در حالی که طراحی مدل و داده های آموزشی اجزای کلیدی موفقیت شبکه عصبی عمیق (DNN) هستند، روش بهینه سازی خاص مورد استفاده برای به روز رسانی پارامترهای مدل (وزن) کمتر مورد بحث قرار می گیرد. آموزش DNN ها شامل به حداقل رساندن یک تابع ضرر است که اختلاف بین برچسب های حقیقت زمین و پیش بینی های مدل را اندازه گیری می کند. آموزش با انتشار پسانداز انجام میشود که وزن مدل را از طریق مراحل نزول گرادیان تنظیم میکند. شیب نزول، به نوبه خود، وزن ها را با استفاده از گرادیان (یعنی مشتق) کاهش نسبت به وزن ها به روز می کند.
ساده ترین به روز رسانی وزن مربوط به نزول گرادیان تصادفی است، که در هر مرحله، وزن ها را در جهت منفی با توجه به گرادیان ها حرکت می دهد (با اندازه گام مناسب، با نام مستعار نرخ یادگیری). روشهای بهینهسازی پیشرفتهتر، جهت گرادیان منفی را قبل از بهروزرسانی وزنها با استفاده از اطلاعات مراحل گذشته و/یا ویژگیهای محلی (مانند اطلاعات انحنا) تابع تلفات حول وزنهای فعلی تغییر میدهند. برای مثال، یک بهینهساز حرکت حرکت در جهت میانگین بهروزرسانیهای گذشته را تشویق میکند، و بهینهساز AdaGrad هر مختصات را بر اساس گرادیانهای گذشته مقیاس میدهد. این بهینه سازها معمولاً به عنوان شناخته می شوند روش های مرتبه اول از آنجایی که آنها به طور کلی جهت به روز رسانی را فقط با استفاده از اطلاعات مشتق مرتبه اول (یعنی گرادیان) تغییر می دهند. مهمتر از آن، اجزای پارامترهای وزن به طور مستقل از یکدیگر درمان می شوند.
بهینه سازی پیشرفته تر، مانند شامپو و K-FAC، همبستگی بین گرادیان پارامترها را نشان می دهد و نشان داده شده است که همگرایی را بهبود می بخشد، تعداد تکرارها را کاهش می دهد و کیفیت راه حل را بهبود می بخشد. این روش ها اطلاعاتی را در مورد تغییرات محلی مشتقات زیان، به عنوان مثال، تغییرات در گرادیان ها جمع آوری می کنند. با استفاده از این اطلاعات اضافی، بهینه سازهای مرتبه بالاتر می توانند جهت به روز رسانی بسیار کارآمدتری را برای مدل های آموزشی با در نظر گرفتن همبستگی بین گروه های مختلف پارامترها کشف کنند. از جنبه منفی، محاسبه جهتهای بهروزرسانی مرتبه بالاتر از نظر محاسباتی گرانتر از بهروزرسانیهای مرتبه اول است. این عملیات از حافظه بیشتری برای ذخیرهسازی آمار استفاده میکند و شامل وارونگی ماتریس میشود، بنابراین مانع از کاربرد بهینهسازهای مرتبه بالاتر در عمل میشود.
