در گفتگوهای طبیعی، هر بار که با هم صحبت می کنیم، نام افراد را نمی گوییم. در عوض، ما برای شروع مکالمات به مکانیسمهای سیگنالدهی متنی تکیه میکنیم و تماس چشمی اغلب تنها چیزی است که لازم است. Google Assistant که اکنون در بیش از 95 کشور و بیش از 29 زبان در دسترس است، اساساً بر مکانیزم کلمه کلیدی (“Hey Google” یا “OK Google”) برای کمک به بیش از 700 میلیون نفر در هر ماه برای انجام کارها در دستگاه های Assistant متکی است. از آنجایی که دستیارهای مجازی به بخشی جدایی ناپذیر از زندگی روزمره ما تبدیل می شوند، ما در حال توسعه روش هایی برای شروع گفتگوها به طور طبیعی هستیم.
در Google I/O 2022، Look and Talk را معرفی کردیم، یک پیشرفت بزرگ در سفر ما برای ایجاد راههای طبیعی و شهودی برای تعامل با دستگاههای خانگی مجهز به دستیار Google. این اولین ویژگی چندوجهی دستیار روی دستگاه است که به طور همزمان صدا، ویدیو و متن را تجزیه و تحلیل میکند تا مشخص کند چه زمانی با Nest Hub Max خود صحبت میکنید. با استفاده از هشت مدل یادگیری ماشینی در کنار هم، این الگوریتم میتواند تعاملات عمدی را از نگاههای گذرا متمایز کند تا دقیقاً قصد کاربر برای تعامل با دستیار را شناسایی کند. هنگامی که در فاصله 5 فوتی دستگاه قرار گرفت، کاربر ممکن است به سادگی به صفحه نمایش نگاه کند و صحبت کند تا تعامل با دستیار را آغاز کند.
ما Look and Talk را در راستای اصول هوش مصنوعی خود توسعه دادیم. این نیازهای سختگیرانه پردازش صوتی و تصویری ما را برآورده می کند، و مانند سایر ویژگی های حسگر دوربین ما، ویدیو هرگز از دستگاه خارج نمی شود. همیشه میتوانید فعالیت «دستیار» خود را در myactivity.google.com متوقف، مرور و حذف کنید. این لایههای محافظتی اضافه شده، Look and Talk را قادر میسازد تا فقط برای کسانی که آن را روشن میکنند کار کند و در عین حال دادههای شما را ایمن نگه میدارد.
 |
| دستیار گوگل برای تعیین دقیق زمانی که کاربر با آن صحبت می کند به تعدادی سیگنال متکی است. در سمت راست فهرستی از سیگنالهای مورد استفاده با نشاندهندههایی وجود دارد که نشان میدهد هر سیگنال بر اساس نزدیکی کاربر به دستگاه و جهت نگاه کردن، چه زمانی فعال میشود. |
چالش های مدل سازی
سفر این ویژگی به عنوان یک نمونه اولیه فنی آغاز شد که بر روی مدل های توسعه یافته برای تحقیقات دانشگاهی ساخته شده بود. با این حال، استقرار در مقیاس، نیازمند حل چالشهای دنیای واقعی منحصر به فرد برای این ویژگی بود. باید:
- پشتیبانی از طیف وسیعی از ویژگی های جمعیت شناختی (به عنوان مثال، سن، رنگ پوست).
- با تنوع محیطی دنیای واقعی، از جمله روشنایی چالش برانگیز (به عنوان مثال، نور پس زمینه، الگوهای سایه) و شرایط صوتی (به عنوان مثال، طنین، نویز پس زمینه) سازگار شوید.
- با پرسپکتیوهای غیرمعمول دوربین کنار بیایید، زیرا نمایشگرهای هوشمند معمولاً به عنوان دستگاههای روی میز استفاده میشوند و بر خلاف چهرههای جلویی که معمولاً در مجموعه دادههای تحقیقاتی برای آموزش مدلها استفاده میشوند، به کاربر یا کاربران نگاه میکنند.
