یادگیری ماشینی (ML) پتانسیل فوقالعادهای را ارائه میدهد، از تشخیص سرطان گرفته تا مهندسی خودروهای خودران ایمن و تقویت بهرهوری انسان. با این حال، برای تحقق این پتانسیل، سازمانها به راهحلهای ML نیاز دارند تا با توسعه راهحلهای ML که قابل پیشبینی و قابل اجرا باشد، قابل اعتماد باشند. کلید هر دو، درک عمیقتر دادههای ML است – چگونه مجموعههای داده آموزشی را مهندسی کنیم که مدلهای با کیفیت بالا تولید میکنند و مجموعههای داده آزمایشی که شاخصهای دقیقی از نزدیک بودن ما به حل مشکل هدف ارائه میدهند.
فرآیند ایجاد مجموعه دادههای با کیفیت بالا، از انتخاب اولیه و پاکسازی دادههای خام، تا برچسبگذاری دادهها و تقسیم آن به مجموعههای آموزشی و آزمایشی، پیچیده و مستعد خطا است. برخی از کارشناسان بر این باورند که عمده تلاش در طراحی یک سیستم ML در واقع منبع یابی و تهیه داده ها است. هر مرحله می تواند مسائل و سوگیری ها را معرفی کند. حتی بسیاری از مجموعه دادههای استانداردی که امروزه استفاده میکنیم نشان داده شده است که دادههای برچسبگذاری نادرستی دارند که میتواند معیارهای تثبیتشده ML را بیثبات کند. علیرغم اهمیت اساسی داده ها برای ML، تنها در حال حاضر شروع به دریافت همان سطح توجهی شده است که مدل ها و الگوریتم های یادگیری در دهه گذشته از آن لذت برده اند.
برای رسیدن به این هدف، ما DataPerf را معرفی میکنیم، مجموعهای از چالشهای جدید ML دادهمحور برای پیشبرد پیشرفتهترین فناوریهای انتخاب، آمادهسازی و کسب دادهها، که از طریق همکاری گسترده در صنعت و دانشگاه طراحی و ساخته شده است. نسخه اولیه DataPerf شامل چهار چالش است که بر سه وظیفه مشترک داده محور در سه حوزه برنامه متمرکز شده است. پردازش بینایی، گفتار و زبان طبیعی (NLP). در این وبلاگ پست، گلوگاههای توسعه مجموعه دادهای را که محققان با آن مواجه هستند را تشریح میکنیم و نقش معیارها و تابلوهای امتیازات را در تشویق محققان برای رسیدگی به این چالشها مورد بحث قرار میدهیم. ما از نوآورانی در دانشگاه و صنعت که به دنبال اندازهگیری و اعتبارسنجی پیشرفتها در ML دادهمحور هستند دعوت میکنیم تا قدرت الگوریتمها و تکنیکهای خود را برای ایجاد و بهبود مجموعههای داده از طریق این معیارها نشان دهند.
داده ها گلوگاه جدید ML هستند
داده ها کد جدید هستند: این داده های آموزشی هستند که حداکثر کیفیت ممکن یک راه حل ML را تعیین می کنند. مدل فقط میزان تحقق حداکثر کیفیت را تعیین می کند. به یک معنا، مدل یک کامپایلر با اتلاف برای داده ها است. اگرچه مجموعه دادههای آموزشی با کیفیت بالا برای پیشرفت مستمر در زمینه ML حیاتی هستند، بسیاری از دادههایی که امروزه این حوزه بر آن تکیه میکند تقریباً یک دهه قدمت دارد (مثلا ImageNet یا LibriSpeech) یا با فیلتر کردن بسیار محدود محتوا از وب حذف شده است. (به عنوان مثال، LAION یا The Pile).