در “LocoProp: Enhancing BackProp از طریق Local Loss Optimization”، ما یک چارچوب جدید برای آموزش مدل های DNN معرفی می کنیم. چارچوب جدید ما، CrazyProp، شبکه های عصبی را به عنوان یک ترکیب مدولار از لایه ها تصور می کند. به طور کلی، هر لایه در یک شبکه عصبی یک تبدیل خطی روی ورودیهای خود اعمال میکند و به دنبال آن یک تابع فعالسازی غیرخطی اعمال میشود. در ساخت جدید، به هر لایه تنظیم کننده وزن، هدف خروجی و عملکرد کاهش اختصاص داده شده است. تابع از دست دادن هر لایه طراحی شده است همخوانی داشتن عملکرد فعال سازی لایه با استفاده از این فرمول، آموزش تلفات محلی را برای یک سری کوچک از نمونهها به صورت تکراری و موازی در بین لایهها به حداقل میرساند. روش ما بهروزرسانیهای محلی متعدد را در هر دسته از نمونهها با استفاده از یک بهینهساز مرتبه اول (مانند RMSProp) انجام میدهد، که از عملیات محاسباتی پرهزینه مانند وارونگیهای ماتریس مورد نیاز برای بهینهسازهای مرتبه بالاتر اجتناب میکند. با این حال، نشان میدهیم که بهروزرسانیهای محلی ترکیبی بیشتر شبیه بهروزرسانیهای مرتبه بالاتر هستند. از نظر تجربی، ما نشان میدهیم که LocoProp از روشهای مرتبه اول بر روی یک معیار رمزگذار خودکار عمیق بهتر عمل میکند و عملکرد قابل مقایسه با بهینهسازهای مرتبه بالاتر، مانند شامپو و K-FAC، بدون نیاز به حافظه و محاسبات بالا دارد.
روش
شبکه های عصبی به طور کلی به عنوان توابع ترکیبی در نظر گرفته می شوند که ورودی های مدل را به نمایش های خروجی، لایه به لایه تبدیل می کنند. LocoProp این دیدگاه را در حالی که شبکه را به لایه ها تجزیه می کند، اتخاذ می کند. به طور خاص، به جای به روز رسانی وزن لایه برای به حداقل رساندن تابع تلفات در خروجی، LocoProp توابع تلفات محلی از پیش تعریف شده را برای هر لایه اعمال می کند. برای یک لایه معین، تابع ضرر برای مطابقت با تابع فعال سازی انتخاب می شود، به عنوان مثال، a ماهی ضرر برای لایه ای با a انتخاب می شود ماهی فعال سازی هر تلفات لایه ای، اختلاف بین خروجی لایه (برای یک سری کوچک از نمونه های معین) و مفهومی از یک لایه را اندازه گیری می کند. خروجی هدف برای آن لایه بهعلاوه، یک اصطلاح تنظیمکننده تضمین میکند که وزنهای بهروز شده خیلی از مقادیر فعلی دور نمیشوند. تابع از دست دادن لایه ای ترکیبی (با یک هدف محلی) به علاوه تنظیم کننده به عنوان تابع هدف جدید برای هر لایه استفاده می شود.
 |
| LocoProp مشابه پس انتشار، از یک پاس رو به جلو برای محاسبه فعالسازی استفاده میکند. در گذر به عقب، LocoProp هر نورون “هدف” را برای هر لایه تنظیم می کند. در نهایت، LocoProp آموزش مدل را به مسائل مستقل در سراسر لایهها تقسیم میکند که در آن چندین بهروزرسانی محلی میتواند به صورت موازی برای وزنهای هر لایه اعمال شود. |
شاید ساده ترین تابع تلفات که می توان برای یک لایه در نظر گرفت، تلفات مجذور است. در حالی که تلفات مربع یک انتخاب معتبر از یک تابع ضرر است، LocoProp غیرخطی بودن احتمالی توابع فعالسازی لایهها را در نظر میگیرد و تلفات لایهای متناسب با تابع فعالسازی هر لایه را اعمال میکند. این مدل را قادر میسازد تا بر نواحی در ورودی تأکید کند که برای پیشبینی مدل اهمیت بیشتری دارند و در عین حال تأکیدی بر مناطقی که بر خروجی تأثیر نمیگذارند، نباشد. در زیر نمونههایی از تلفات متناسب با توابع فعالسازی tanh و ReLU را نشان میدهیم.