- برای اطمینان از پاسخهای به موقع در حین پردازش ویدیو در دستگاه، بهصورت همزمان اجرا کنید.
تکامل الگوریتم شامل آزمایشهایی با رویکردهایی از انطباق دامنه و شخصیسازی تا توسعه مجموعه دادههای خاص دامنه، آزمایش میدانی و بازخورد و تنظیم مکرر الگوریتم کلی بود.
مروری بر فناوری
تعامل نگاه و گفتگو سه مرحله دارد. در مرحله اول، دستیار از سیگنالهای بصری استفاده میکند تا تشخیص دهد که کاربر قصد تعامل با آن را نشان میدهد و سپس «بیدار میشود» تا به سخنان او گوش دهد. فاز دوم برای تایید و درک بیشتر هدف کاربر با استفاده از سیگنال های بصری و صوتی طراحی شده است. Look and Talk همه سیگنالها را در فاز اول و دوم پردازش در نظر میگیرد تا مشخص کند آیا تعامل احتمالاً برای Assistant در نظر گرفته شده است یا خیر. این دو مرحله عملکرد اصلی Look و Talk هستند و در زیر مورد بحث قرار می گیرند. مرحله سوم تکمیل پرس و جو جریان پرس و جو معمولی است و خارج از محدوده این وبلاگ است.
فاز اول: تعامل با دستیار
مرحله اول Look and Talk برای ارزیابی اینکه آیا کاربر ثبت نام شده عمداً با Assistant درگیر است یا خیر طراحی شده است. Look and Talk از تشخیص چهره برای شناسایی حضور کاربر استفاده می کند، نزدیکی را با استفاده از اندازه جعبه چهره شناسایی شده برای پی بردن به فاصله فیلتر می کند، و سپس از سیستم Face Match موجود برای تعیین اینکه آیا کاربران Look and Talk ثبت نام کرده اند استفاده می کند.
برای یک کاربر ثبت نام شده در محدوده، یک مدل نگاه سفارشی چشم تعیین می کند که آیا آنها به دستگاه نگاه می کنند یا خیر. این مدل هم زاویه نگاه و هم اطمینان دودویی نگاه به دوربین را از فریم های تصویر با استفاده از یک معماری شبکه عصبی کانولوشنال چند برج، با یک برج پردازش کل صورت و دیگری تکه های پردازشی در اطراف چشم، تخمین می زند. از آنجایی که صفحهنمایش دستگاه ناحیهای را در زیر دوربین میپوشاند که دیدن آن برای کاربر طبیعی است، زاویه نگاه و پیشبینی دودویی نگاه به دوربین را به ناحیه صفحه نمایش دستگاه ترسیم میکنیم. برای اطمینان از اینکه پیشبینی نهایی در برابر پیشبینیهای فردی جعلی و پلک زدنهای غیرارادی چشم مقاوم است، ما یک تابع هموارسازی را برای پیشبینیهای مبتنی بر فریم فردی اعمال میکنیم تا پیشبینیهای فردی جعلی را حذف کنیم.
 |
| پیش بینی نگرش چشم و بررسی اجمالی پس از پردازش |
قبل از اینکه به کاربران اطلاع دهیم که سیستم برای به حداقل رساندن محرک های نادرست آماده است، الزامات توجه سخت تری را اعمال می کنیم، به عنوان مثال، زمانی که کاربر عبوری برای مدت کوتاهی به دستگاه نگاه می کند. هنگامی که کاربر که به دستگاه نگاه می کند شروع به صحبت می کند، نیاز توجه را کاهش می دهیم و به کاربر اجازه می دهیم به طور طبیعی نگاه خود را تغییر دهد.