علیرغم اهمیت داده ها، تحقیقات ML تا به امروز تحت سلطه تمرکز بر مدل ها بوده است. قبل از شبکههای عصبی عمیق مدرن (DNN)، هیچ مدل ML کافی برای مطابقت با رفتار انسان برای بسیاری از وظایف ساده وجود نداشت. این شرایط شروع منجر به الف پارادایم مدل محور که در آن (1) مجموعه داده آموزشی و مجموعه داده آزمایشی مصنوعات “یخ زده” بودند و هدف توسعه یک مدل بهتر بود، و (2) مجموعه داده های آزمایشی به دلایل آماری به طور تصادفی از همان مجموعه داده های مجموعه آموزشی انتخاب شدند. متأسفانه، انجماد مجموعه دادهها، توانایی بهبود دقت و کارایی آموزش با دادههای بهتر را نادیده گرفت و استفاده از مجموعههای آزمایشی که از همان مجموعه دادههای آموزشی گرفته شده بود، تطبیق آن دادهها را با حل واقعی مشکل اساسی ترکیب کرد.
چون الان در حال توسعه هستیم و استقرار راهحلهای ML برای کارهای پیچیدهتر، ما باید مجموعههای آزمایشی را مهندسی کنیم که به طور کامل مشکلات دنیای واقعی و مجموعههای آموزشی را که در ترکیب با مدلهای پیشرفته، راهحلهای مؤثر ارائه میدهند، ثبت کنیم. ما باید از امروز دور شویم پارادایم مدل محور به یک پارادایم داده محور که در آن می دانیم که برای اکثر توسعه دهندگان ML، ایجاد آموزش و داده های آزمایشی با کیفیت بالا یک گلوگاه خواهد بود.
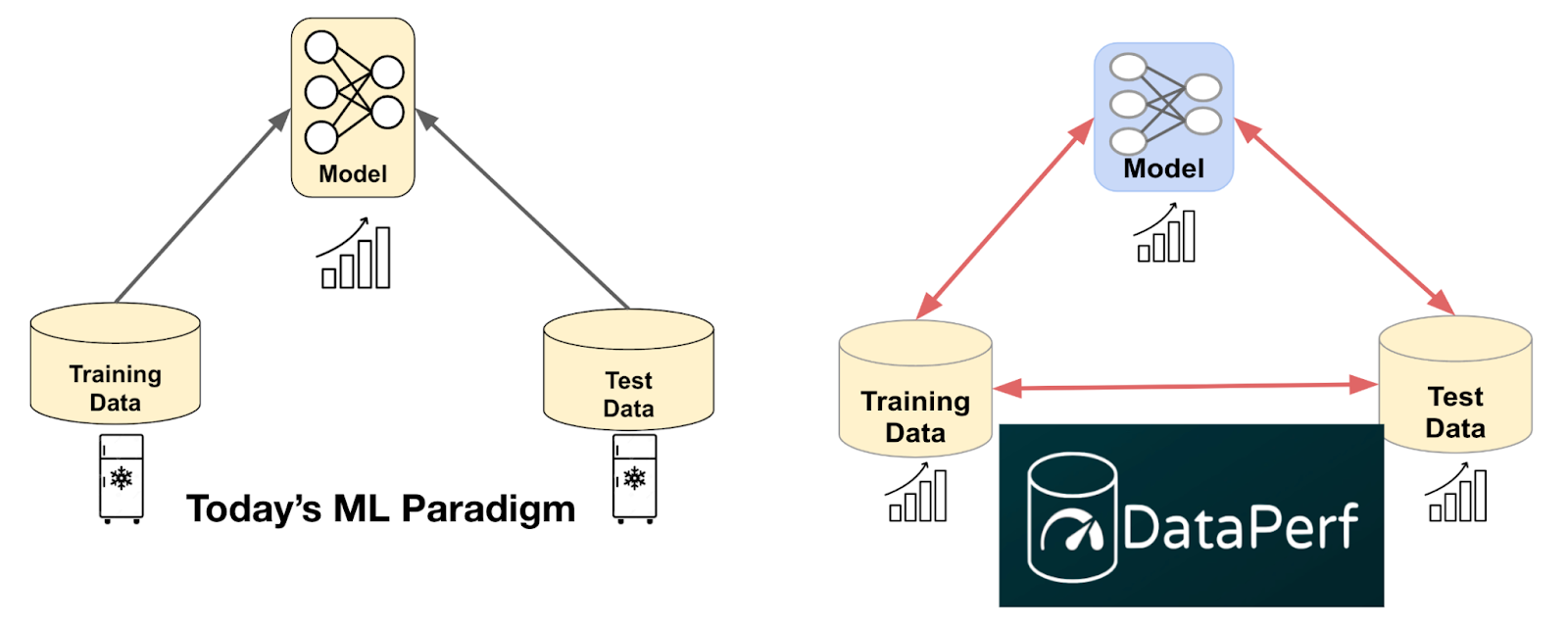 |
| تغییر از پارادایم مدل محور امروزی به پارادایم داده محور که توسط مجموعه داده های با کیفیت و الگوریتم های داده محور مانند موارد اندازه گیری شده در DataPerf فعال می شود. |
فعال کردن توسعه دهندگان ML برای ایجاد آموزش و مجموعه داده های آزمایشی بهتر به درک عمیق تری از کیفیت داده های ML و توسعه الگوریتم ها، ابزارها و متدولوژی ها برای بهینه سازی آن نیاز دارد. میتوانیم با شناخت چالشهای رایج در ایجاد مجموعه داده و توسعه معیارهای عملکرد برای الگوریتمهایی که به آن چالشها رسیدگی میکنند، شروع کنیم. برای مثال:
