
همانطور که دستیارهای مجازی همه جا حاضر می شوند، کاربران به طور فزاینده ای با آنها تعامل می کنند تا درباره موضوعات جدید یاد بگیرند یا توصیه هایی دریافت کنند و از آنها انتظار دارند که توانایی هایی فراتر از گفتگوهای محدود یک یا دو نوبت ارائه دهند. برنامهریزی پویا، یعنی قابلیت نگاه به آینده و برنامهریزی مجدد بر اساس جریان مکالمه، یک عنصر ضروری برای ایجاد مکالمات جذاب با تعاملات عمیقتر و با پایان باز است که کاربران انتظار دارند.
در حالی که مدلهای زبان بزرگ (LLM) در حال حاضر رویکردهای پیشرفته را در بسیاری از معیارهای پردازش زبان طبیعی شکست میدهند، معمولاً به جای برنامهریزی از قبل، که برای تعاملات چند نوبتی لازم است، برای خروجی بهترین پاسخ بعدی آموزش داده میشوند. با این حال، در چند سال گذشته، یادگیری تقویتی (RL) نتایج باورنکردنی را برای رسیدگی به مشکلات خاصی که شامل برنامهریزی پویا است، مانند بازیهای برنده و تا کردن پروتئین، ارائه کرده است.
امروز، ما پیشرفتهای اخیر خود را در برنامهریزی پویا برای مکالمات انسان به دستیار به اشتراک میگذاریم، که در آن یک دستیار را قادر میسازیم تا یک مکالمه چند نوبتی را برای رسیدن به یک هدف برنامهریزی کند و آن برنامه را در زمان واقعی با اتخاذ رویکردی مبتنی بر RL تطبیق دهد. . در اینجا ما به چگونگی بهبود تعاملات طولانی با استفاده از RL برای نوشتن پاسخ ها بر اساس اطلاعات استخراج شده از منابع معتبر، به جای تکیه بر محتوای تولید شده توسط یک مدل زبان، می پردازیم. ما انتظار داریم که نسخههای آینده این اثر بتوانند LLM و RL را در دیالوگهای چند نوبتی ترکیب کنند. استقرار RL “در طبیعت” در یک سیستم گفتگو در مقیاس بزرگ به دلیل پیچیدگی مدلسازی، فضاهای حالت و عمل بسیار بزرگ و ظرافت قابل توجه در طراحی عملکردهای پاداش، چالش بزرگی بود.
برنامه ریزی پویا چیست؟
بسیاری از انواع مکالمات، از جمعآوری اطلاعات تا ارائه توصیهها، نیازمند رویکردی انعطافپذیر و توانایی اصلاح طرح اصلی مکالمه بر اساس جریان آن هستند. این توانایی برای تعویض دنده در وسط مکالمه به عنوان شناخته شده است برنامه ریزی پویا، به عنوان مخالف برنامه ریزی ایستا، که به رویکرد ثابت تری اشاره دارد. به عنوان مثال، در گفتگوی زیر، هدف جذب کاربر با به اشتراک گذاشتن حقایق جالب در مورد حیوانات باحال است. برای شروع، دستیار مکالمه را از طریق یک مسابقه صوتی با کوسه ها هدایت می کند. با توجه به عدم علاقه کاربر به کوسه ها، دستیار پس از آن طرحی به روز می کند و مکالمه را به شیرهای دریایی، شیرها و سپس یوزپلنگ ها اختصاص می دهد.