سیگنال نهایی لازم در این مرحله پردازش بررسی می کند که کاربر Face Matched بلندگوی فعال باشد. این توسط یک مدل تشخیص بلندگوی فعال چندوجهی ارائه میشود که هم ویدیوی چهره کاربر و هم صدای حاوی گفتار را به عنوان ورودی دریافت میکند و پیشبینی میکند که آیا صحبت میکنند یا خیر. تعدادی از تکنیکهای تقویت (از جمله RandAugment، SpecAugment، و تقویت با صداهای AudioSet) به بهبود کیفیت پیشبینی برای دامنه داخلی کمک میکند و عملکرد ویژگی نهایی را تا بیش از 10% افزایش میدهد. مدلی که از پنج فریم زمینه برای ورودی بصری و 0.5 ثانیه برای ورودی صوتی استفاده می کند.
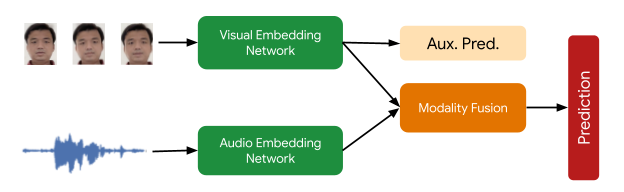 |
| نمای کلی مدل تشخیص بلندگوی فعال: مدل سمعی و بصری دو برج پیشبینی احتمال «گفتار» را برای چهره ارائه میکند. پیشبینی کمکی شبکه بصری، شبکه بصری را به بهترین شکل ممکن هدایت میکند و پیشبینی چندوجهی نهایی را بهبود میبخشد. |
فاز دوم: دستیار شروع به گوش دادن می کند
در مرحله دوم، سیستم شروع به گوش دادن به محتوای درخواست کاربر میکند، هنوز کاملاً روی دستگاه است تا ارزیابی کند که آیا این تعامل برای Assistant با استفاده از سیگنالهای اضافی در نظر گرفته شده است یا خیر. ابتدا، Look and Talk از Voice Match برای اطمینان بیشتر از ثبت نام بلندگو و مطابقت با سیگنال قبلی Face Match استفاده می کند. سپس، یک مدل پیشرفته تشخیص گفتار خودکار را روی دستگاه اجرا می کند تا گفته را رونویسی کند.
مرحله مهم پردازش بعدی، الگوریتم درک قصد است که پیش بینی می کند آیا گفته کاربر به عنوان یک جستجوی دستیار در نظر گرفته شده است یا خیر. این دو بخش دارد: 1) مدلی که اطلاعات غیر واژگانی موجود در صدا (یعنی زیر و بم، سرعت، صداهای تردید) را تجزیه و تحلیل میکند تا تعیین کند که آیا گفته مانند یک جستجوی دستیار به نظر میرسد یا خیر، و 2) یک مدل تجزیه و تحلیل متن که تعیین میکند آیا رونوشت یک درخواست دستیار است. اینها با هم، جستارهایی را که برای «دستیار» در نظر گرفته نشدهاند، فیلتر میکنند. همچنین از سیگنالهای بصری متنی برای تعیین احتمال اینکه این تعامل برای Assistant در نظر گرفته شده است، استفاده میکند.
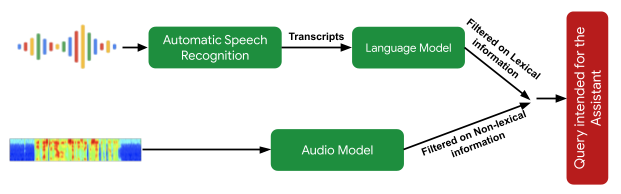 |
| بررسی اجمالی رویکرد فیلتر معنایی برای تعیین اینکه آیا یک گفته کاربر یک جستجوی در نظر گرفته شده برای دستیار است یا خیر. |
در نهایت، زمانی که مدل درک قصد مشخص میکند که گفته کاربر احتمالاً برای Assistant در نظر گرفته شده است، Look and Talk به مرحله تکمیل حرکت میکند که در آن با سرور Assistant ارتباط برقرار میکند تا پاسخی به منظور و متن درخواست کاربر دریافت کند.