- انتخاب داده ها: اغلب، ما مجموعه بزرگتری از داده های موجود را نسبت به آنچه که بتوانیم به طور مؤثر برچسب گذاری کنیم یا آموزش دهیم، داریم. چگونه مهم ترین داده ها را برای آموزش مدل های خود انتخاب کنیم؟
- پاکسازی دادهها: برچسبگذاران انسانی گاهی اوقات اشتباه میکنند. توسعهدهندگان ML نمیتوانند از متخصصان بخواهند همه برچسبها را بررسی و تصحیح کنند. چگونه می توانیم داده هایی را که به احتمال زیاد دارای برچسب اشتباه هستند را برای اصلاح انتخاب کنیم؟
ما همچنین میتوانیم مشوقهایی ایجاد کنیم که به مهندسی مجموعه داده خوب پاداش میدهد. ما پیشبینی میکنیم که دادههای آموزشی با کیفیت بالا، که به دقت انتخاب و برچسبگذاری شدهاند، به محصولی ارزشمند در بسیاری از صنایع تبدیل شوند، اما در حال حاضر راهی برای ارزیابی ارزش نسبی مجموعههای داده مختلف بدون آموزش واقعی بر روی مجموعه دادههای مورد نظر وجود ندارد. چگونه این مشکل را حل کنیم و «اکتساب داده» مبتنی بر کیفیت را فعال کنیم؟
DataPerf: اولین تابلوی امتیاز برای داده ها
ما معتقدیم که معیارها و تابلوهای امتیازات خوب می توانند پیشرفت سریعی را در فناوری داده محور ایجاد کنند. معیارهای ML در دانشگاه برای تحریک پیشرفت در این زمینه ضروری بوده است. نمودار زیر را در نظر بگیرید که پیشرفت را در معیارهای محبوب ML (MNIST، ImageNet، SQuAD، GLUE، Switchboard) در طول زمان نشان میدهد:
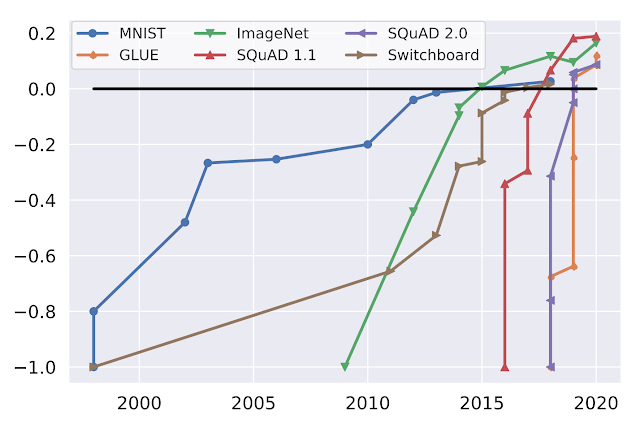 |
| عملکرد در طول زمان برای معیارهای محبوب، با عملکرد اولیه منهای یک و عملکرد انسانی در صفر عادی شده است. (منبع: Douwe, et al. 2021؛ با اجازه استفاده شد.) |
تابلوهای امتیازات آنلاین اعتبارسنجی رسمی نتایج معیار را ارائه میکنند و جوامعی را که قصد بهینهسازی آن معیارها را دارند، تسریع میکنند. به عنوان مثال، Kaggle بیش از 10 میلیون کاربر ثبت شده دارد. نتایج معیار رسمی MLPerf به بهبود بیش از 16 برابری در عملکرد تمرین در معیارهای کلیدی کمک کرده است.
