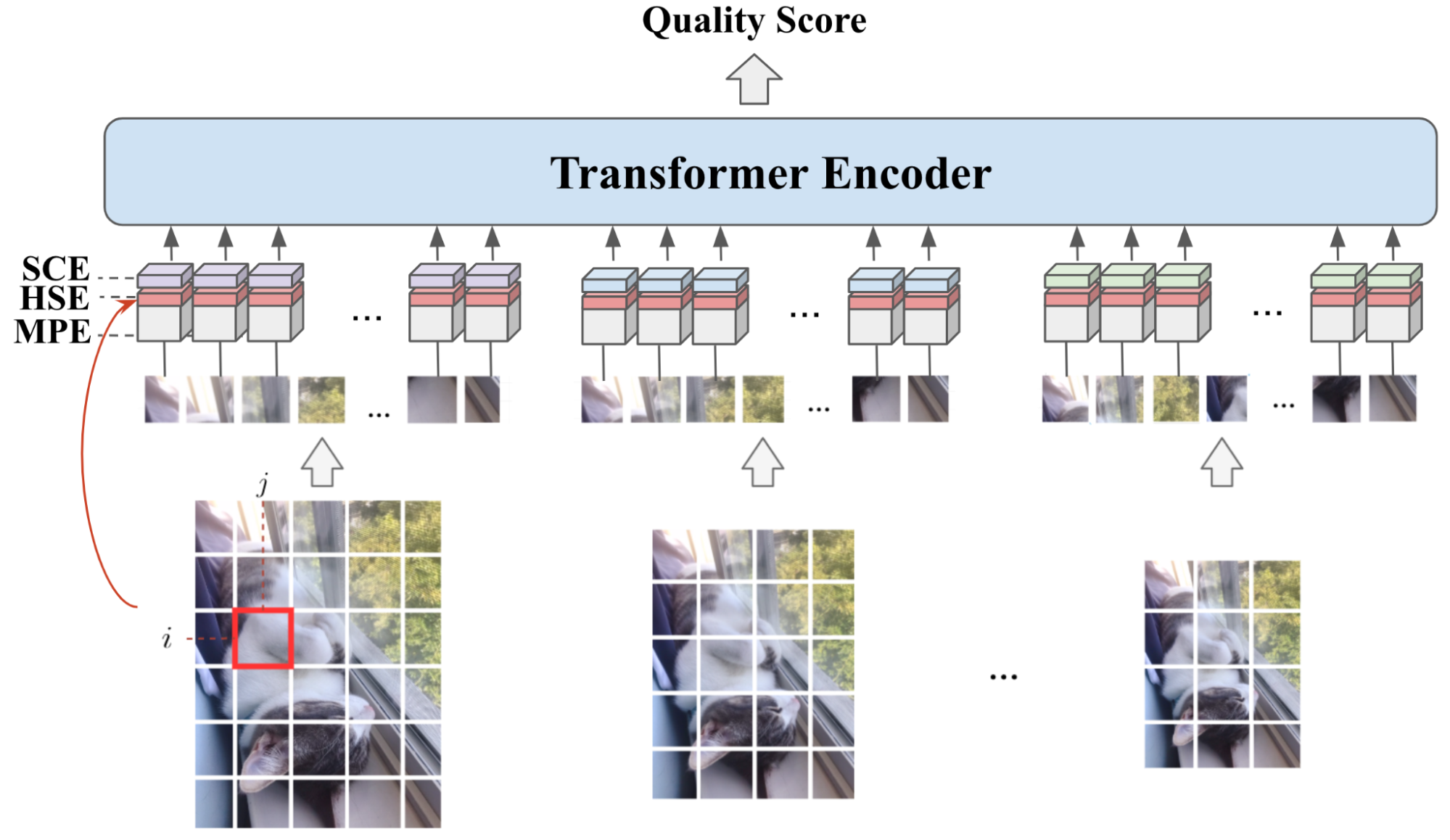 |
| مروری بر MUSIQ. ورودی چند مقیاسی با وضوح چندگانه توسط سه جزء رمزگذاری میشود: تعبیه مقیاس (SCE)، تعبیه فضایی دوبعدی مبتنی بر هش (HSE)، و تعبیه وصله چند مقیاسی (MPE). |
از آنجایی که MUSIQ فقط رمزگذاری ورودی را تغییر می دهد، با هر نوع ترانسفورماتور سازگار است. برای نشان دادن اثربخشی روش پیشنهادی، در آزمایشهای خود از ترانسفورماتور کلاسیک با تنظیم نسبتاً سبک وزن استفاده میکنیم تا اندازه مدل با ResNet-50 قابل مقایسه باشد.