عملکرد، شخصی سازی و UX
هر مدلی که از Look and Talk پشتیبانی میکند، به صورت مجزا ارزیابی و بهبود یافته و سپس در سیستم Look and Talk end-to-end مورد آزمایش قرار گرفت. تنوع بسیار زیاد شرایط محیطی که Look and Talk در آن کار می کند، نیاز به معرفی پارامترهای شخصی سازی برای استحکام الگوریتم دارد. با استفاده از سیگنالهای بهدستآمده در طول تعاملات مبتنی بر کلمه کلیدی کاربر، سیستم پارامترها را برای کاربران فردی شخصیسازی میکند تا بهبودهایی را نسبت به مدل کلی تعمیمیافته ارائه دهد. این شخصیسازی نیز کاملاً روی دستگاه اجرا میشود.
بدون یک کلمه کلیدی از پیش تعریف شده به عنوان یک پروکسی برای قصد کاربر، تأخیر یک نگرانی مهم برای Look and Talk بود. اغلب، یک سیگنال تعاملی به اندازه کافی قوی تا زمانی که کاربر شروع به صحبت نکرده است، رخ نمی دهد، که می تواند صدها میلی ثانیه تاخیر اضافه کند، و مدل های موجود برای درک قصد به این امر اضافه می کنند، زیرا به پرس و جوهای کامل و نه جزئی نیاز دارند. برای پر کردن این شکاف، Look and Talk به طور کامل از پخش صدا به سرور صرف نظر میکند و رونویسی و درک هدف روی دستگاه وجود دارد. مدلهای درک قصد میتوانند از جملات جزئی کار کنند. این منجر به تأخیر سرتاسر قابل مقایسه با سیستمهای مبتنی بر کلمه کلیدی فعلی میشود.
تجربه رابط کاربری مبتنی بر تحقیقات کاربر برای ارائه بازخورد بصری متعادل با قابلیت یادگیری بالا است. این در شکل زیر نشان داده شده است.
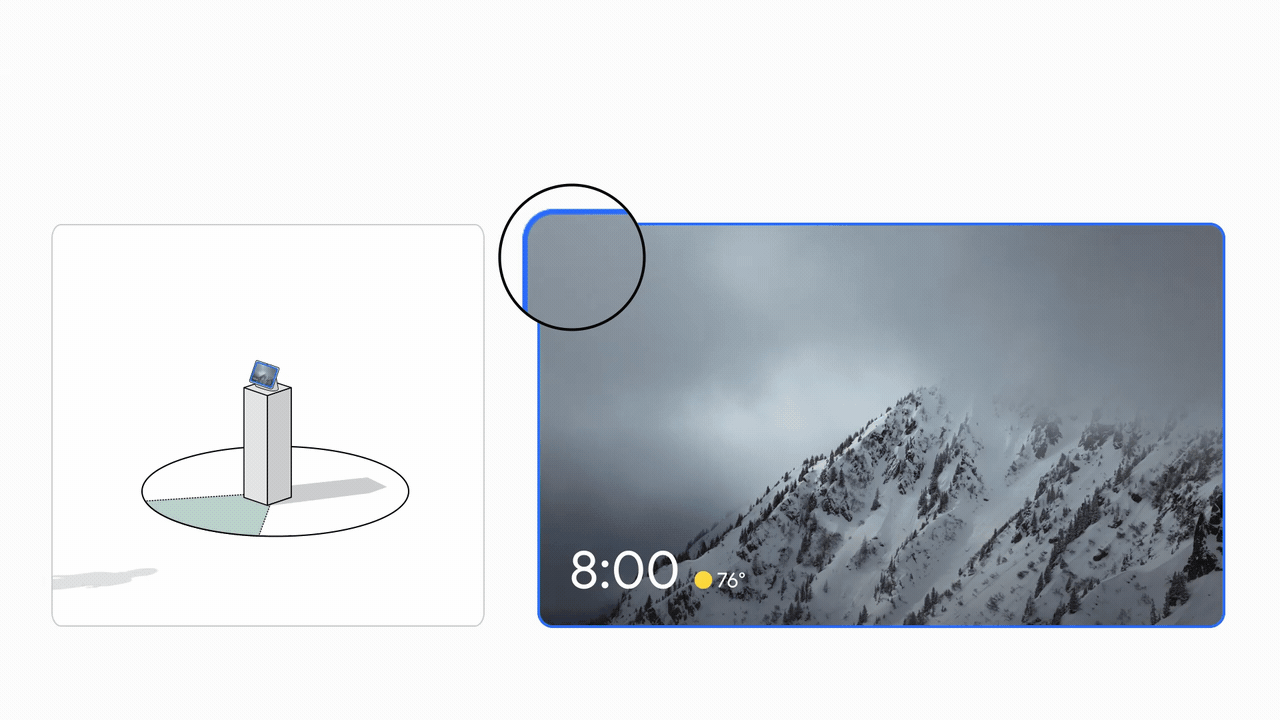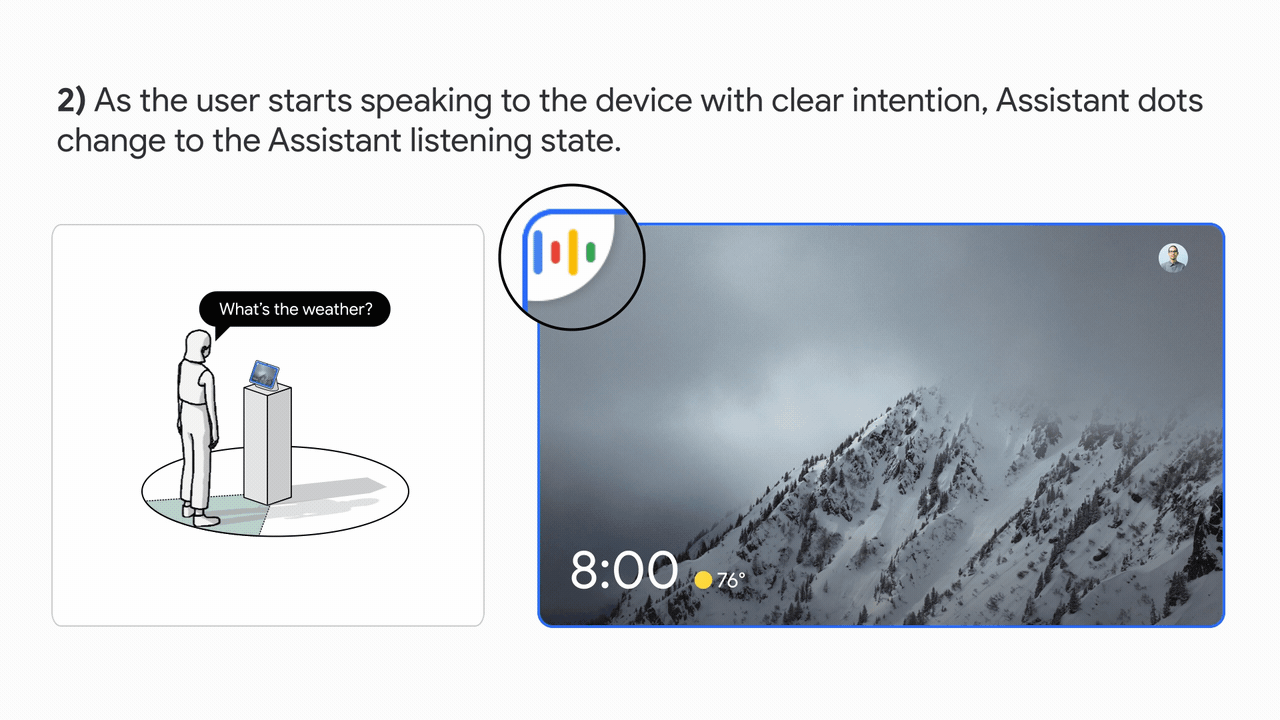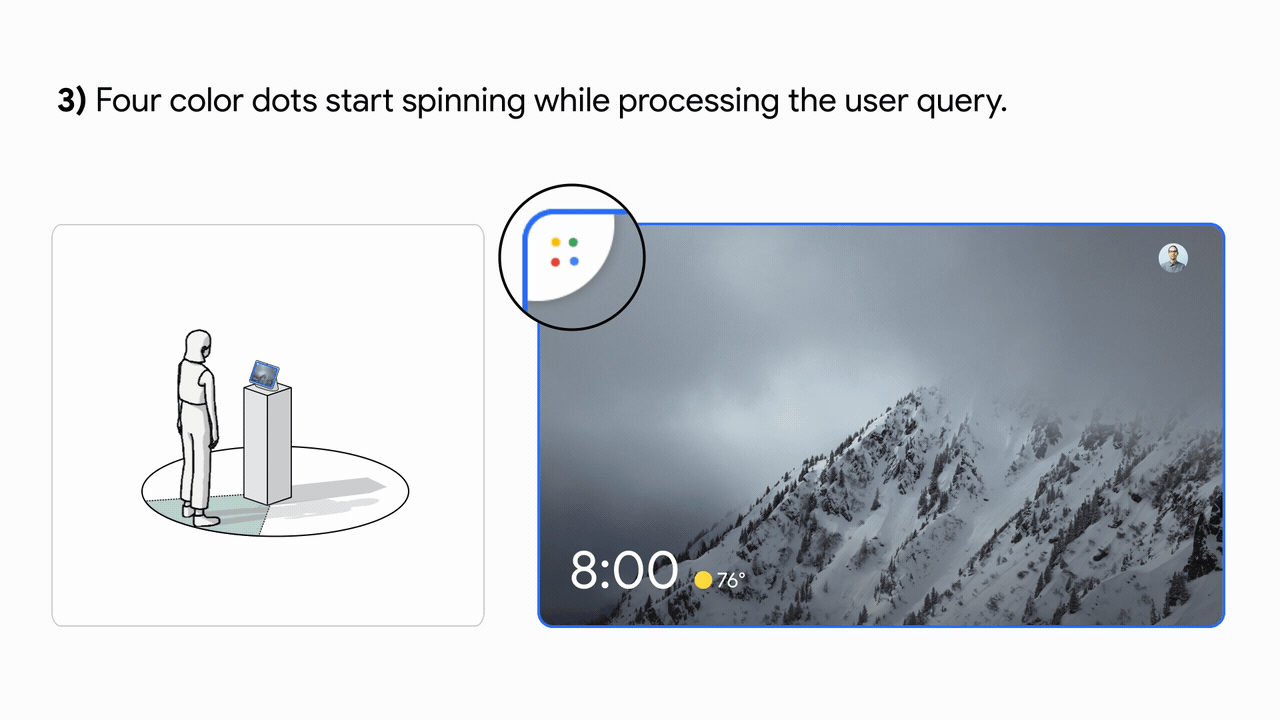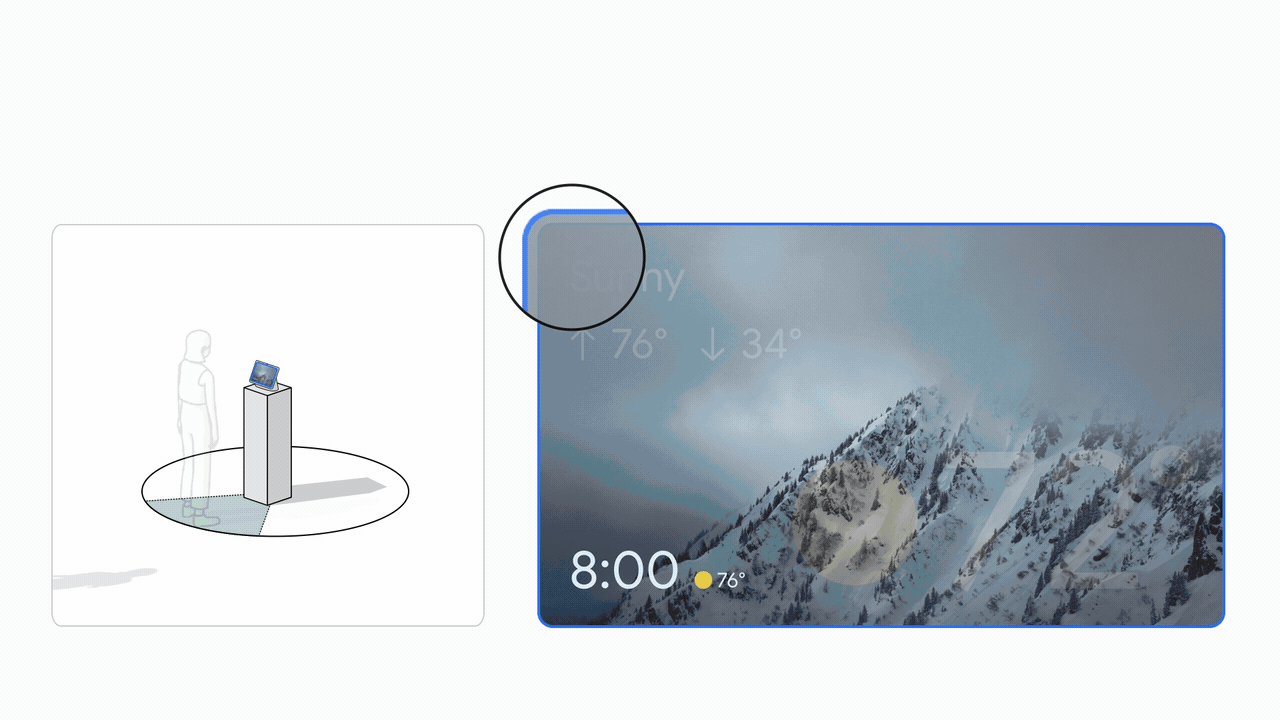 |
