به روز رسانی – 2022/09/06: این پست برای حذف عبارتی در مورد کاهش مشاهده شده در سوئیچهای زمینه که نمیتوان آن را با اهمیت آماری تأیید کرد، بهروزرسانی شده است.
افزایش پیچیدگی کد چالشی کلیدی برای بهره وری در مهندسی نرم افزار ایجاد می کند. تکمیل کد یک ابزار ضروری بوده است که به کاهش این پیچیدگی در محیط های توسعه یکپارچه (IDE) کمک کرده است. به طور متعارف، پیشنهادات تکمیل کد با موتورهای معنایی مبتنی بر قانون (SEs)، که معمولاً به مخزن کامل دسترسی دارند و ساختار معنایی آن را درک میکنند، پیادهسازی میشوند. تحقیقات اخیر نشان داده است که مدلهای زبان بزرگ (مثلا Codex و PalM) پیشنهادهای کد طولانیتر و پیچیدهتری را امکانپذیر میکنند و در نتیجه محصولات مفیدی پدیدار شدهاند (مانند Copilot). با این حال، این سوال که چگونه تکمیل کد توسط یادگیری ماشینی (ML) بر بهرهوری توسعهدهنده تأثیر میگذارد، فراتر از بهرهوری درک شده و پیشنهادات پذیرفتهشده، همچنان باز است.
امروز توضیح میدهیم که چگونه ML و SE را برای ایجاد یک تکمیل کد ترکیبی معنایی ML مبتنی بر Transformer جدید که اکنون برای توسعهدهندگان داخلی Google در دسترس است، ترکیب کردیم. ما در مورد اینکه چگونه ML و SE ها را می توان با (1) رتبه بندی مجدد پیشنهادات توکن SE با استفاده از ML، (2) اعمال تکمیل های تک خطی و چند خطی با استفاده از ML و بررسی صحت با SE، یا (3) با استفاده از تک و ادامه چند خطی توسط ML پیشنهادهای معنایی تک نشانه. ما تکمیل کد ML معنایی ترکیبی بیش از 10 هزار کاربر Google (بیش از سه ماه در هشت زبان برنامهنویسی) را با یک گروه کنترل مقایسه میکنیم و شاهد کاهش 6 درصدی در زمان تکرار کدنویسی (زمان بین ساختها و آزمایشها) هستیم. هنگامی که در معرض تکمیل تک خطی ML قرار می گیرد. این نتایج نشان میدهد که ترکیب ML و SE میتواند بهرهوری توسعهدهنده را بهبود بخشد. در حال حاضر، 3 درصد از کدهای جدید (اندازه گیری شده در نویسه) اکنون از پذیرش پیشنهادات تکمیل ML ایجاد می شود.
ترانسفورماتور برای تکمیل
یک رویکرد رایج برای تکمیل کد، آموزش مدلهای ترانسفورماتور است که از مکانیزم خودتوجهی برای درک زبان استفاده میکنند تا درک کد و پیشبینی تکمیل را فعال کنند. ما کدی شبیه به زبان را که با نشانههای زیرکلمه و واژگان SentencePiece نشان داده شده است، در نظر میگیریم و از مدلهای ترانسفورماتور رمزگذار-رمزگشا که روی TPU ها اجرا میشوند برای پیشبینی تکمیل استفاده میکنیم. ورودی کدی است که مکان نما را احاطه کرده است (~1000-2000 توکن) و خروجی مجموعه ای از پیشنهادات برای تکمیل خط جاری یا چند خط است. توالی ها با جستجوی پرتو (یا کاوش درختی) روی رمزگشا ایجاد می شوند.