DataPerf اولین انجمن و پلتفرمی است که تابلوهای امتیازات را برای معیارهای داده ایجاد کرده است، و ما امیدواریم که تأثیر مشابهی بر تحقیق و توسعه برای ML داده محور داشته باشیم. نسخه اولیه DataPerf شامل تابلوهای امتیازاتی برای چهار چالش است که بر سه وظیفه داده محور (انتخاب داده، تمیز کردن و جمع آوری) در سه حوزه کاربردی (بینایی، گفتار و NLP) متمرکز شده است:
- انتخاب داده های آموزشی (Vision): یک استراتژی انتخاب داده طراحی کنید که بهترین مجموعه آموزشی را از میان مجموعه بزرگی از تصاویر آموزشی با برچسب ضعیف انتخاب می کند.
- انتخاب دادههای آموزشی (گفتار): یک استراتژی انتخاب داده طراحی کنید که بهترین مجموعه آموزشی را از یک مجموعه کاندیدای بزرگ از کلیپهای استخراج شده خودکار کلمات گفتاری انتخاب میکند.
- تمیز کردن دادههای آموزشی (Vision): یک استراتژی پاکسازی داده طراحی کنید که نمونههایی را برای برچسبگذاری مجدد از یک مجموعه آموزشی “پر سر و صدا” انتخاب میکند که در آن برخی از برچسبها نادرست هستند.
- ارزیابی مجموعه داده های آموزشی (NLP): ساخت مجموعه داده های با کیفیت می تواند گران باشد و در حال تبدیل شدن به کالاهای با ارزش هستند. یک استراتژی جمعآوری داده طراحی کنید که براساس اطلاعات محدود در مورد دادهها، مجموعه دادههای آموزشی را برای «خرید» انتخاب کند.
برای هر چالش، وبسایت DataPerf اسناد طراحی را ارائه میکند که مشکل، مدل(های) آزمایش، هدف کیفیت، قوانین و دستورالعملهای نحوه اجرای کد و ارسال را تعریف میکند. تابلوهای امتیازات زنده بر روی پلتفرم Dynabench میزبانی می شوند، که همچنین یک چارچوب ارزیابی آنلاین و ردیاب ارسال ارائه می دهد. Dynabench یک پروژه منبع باز است که توسط انجمن MLCommons میزبانی می شود و بر فعال کردن تابلوهای داده محور برای داده های آموزشی و آزمایشی و الگوریتم های داده محور متمرکز است.
چگونه درگیر شویم
ما بخشی از جامعه ای از محققان ML، دانشمندان داده و مهندسانی هستیم که برای بهبود کیفیت داده ها تلاش می کنند. ما از نوآوران در دانشگاه و صنعت دعوت می کنیم تا الگوریتم ها و تکنیک های داده محور را برای ایجاد و بهبود مجموعه داده ها از طریق معیارهای DataPerf اندازه گیری و اعتبار سنجی کنند. آخرین مهلت برای دور اول چالش ها 26 می 2023 است.
سپاسگزاریها
معیارهای DataPerf در سال گذشته توسط مهندسان و دانشمندانی از: Coactive.ai، Eidgenössische Technische Hochschule (ETH) زوریخ، گوگل، دانشگاه هاروارد، Meta، ML Commons، دانشگاه استنفورد ایجاد شده است. علاوه بر این، بدون حمایت اعضای گروه کاری DataPerf از دانشگاه کارنگی ملون، مشاوران منشور دیجیتال، Factored، Hugging Face، مؤسسه شناخت انسان و ماشین، Landing.ai، مرکز ابررایانههای سن دیگو، آزمایشگاه تامسون رویترز، امکانپذیر نبود. ، و TU آیندهوون.