| ترک کرد: نمودار تعامل فضایی کاربری که با Look and Talk درگیر است. درست: تجربه رابط کاربری (UI). |
ما یک مجموعه داده ویدیویی متنوع با بیش از 3000 شرکتکننده برای آزمایش این ویژگی در زیر گروههای جمعیتی ایجاد کردیم. پیشرفتهای مدلسازی ناشی از تنوع در دادههای آموزشی ما، عملکرد همه زیرگروهها را بهبود بخشید.
نتیجه
Look and Talk گامی مهم در جهت طبیعی کردن تعامل کاربر با دستیار Google است. در حالی که این یک نقطه عطف کلیدی در سفر ما است، امیدواریم این اولین پیشرفت از بسیاری از الگوهای تعاملی ما باشد که به تجسم مجدد تجربه Google Assistant به طور مسئولانه ادامه خواهد داد. هدف ما این است که دریافت کمک را طبیعی و آسان کنیم و در نهایت در زمان صرفه جویی کنیم تا کاربران بتوانند روی چیزهایی که بیشترین اهمیت را دارند تمرکز کنند.
سپاسگزاریها
این کار شامل تلاشهای مشترک از یک تیم چند رشتهای متشکل از مهندسان نرمافزار، محققان، UX و مشارکتکنندگان متقابل بود. مشارکت کنندگان کلیدی از دستیار Google عبارتند از: الکسی گالاتا، آلیس چوانگ، باربارا وانگ، بریتانیای هال، گابریل لبلانک، گلوریا مک گی، هیداکی ماتسوی، جیمز زانونی، جوآنا (کیونگ) هوانگ، کرونال شاه، کاویتا کانداپان، پدرو سیلوا، تانیا سینها تووان، نگوین، ویشال دسای، ویل تروونگ، ییکسینگ کای، یونفان یه؛ از تحقیقاتی از جمله هائو وو، جوزف راث، ساگار ساولا، سوریش چاودوری، سوزانا ریکو. از یوان یوان و کارولین پانتوفارو برای رهبریشان و همه اعضای تیمهای Nest، Assistant و Research که اطلاعات ارزشمندی را برای توسعه Look and Talk ارائه کردند، تشکر میکنیم.