در طول آموزش مونورپو گوگل، ما باقیمانده یک خط و برخی از خطوط بعدی را پنهان می کنیم تا کدی را که به طور فعال در حال توسعه است، تقلید کنیم. ما یک مدل را بر روی هشت زبان (C++، جاوا، پایتون، Go، Typescript، Proto، Kotlin و Dart) آموزش میدهیم و عملکرد بهبودیافته یا برابر را در همه زبانها مشاهده میکنیم و نیاز به مدلهای اختصاصی را از بین میبریم. علاوه بر این، متوجه شدیم که اندازه مدل از پارامترهای ~ 0.5B یک معاوضه خوب برای دقت پیشبینی بالا با تأخیر کم و هزینه منابع ارائه میکند. این مدل به شدت از کیفیت monorepo سود می برد که توسط دستورالعمل ها و بررسی ها اعمال می شود. برای پیشنهادات چند خطی، ما به طور مکرر از مدل تک خطی با آستانه های آموخته شده برای تصمیم گیری در مورد شروع پیش بینی تکمیل برای خط زیر استفاده می کنیم.
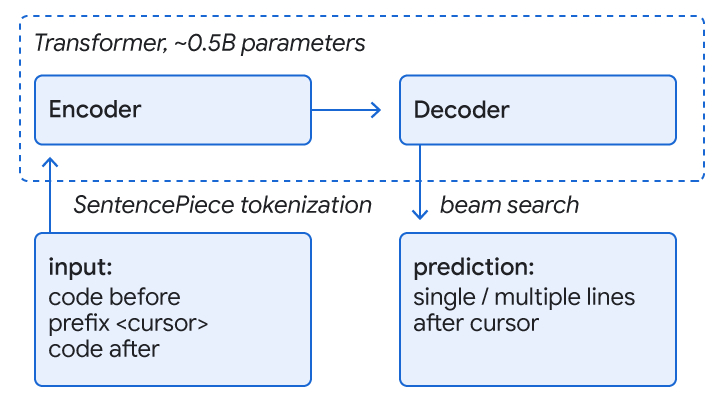 |
| مدل های ترانسفورماتور رمزگذار – رمزگشا برای پیش بینی باقی مانده خط یا خطوط کد استفاده می شود. |
رتبه بندی مجدد پیشنهادات توکن با ML
در حالی که کاربر در حال تایپ در IDE است، تکمیل کد به صورت تعاملی از مدل ML و SE به طور همزمان در backend درخواست می شود. SE معمولاً فقط یک توکن را پیشبینی میکند. مدلهای ML که استفاده میکنیم چندین توکن را تا پایان خط پیشبینی میکنند، اما ما فقط اولین نشانه را برای مطابقت با پیشبینیهای SE در نظر میگیریم. ما سه پیشنهاد برتر ML را که در پیشنهادات SE نیز موجود است شناسایی کرده و رتبه آنها را به بالاترین سطح ارتقا می دهیم. سپس نتایج رتبه بندی مجدد به عنوان پیشنهادهایی برای کاربر در IDE نشان داده می شود.
در عمل، SE های ما در فضای ابری اجرا می شوند و خدمات زبانی (به عنوان مثال، تکمیل معنایی، تشخیص و غیره) را ارائه می دهند که توسعه دهندگان با آن آشنا هستند، و بنابراین ما SE ها را برای اجرا در همان مکان هایی که TPU ها استنتاج ML را انجام می دهند، قرار دادیم. SE ها بر اساس یک کتابخانه داخلی هستند که ویژگی های کامپایلر مانند را با تاخیر کم ارائه می دهد. با توجه به تنظیمات طراحی، که در آن درخواستها به صورت موازی انجام میشوند و ML معمولاً سریعتر ارائه میشود (میانگین ~40 میلیثانیه)، ما هیچ تأخیری به تکمیلها اضافه نمیکنیم. ما شاهد بهبود کیفیت قابل توجهی در استفاده واقعی هستیم. برای 28 درصد تکمیلهای پذیرفتهشده، رتبه تکمیل به دلیل تقویت بالاتر و در 0.4 درصد موارد بدتر است. علاوه بر این، متوجه میشویم که کاربران قبل از پذیرش پیشنهاد تکمیل، نویسههای >10% کمتری را تایپ میکنند.