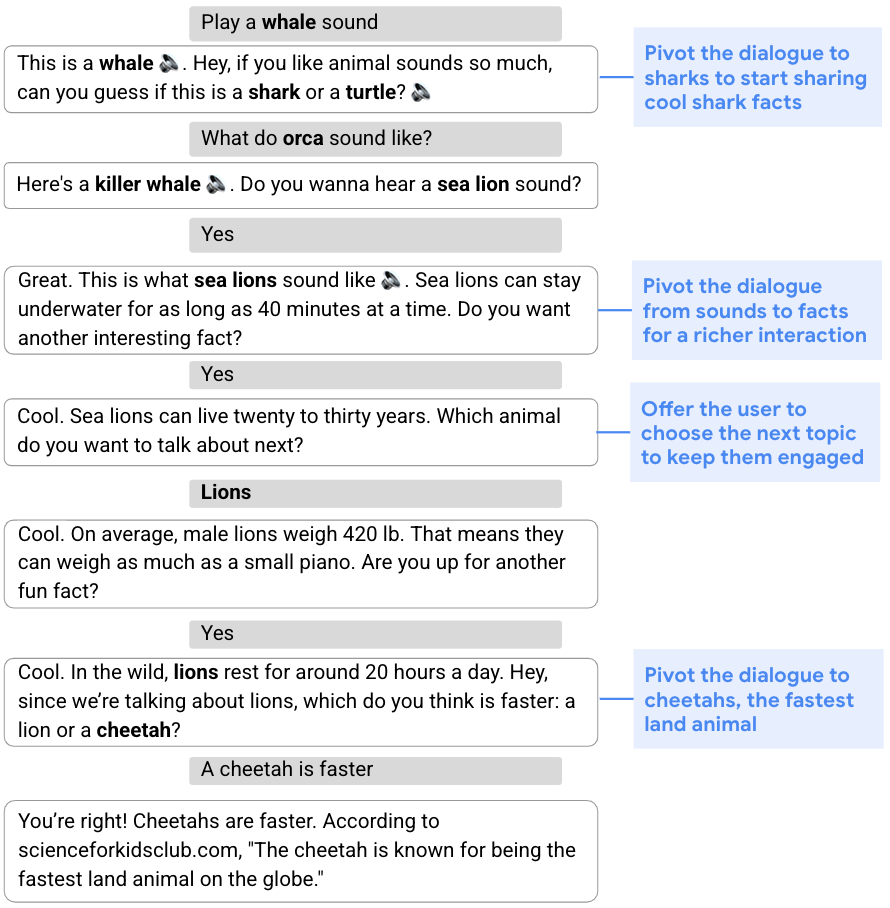 |
| دستیار برنامه اصلی خود را به صورت پویا تغییر می دهد تا در مورد کوسه ها صحبت کند و حقایق مربوط به حیوانات دیگر را به اشتراک بگذارد. |
ترکیب پویا
برای مقابله با چالش کاوش مکالمه، ما تولید پاسخ های دستیار را به دو بخش تقسیم می کنیم: 1) تولید محتوا، که اطلاعات مربوطه را از منابع معتبر استخراج می کند، و 2) ترکیب انعطاف پذیر از چنین محتوایی در پاسخ های دستیار. ما به این رویکرد دو قسمتی اشاره می کنیم ترکیب پویا. برخلاف روشهای LLM، این رویکرد به دستیار توانایی کنترل کامل منبع، صحت و کیفیت محتوایی را که ممکن است ارائه کند، میدهد. در عین حال، می تواند از طریق یک مدیر گفتگوی آموخته که مناسب ترین محتوا را انتخاب و ترکیب می کند، به انعطاف پذیری دست یابد.
در مقاله قبلی، “ترکیب پویا برای کاوش دامنه مکالمه”، ما یک رویکرد جدید را توصیف می کنیم که شامل موارد زیر است: (1) مجموعه ای از ارائه دهندگان محتوا، که نامزدها را از منابع مختلف، مانند قطعه های خبری، حقایق نمودار دانش، و سوالات ارائه می دهد. ; (2) مدیر گفتگو؛ و (3) یک ماژول فیوژن جمله. هر پاسخ دستیار به صورت تدریجی توسط مدیر گفتگو ساخته می شود که نامزدهای پیشنهادی ارائه دهندگان محتوا را انتخاب می کند. توالی انتخاب شده از گفته ها سپس در یک پاسخ منسجم ترکیب می شود.