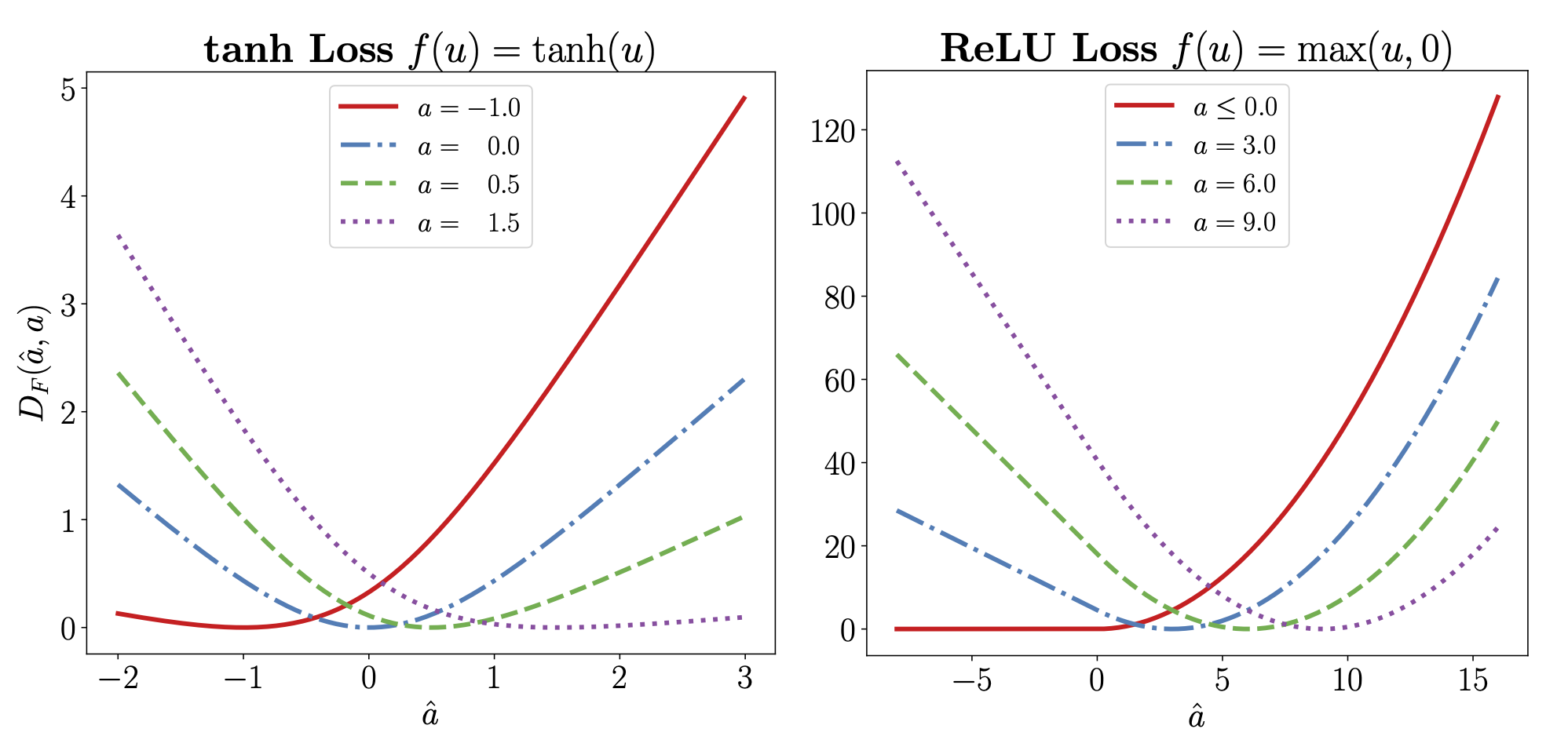 |
| توابع از دست دادن القا شده توسط (ترک کرد) تن و (درست) توابع فعال سازی ReLU. هر ضرر نسبت به مناطقی که بر پیشبینی خروجی تأثیر میگذارند حساستر است. به عنوان مثال، تا زمانی که پیشبینی (â) و هدف (a) منفی باشند، ضرر ReLU صفر است. این به این دلیل است که تابع ReLU اعمال شده برای هر عدد منفی برابر با صفر است. |
پس از تشکیل هدف در هر لایه، LocoProp وزن لایه را با اعمال مکرر مراحل نزول گرادیان روی هدف خود به روز می کند. بهروزرسانی معمولاً از یک بهینهساز مرتبه اول (مانند RMSProp) استفاده میکند. با این حال، ما نشان میدهیم که رفتار کلی بهروزرسانیهای ترکیبی شباهت زیادی به بهروزرسانیهای مرتبه بالاتر دارد (در زیر نشان داده شده است). بنابراین، LocoProp عملکرد آموزشی نزدیک به آنچه بهینهسازهای مرتبه بالاتر را بدون حافظه یا محاسبات بالا برای روشهای مرتبه بالاتر، مانند عملیات معکوس ماتریس، به دست میآورند، ارائه میکند. ما نشان میدهیم که LocoProp یک چارچوب انعطافپذیر است که امکان بازیابی الگوریتمهای شناختهشده را میدهد و ساخت الگوریتمهای جدید را از طریق انتخابهای مختلف از دست دادن، اهداف و تنظیمکنندهها امکانپذیر میسازد. نمای لایهای LocoProp از شبکههای عصبی همچنین امکان بهروزرسانی وزنها را به صورت موازی در سراسر لایهها فراهم میکند.