تکمیلهای ML تکخطی/چند خطی را برای صحت معنایی بررسی کنید
در زمان استنتاج، مدلهای ML معمولاً از کدهای خارج از پنجره ورودی خود بیاطلاع هستند و کدی که در طول آموزش مشاهده میشود ممکن است افزودههای اخیر مورد نیاز برای تکمیل در مخازن فعال در حال تغییر را از دست بدهد. این منجر به یک اشکال رایج در تکمیل کد مبتنی بر ML می شود که به موجب آن مدل ممکن است کدی را پیشنهاد کند که درست به نظر می رسد، اما کامپایل نمی شود. بر اساس تحقیقات داخلی تجربه کاربر، این موضوع می تواند منجر به از بین رفتن اعتماد کاربران در طول زمان و کاهش سود بهره وری شود.
ما از SE برای انجام بررسیهای سریع صحت معنایی در یک بودجه تأخیر معین (کمتر از 100 میلیثانیه برای تکمیل انتها به انتها) استفاده میکنیم و از درختهای نحو انتزاعی ذخیرهشده برای ایجاد درک ساختاری «کامل» استفاده میکنیم. بررسیهای معنایی معمولی شامل وضوح مرجع (یعنی آیا این شی وجود دارد)، بررسیهای فراخوانی روش (به عنوان مثال، تأیید فراخوانی روش با تعداد صحیح پارامترها) و بررسیهای قابلیت انتساب (برای تأیید نوع مورد انتظار است).
به عنوان مثال، برای زبان برنامه نویسی Go، 8٪ از پیشنهادات حاوی خطاهای جمع آوری قبل از بررسی معنایی است. با این حال، استفاده از بررسی های معنایی 80 درصد از پیشنهادات غیرقابل کامپایل را فیلتر کرد. نرخ پذیرش تکمیلهای تک خطی در شش هفته اول استفاده از این ویژگی، احتمالاً به دلیل افزایش اعتماد کاربران، 1.9 برابر بهبود یافته است. به عنوان مقایسه، برای زبانهایی که بررسی معنایی را اضافه نکردهایم، تنها شاهد افزایش 1.3 برابری در پذیرش بودیم.
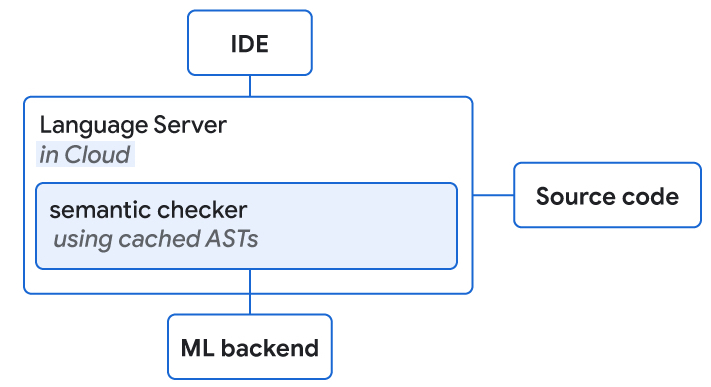 |
| سرورهای زبان با دسترسی به کد منبع و باطن ML در فضای ابری قرار می گیرند. هر دوی آنها بررسی معنایی پیشنهادات تکمیل ML را انجام می دهند. |
نتایج
با 10k+ توسعهدهندگان داخلی Google که از راهاندازی تکمیل در IDE خود استفاده میکنند، نرخ پذیرش کاربر را بین 25 تا 34 درصد اندازهگیری کردیم. ما تعیین کردیم که تکمیل کد ML معنایی ترکیبی مبتنی بر ترانسفورماتور بیش از 3٪ از کد را تکمیل می کند، در حالی که زمان تکرار کدنویسی را برای Googler ها 6٪ کاهش می دهد (در سطح اطمینان 90٪). اندازه تغییر مطابق با اثرات معمولی مشاهده شده برای ویژگیهای تبدیلی (مثلاً چارچوب کلیدی) است که معمولاً فقط یک زیرجمعیت را تحت تأثیر قرار میدهند، در حالی که ML پتانسیل تعمیم برای اکثر زبانها و مهندسان اصلی را دارد.