برنامه ریزی پویا با استفاده از RL
در هسته حلقه ترکیب پاسخ دستیار یک مدیر گفتگو قرار دارد که با استفاده از آن آموزش دیده است خارج از خط مشی RL، یعنی الگوریتمی که سیاستی را ارزیابی و بهبود می بخشد که با خط مشی استفاده شده توسط عامل متفاوت است (در مورد ما، دومی بر اساس یک مدل نظارت شده است). بکارگیری RL در مدیریت گفتگو چالشهای متعددی را به همراه دارد، از جمله فضای حالت بزرگ (همانطور که حالت نشاندهنده حالت مکالمه است که باید کل تاریخچه مکالمه را در نظر بگیرد) و فضای عملی نامحدود (که ممکن است شامل همه کلمات یا جملات موجود به صورت طبیعی باشد. زبان).
ما با استفاده از ساختار جدید RL به این چالش ها می پردازیم. اول، ما از مدلهای نظارت شده قدرتمند – بهویژه، شبکههای عصبی مکرر (RNN) و ترانسفورماتورها – برای ارائه یک نمایش حالت گفتگوی موجز و مؤثر استفاده میکنیم. این رمزگذارهای حالت با تاریخچه دیالوگ تغذیه می شوند که از یک سری چرخش های کاربر و دستیار تشکیل شده است و نمایشی از حالت گفتگو در قالب یک بردار پنهان به بیرون ارائه می دهند.
دوم، ما از این واقعیت استفاده می کنیم که مجموعه نسبتاً کوچکی از گفته ها یا اقدامات نامزد معقول می تواند توسط ارائه دهندگان محتوا در هر نوبت مکالمه تولید شود و فضای عمل را به این موارد محدود می کند. در حالی که فضای عمل معمولاً در تنظیمات RL ثابت است، زیرا همه حالتها فضای عمل یکسانی دارند، فضای ما یک فضای غیر استاندارد است که در آن اقدامات کاندید ممکن است با هر حالت متفاوت باشد، زیرا ارائهدهندگان محتوا کنشهای متفاوتی را بسته به زمینه گفتگو ایجاد میکنند. این ما را در قلمرو مجموعههای کنش تصادفی قرار میدهد، چارچوبی که مواردی را رسمی میکند که در آن مجموعه اقدامات موجود در هر حالت توسط یک فرآیند تصادفی برونزا اداره میشود، که ما با استفاده از یادگیری عمل تصادفی Q، نوعی از یادگیری Q، به آن میپردازیم. رویکرد. Q-learning یک الگوریتم RL خارج از خط مشی محبوب است که برای ارزیابی و بهبود خط مشی نیازی به مدلی از محیط ندارد. ما مدل خود را بر روی مجموعهای از مکالمات با رتبهبندی محاسبهشده جمعی که با استفاده از یک مدیر گفتگوی نظارت شده بهدست آمده بود، آموزش دادیم.
 |
| با توجه به تاریخچه گفتگوی فعلی و درخواست کاربر جدید، ارائه دهندگان محتوا نامزدهایی را ایجاد می کنند که دستیار یکی را از بین آنها انتخاب می کند. این فرآیند در یک حلقه اجرا می شود و در پایان عبارات انتخاب شده در یک پاسخ منسجم ترکیب می شوند. |
ارزیابی مدل یادگیری تقویتی
ما مدیر گفتگوی RL خود را با یک مدل ترانسفورماتور نظارتشده راهاندازی شده در آزمایشی با استفاده از «دستیار Google» مقایسه کردیم که با کاربران درباره حیوانات صحبت میکرد. یک مکالمه زمانی شروع می شود که کاربر با پرسیدن یک پرسش مربوط به حیوانات (به عنوان مثال، “صدای شیر چگونه است؟”، تجربه را آغاز می کند. این آزمایش با استفاده از یک پروتکل تست A/B انجام شد که در آن درصد کمی از کاربران Assistant به طور تصادفی برای تعامل با دستیار مبتنی بر RL ما انتخاب شدند در حالی که سایر کاربران با دستیار استاندارد تعامل داشتند.