آزمایش
در مقاله ما، آزمایشهایی را بر روی مدل رمزگذار خودکار عمیق، که یک خط پایه معمول برای ارزیابی عملکرد الگوریتمهای بهینهسازی است، توصیف میکنیم. ما تنظیم گستردهای را روی چندین بهینهساز مرتبه اول معمولی از جمله SGD، SGD با حرکت، AdaGrad، RMSProp و Adam و همچنین بهینهسازهای شامپو و K-FAC درجه بالاتر انجام میدهیم و نتایج را با LocoProp مقایسه میکنیم. یافتههای ما نشان میدهد که روش LocoProp به طور قابلتوجهی بهتر از بهینهسازهای مرتبه اول عمل میکند و با روشهای مرتبه بالاتر قابل مقایسه است، در حالی که وقتی روی یک GPU واحد اجرا میشود، بسیار سریعتر است.
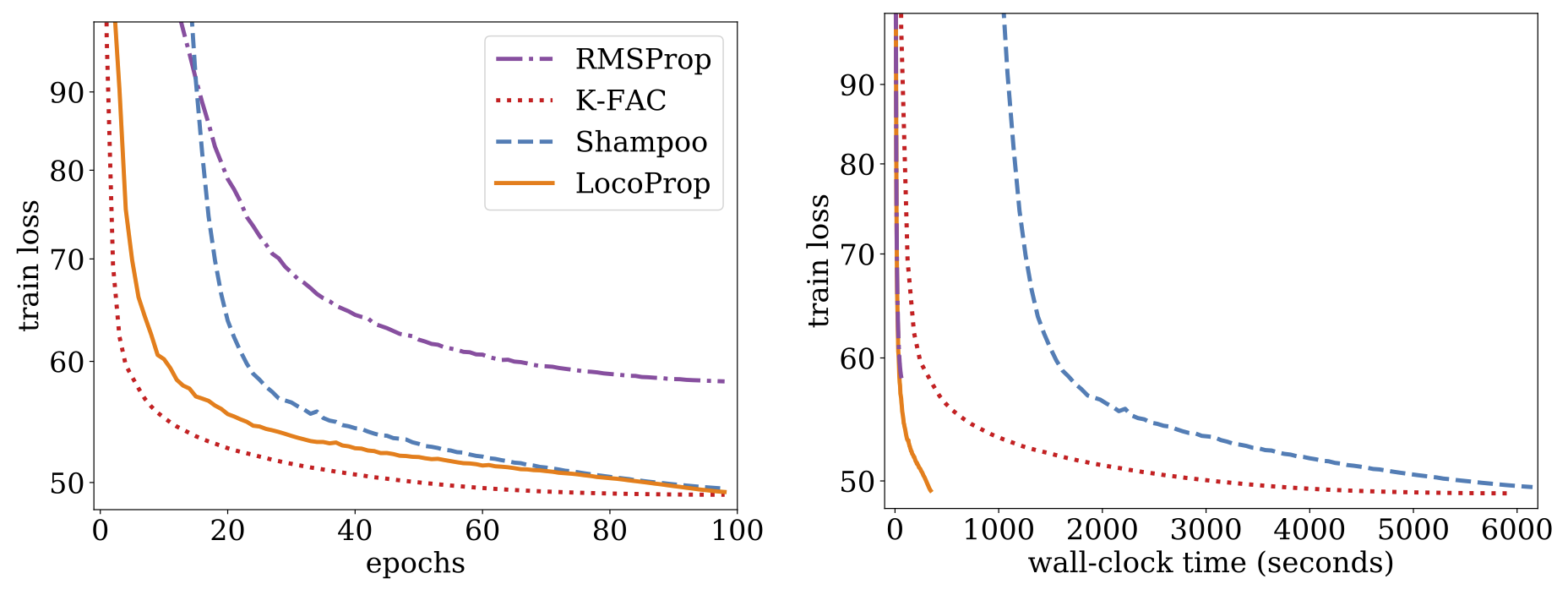 |
| از دست دادن قطار در مقابل تعداد دورهها (ترک کرد) و زمان ساعت دیواری، یعنی زمان واقعی که در طول تمرین می گذرد، (درست) برای RMSProp، شامپو، K-FAC، و LocoProp در مدل رمزگذار خودکار عمیق. |
خلاصه و مسیرهای آینده
ما یک چارچوب جدید به نام LocoProp را برای بهینه سازی شبکه های عصبی عمیق با کارآمدتر معرفی کردیم. LocoProp شبکههای عصبی را به لایههای جداگانه با تنظیمکننده، هدف خروجی و عملکرد