| کسری از تمام کدهای اضافه شده توسط ML | 2.6٪ |
| کاهش مدت زمان تکرار کدنویسی | 6% |
| نرخ پذیرش (برای پیشنهادات قابل مشاهده برای بیش از 750 میلیثانیه) | 25% |
| میانگین کاراکترها در هر پذیرش | 21 |
| معیارهای کلیدی برای تکمیل کد تک خطی در تولید بیش از 10 هزار برنامهنویس داخلی Google که از آن در توسعه روزانه خود در هشت زبان استفاده میکنند، اندازهگیری میشود. | ||||
| کسری از همه کدهای اضافه شده توسط ML (با بیش از 1 خط در پیشنهاد) | 0.6٪ |
| میانگین کاراکترها در هر پذیرش | 73 |
| نرخ پذیرش (برای پیشنهادات قابل مشاهده برای بیش از 750 میلیثانیه) | 34% |
| معیارهای کلیدی برای تکمیل کد چند خطی در تولید 5k+ توسعهدهندگان داخلی Google که از آن در توسعه روزانه خود در هشت زبان استفاده میکنند، اندازهگیری میشود. | ||||
ارائه تکمیلهای طولانی در حین کاوش APIها
ما همچنین تکمیل معنایی را با تکمیل خط کامل یکپارچه کردیم. هنگامی که فهرست کرکرهای با تکمیلهای تک نشانه معنایی ظاهر میشود، تکمیلهای تک خطی بازگشتی از مدل ML را به صورت درون خطی نمایش میدهیم. مورد دوم ادامه موردی را نشان میدهد که در مرکز کشویی قرار دارد. برای مثال، اگر کاربر به روشهای احتمالی یک API نگاه کند، تکمیلهای خط کامل خط، فراخوانی کامل متد را که شامل تمام پارامترهای فراخوانی نیز میشود، نشان میدهد.
 |
| تکمیل خط کامل یکپارچه شده توسط ML ادامه تکمیل کرکره معنایی که در تمرکز است. |
 |
| پیشنهادهایی برای تکمیل چند خط توسط ML. |
نتیجه گیری و کار آینده
ما نشان میدهیم که چگونه میتوان از ترکیب موتورهای معنایی مبتنی بر قانون و مدلهای زبان بزرگ برای بهبود چشمگیر بهرهوری توسعهدهنده با تکمیل کد بهتر استفاده کرد. به عنوان گام بعدی، ما می خواهیم با ارائه اطلاعات اضافی به مدل های ML در زمان استنتاج، از SE ها بیشتر استفاده کنیم. یک مثال می تواند برای پیش بینی های طولانی بین ML و SE باشد، جایی که SE به طور مکرر صحت را بررسی می کند و تمام ادامه های ممکن را برای مدل ML ارائه می دهد. هنگام افزودن ویژگیهای جدید ارائهشده توسط ML، میخواهیم حواسمان باشد که فراتر از نتایج «هوشمند» برویم، اما از تأثیر مثبت بر بهرهوری اطمینان حاصل کنیم.
سپاسگزاریها
این تحقیق حاصل همکاری دو ساله Google Core و Google Research، Brain Team است. تشکر ویژه از مارک راسی، یورون شن، ولاد پچلین، چارلز ساتون، وارون گودبول، جیکوب آستین، دنی تارلو، بنجامین لی، ساتیش چاندرا، کسنیا کورووینا، استانیسلاو پیاتیک، کریستوفر کلیس، پتروس مانیاتیس، اوگنی گوریس گریازوف، پاریزونف، کریستوف مولنار، آلبرتو الیزوندو، آمبار موریلو، دومینیک شولز، دیوید تاترسال، ریشابه سینگ، مانزیل زاهیر، تد یانگ، خوانجو کارین، الکساندر فرومگن، ماکسیم کاچوروفسکی و مارکوس رواج برای مشارکتهایشان.