ما متوجه شدیم که مدیر گفتگوی RL مکالمات طولانی تر و جذاب تری را انجام می دهد. طول مکالمه را 30 درصد افزایش می دهد و در عین حال معیارهای تعامل کاربر را بهبود می بخشد. ما شاهد افزایش 8 درصدی در پاسخهای مشارکتی به سؤالات دستیار هستیم – به عنوان مثال، “درباره شیرها به من بگویید”، در پاسخ به “بعد میخواهید درباره کدام حیوان بشنوید؟” اگرچه افزایش زیادی در پاسخهای اسمی «غیر مشارکتی» نیز وجود دارد (مثلاً «نه» به عنوان پاسخی به سؤالی که محتوای اضافی را پیشنهاد میکند، مانند «آیا میخواهید بیشتر بشنوید؟»)، این انتظار میرود که عامل RL با پرسیدن سوالات محوری ریسک بیشتری می کند. در حالی که ممکن است یک کاربر به جهت مکالمه پیشنهاد شده توسط دستیار علاقه مند نباشد (مثلاً چرخش به حیوان دیگری)، کاربر اغلب به گفتگو در مورد حیوانات ادامه می دهد.
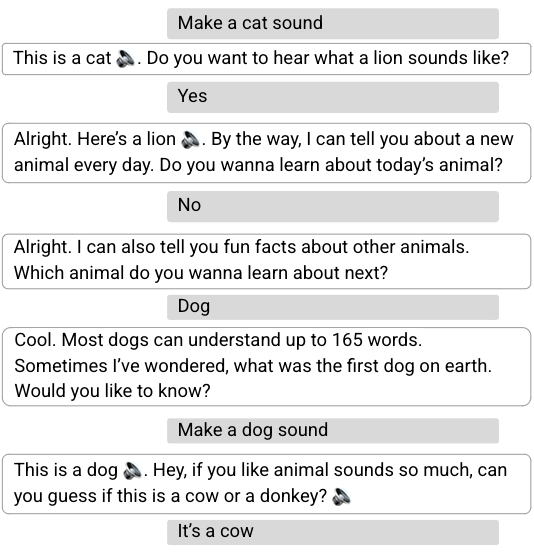 |
| از پاسخ کاربر غیر همکار در نوبت سوم (“نه”) و پرس و جو “صدای سگ بساز”، در نوبت پنجم، دستیار تشخیص می دهد که کاربر بیشتر به صداهای حیوانات علاقه مند است و طرح خود را اصلاح می کند و ارائه می دهد. صداها و آزمون های صوتی |
بهعلاوه، برخی از پرسشهای کاربر حاوی بازخورد صریح مثبت (مثلاً «از شما، Google» یا «من خوشحالم») یا منفی (مانند «خفه شو» یا «توقف») هستند. در حالی که مرتبه بزرگی کمتر از سایر جستارها است، آنها معیار مستقیمی از (نارضایتی) کاربر را ارائه می دهند. مدل RL بازخورد مثبت صریح را 32 درصد افزایش می دهد و بازخورد منفی را 18 درصد کاهش می دهد.
ویژگی ها و استراتژی های برنامه ریزی پویا را یاد گرفت
ما چندین ویژگی برنامه RL (دیده نشده) را برای بهبود تعامل کاربر در حین انجام مکالمات طولانیتر مشاهده میکنیم. اول، دستیار مبتنی بر RL 20٪ بیشتر به نوبت سوالات پایان می دهد و کاربر را به انتخاب محتوای اضافی ترغیب می کند. همچنین از تنوع محتوا، از جمله حقایق، صداها، آزمونها، سؤالات بله/خیر، سؤالات باز و غیره بهتر استفاده میکند. بهطور متوسط، دستیار RL در هر مکالمه از ارائهدهندگان محتوای متمایز 26 درصد بیشتری نسبت به مدل تحت نظارت استفاده میکند.