تلفات خود تجزیه میکند و بهروزرسانیهای محلی را به صورت موازی برای به حداقل رساندن اهداف محلی اعمال میکند. در حالی که از بهروزرسانیهای مرتبه اول برای مسائل بهینهسازی محلی استفاده میشود، بهروزرسانیهای ترکیبی از لحاظ نظری و تجربی بسیار شبیه دستورالعملهای بهروزرسانی مرتبه بالاتر هستند.
LocoProp انعطافپذیری را برای انتخاب منظمکنندههای لایهای، اهداف و توابع از دست دادن فراهم میکند. بنابراین، امکان توسعه قوانین به روز رسانی جدید را بر اساس این انتخاب ها فراهم می کند. کد ما برای LocoProp به صورت آنلاین در GitHub در دسترس است. ما در حال حاضر در حال کار بر روی مقیاس بندی ایده های القا شده توسط LocoProp به مدل های بسیار بزرگتر هستیم. گوش به زنگ باشید!
قدردانی ها
مایلیم از نویسنده همکارمان، Manfred K. Warmuth، برای مشارکت های انتقادی و دیدگاه الهام بخشش تشکر کنیم. مایلیم از سامیر آگاروال برای بحث هایی که به این اثر از منظر توابع ترکیبی نگاه می کند، وینیت گوپتا برای بحث و توسعه شامپو، زکری نادو در K-FAC، تام اسمال برای توسعه انیمیشن مورد استفاده در این وبلاگ و در نهایت از یونگهوی تشکر کنیم. وو و ذوبین قهرمانی به دلیل ارائه یک محیط تحقیقاتی پرورش دهنده در تیم Google Brain.