معیار و ارزیابی
برای ارزیابی MUSIQ، آزمایشهایی را روی مجموعه دادههای IQA در مقیاس بزرگ اجرا میکنیم. در هر مجموعه داده، ما ضریب همبستگی رتبه اسپیرمن (SRCC) و ضریب همبستگی خطی پیرسون (PLCC) را بین پیشبینی مدل ما و میانگین امتیاز نظر ارزیابهای انسانی گزارش میکنیم. SRCC و PLCC معیارهای همبستگی هستند که از 1- تا 1 متغیر است. PLCC و SRCC بالاتر به معنای همسویی بهتر بین پیشبینی مدل و ارزیابی انسانی است. نمودار زیر نشان می دهد که MUSIQ از سایر روش ها در PaQ-2-PiQ، KonIQ-10k و SPAQ بهتر عمل می کند.
 |
| مقایسه عملکرد MUSIQ و روشهای پیشرفته قبلی (SOTA) در چهار مجموعه داده IQA در مقیاس بزرگ. در هر مجموعه داده ما ضریب همبستگی رتبه اسپیرمن (SRCC) و ضریب همبستگی خطی پیرسون (PLCC) پیشبینی مدل و حقیقت زمین را مقایسه میکنیم. |
قابل ذکر است، مجموعه تست PaQ-2-PiQ کاملاً از تصاویر بزرگی تشکیل شده است که حداقل یک بعد آنها بیش از 640 پیکسل است. این برای رویکردهای یادگیری عمیق سنتی که نیاز به تغییر اندازه دارند، بسیار چالش برانگیز است. MUSIQ می تواند با اختلاف زیادی در مجموعه آزمایشی با اندازه کامل از روش های قبلی بهتر عمل کند که استحکام و اثربخشی آن را تأیید می کند.
همچنین شایان ذکر است که روش های قبلی مبتنی بر CNN اغلب نیاز به نمونه برداری از 20 محصول برای هر تصویر در طول آزمایش داشتند. این نوع مجموعه چند محصول راهی برای کاهش محدودیت شکل ثابت در مدلهای CNN است. اما از آنجایی که هر برش فقط یک نمای فرعی از کل تصویر است، مجموعه همچنان یک رویکرد تقریبی است. علاوه بر این، روشهای مبتنی بر CNN هم هزینه استنتاج اضافی را برای هر محصول اضافه میکنند و هم به دلیل نمونهبرداری از محصولات مختلف، میتوانند تصادفی را در نتیجه معرفی کنند. در مقابل، از آنجا که MUSIQ تصویر در اندازه کامل را به عنوان ورودی می گیرد، می تواند مستقیماً بهترین تجمیع اطلاعات را در سراسر تصویر کامل بیاموزد و فقط یک بار استنتاج را اجرا کند.
برای تأیید بیشتر اینکه مدل MUSIQ اطلاعات مختلفی را در مقیاسهای مختلف ثبت میکند، وزن توجه روی هر تصویر را در مقیاسهای مختلف تجسم میکنیم.
 |
| تجسم توجه از نشانه های خروجی به نمایش چند مقیاسی، از جمله تصویر با وضوح اصلی و دو تصویر با اندازه متناسب. مناطق روشن تر نشان دهنده توجه بیشتر است، به این معنی که آن مناطق برای خروجی مدل اهمیت بیشتری دارند. تصاویر برای تصویر از مجموعه داده های AVA گرفته شده است. |
مشاهده میکنیم که MUSIQ تمایل دارد بر روی مناطق با جزئیات بیشتر در تصاویر کامل و با وضوح بالا و در مناطق جهانیتر در موارد تغییر اندازه تمرکز کند. به عنوان مثال، برای عکس گل بالا، توجه مدل به تصویر اصلی بر روی جزئیات پدال متمرکز است و توجه به جوانه ها با وضوح پایین تر معطوف می شود. این نشان می دهد که مدل یاد می گیرد که کیفیت تصویر را در دانه بندی های مختلف ثبت کند.
نتیجه
ما یک ترانسفورماتور کیفیت تصویر چند مقیاسی (MUSIQ) را پیشنهاد میکنیم، که میتواند ورودی تصویر در اندازه کامل را با وضوحها و نسبتهای تصویر متفاوت مدیریت کند. با تبدیل تصویر ورودی به یک نمایش چند مقیاسی با نمای کلی و محلی، مدل میتواند کیفیت تصویر را در دانهبندیهای مختلف ثبت کند. اگرچه MUSIQ برای IQA طراحی شده است، اما میتوان آن را در سناریوهای دیگری که برچسبهای وظایف به وضوح تصویر و نسبت ابعاد حساس هستند، اعمال کرد. مدل MUSIQ و نقاط بازرسی در مخزن GitHub ما موجود است.
سپاسگزاریها
این کار از طریق همکاری چند تیم در سراسر Google امکان پذیر شده است. مایلیم از مشارکت های قیفی وانگ، یلین وانگ و پیمان میلانفر قدردانی کنیم.