دو استراتژی برنامه ریزی RL مشاهده شده به وجود گفتگوهای فرعی با ویژگی های مختلف مربوط می شود. دیالوگ های فرعی درباره صداهای حیوانات از نظر محتوا ضعیف تر هستند و در هر نوبت چرخش موجودیت را نشان می دهند (یعنی پس از پخش صدای یک حیوان معین، می توانیم صدای حیوان دیگری را پیشنهاد کنیم یا کاربر را در مورد صداهای حیوانات دیگر سؤال کنیم). در مقابل، گفتوگوهای فرعی که شامل حقایق حیوانی است، معمولاً حاوی محتوای غنیتر و عمق مکالمه بیشتری است. مشاهده میکنیم که RL از تجربه غنیتر دومی حمایت میکند و محتوای مرتبط با واقعیت را 31 درصد بیشتر انتخاب میکند. در نهایت، هنگامی که تحلیل را به دیالوگ های مربوط به واقعیت محدود می کند، دستیار RL 60٪ چرخش های متمرکز بیشتر را نشان می دهد، یعنی چرخش های مکالمه ای که تمرکز گفتگو را تغییر می دهد.
در زیر، دو مکالمه نمونه را نشان می دهیم، یکی توسط مدل نظارت شده (چپ) و دومی توسط مدل RL (راست)، که در آن سه چرخش کاربر اول یکسان هستند. با یک مدیر گفتگوی نظارت شده، پس از اینکه کاربر از شنیدن درباره “حیوان امروزی” خودداری کرد، دستیار به صدای حیوانات برمی گردد تا رضایت فوری کاربر را به حداکثر برساند. در حالی که مکالمه انجام شده توسط مدل RL به طور یکسان آغاز می شود، استراتژی برنامه ریزی متفاوتی را برای بهینه سازی تعامل کلی کاربر، معرفی محتوای متنوع تر، مانند حقایق سرگرم کننده، نشان می دهد.
 |
| در مکالمه سمت چپ که توسط مدل نظارت شده انجام می شود، دستیار رضایت فوری کاربر را به حداکثر می رساند. مکالمه درست، انجام شده توسط مدل RL، استراتژی های برنامه ریزی متفاوتی را برای بهینه سازی تعامل کلی کاربر نشان می دهد. |
تحقیقات و چالش های آینده
در چند سال گذشته، LLM هایی که برای درک و تولید زبان آموزش دیده اند، نتایج چشمگیری را در چندین کار، از جمله گفتگو، نشان داده اند. ما اکنون در حال بررسی استفاده از چارچوب RL برای توانمندسازی LLM ها با قابلیت برنامه ریزی پویا هستیم تا بتوانند به صورت پویا برنامه ریزی کنند و کاربران را با تجربه ای جذاب تر خوشحال کنند.
سپاسگزاریها
اثر توصیف شده توسط: مونکیونگ ریو، یینلام چاو، ارگاد کلر، ایدو گرینبرگ، آوینتان هاسیدیم، مایکل فینک، یوسی ماتیاس، ایدان شپکتور و گال الیدان تالیف شده است. از: رو آهارونی، موران آمبار، جان اندرسون، ایدو کوهن، محمد قوام زاده، لوتم گولانی، زیو هوداک، آدو لوین، فرناندو پریرا، شیمی سالانت، شاچار شیمونی، رونیت اسلایپر، آریل استولوویچ، هاگای تایتلان نوام، تشکر می کنیم. ، آویتال زیپوری و تیم CrowdCompute به رهبری اشوین کاکارلا. ما از سوفی آلویس برای بازخوردش در مورد این وبلاگ و تام اسمال برای تجسم تشکر می کنیم.