
تشخیص ناهنجاری (AD)، وظیفه تشخیص ناهنجاریها از دادههای معمولی، در بسیاری از برنامههای کاربردی دنیای واقعی، مانند شناسایی محصولات معیوب از حسگرهای بینایی در تولید، رفتارهای متقلبانه در تراکنشهای مالی، یا تهدیدات امنیتی شبکه، نقش حیاتی ایفا میکند. بسته به در دسترس بودن نوع داده – منفی (عادی) در مقابل مثبت (غیر عادی) و در دسترس بودن برچسب آنها – وظیفه AD شامل چالش های مختلفی است.
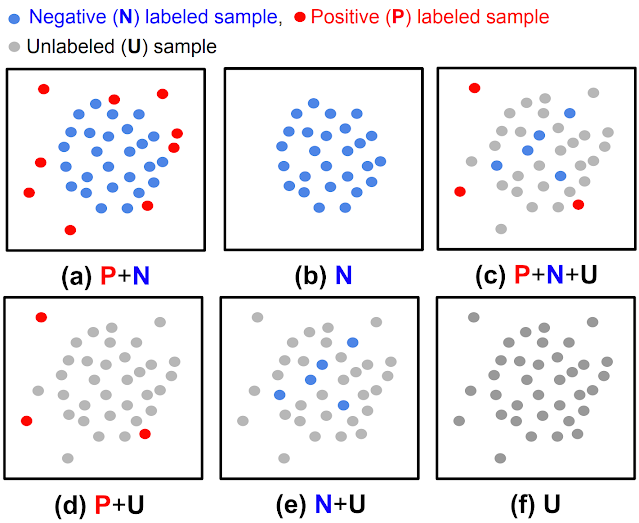 |
| (الف) تشخیص ناهنجاری کاملاً نظارت شده، (ب) تشخیص ناهنجاری فقط عادی، (ج، د، ه) تشخیص ناهنجاری نیمه نظارت شده، (و) تشخیص ناهنجاری بدون نظارت. |
در حالی که بیشتر کارهای قبلی برای مواردی با دادههای کاملاً برچسبگذاریشده (یا (الف) یا (ب) در شکل بالا نشان داده شدهاند، مؤثر هستند، چنین تنظیماتی در عمل کمتر رایج هستند زیرا دریافت برچسبها بهویژه خسته کننده است. در اکثر سناریوها، کاربران بودجه برچسب گذاری محدودی دارند و حتی گاهی اوقات هیچ نمونه برچسب گذاری شده ای در طول آموزش وجود ندارد. علاوه بر این، حتی زمانی که دادههای برچسبدار در دسترس هستند، ممکن است سوگیریهایی در نحوه برچسبگذاری نمونهها وجود داشته باشد که باعث تفاوتهای توزیع میشود. چنین چالش های داده های دنیای واقعی، دقت قابل دستیابی روش های قبلی در تشخیص ناهنجاری ها را محدود می کند.
این پست دو مقاله اخیر ما در مورد AD را پوشش میدهد که در Transactions on Machine Learning Research (TMLR) منتشر شده است، که چالشهای فوق را در تنظیمات بدون نظارت و نیمهنظارت بررسی میکند. با استفاده از رویکردهای داده محور، نتایج پیشرفتهای را در هر دو نشان میدهیم. در “خود نظارتی، اصلاح، تکرار: بهبود تشخیص ناهنجاری بدون نظارت”، ما یک چارچوب جدید AD بدون نظارت را پیشنهاد می کنیم که بر اصول یادگیری خود نظارتی بدون برچسب و پالایش داده های تکراری بر اساس توافق طبقه بندی کننده یک طبقه (OCC) متکی است. ) خروجی ها. در “SPADE: تشخیص ناهنجاری نیمه نظارت شده تحت عدم تطابق توزیع”، ما یک چارچوب جدید نیمه نظارتی AD را پیشنهاد می کنیم که حتی در صورت عدم تطابق توزیع با نمونه های برچسب دار محدود، عملکرد قوی را ارائه می دهد.
تشخیص ناهنجاری بدون نظارت با SRR: خود نظارت، اصلاح، تکرار
کشف مرز تصمیم برای توزیع تک کلاسی (عادی) (یعنی آموزش OCC) در تنظیمات کاملاً بدون نظارت چالش برانگیز است زیرا داده های آموزشی بدون برچسب شامل دو کلاس (عادی و غیر عادی) است. با افزایش نسبت ناهنجاری برای داده های بدون برچسب، این چالش بیشتر تشدید می شود. برای ایجاد یک OCC قوی با دادههای بدون برچسب، به استثنای نمونههای مثبت احتمالی (غیر عادی) از دادههای بدون برچسب، فرآیندی که به عنوان پالایش دادهها از آن یاد میشود، حیاتی است. داده های تصفیه شده، با نسبت ناهنجاری پایین تر، نشان داده شده اند که مدل های تشخیص ناهنجاری برتر را ارائه می دهند.
SRR ابتدا دادهها را از یک مجموعه داده بدون برچسب پالایش میکند، سپس به طور مکرر با استفاده از دادههای تصفیهشده، نمایشهای عمیق را آموزش میدهد در حالی که با حذف نمونههای احتمالی مثبت، پالایش دادههای بدون برچسب را بهبود میبخشد. برای پالایش دادهها، مجموعهای از OCCها استفاده میشود که هر کدام بر روی یک زیرمجموعه مجزا از دادههای آموزشی بدون برچسب آموزش داده میشوند. اگر بین همه OCC ها در مجموعه اتفاق نظر وجود داشته باشد، داده هایی که منفی (طبیعی) پیش بینی می شود در داده های تصفیه شده گنجانده می شود. در نهایت، داده های آموزشی تصفیه شده برای آموزش OCC نهایی برای تولید پیش بینی های ناهنجاری استفاده می شود.
 |
| آموزش SRR با ماژول پالایش داده (گروه OCCs)، یادگیرنده بازنمایی و OCC نهایی. (نقاط سبز/قرمز به ترتیب نمونه های عادی/غیر طبیعی را نشان می دهند). |
نتایج SRR
ما آزمایشهای گستردهای را در مجموعه دادههای مختلف از حوزههای مختلف انجام میدهیم، از جمله AD معنایی (CIFAR-10، سگ در مقابل گربه)، AD بصری تولید در دنیای واقعی (MVTec)، و معیارهای AD جدولی دنیای واقعی مانند تشخیص پزشکی (تیروئید) یا ناهنجاری های امنیت شبکه (KDD 1999). ما روش هایی را با هر دو مدل کم عمق (به عنوان مثال، OC-SVM) و عمیق (به عنوان مثال، GOAD، CutPaste) در نظر می گیریم. از آنجایی که نسبت ناهنجاری دادههای دنیای واقعی میتواند متفاوت باشد، ما مدلها را در نسبتهای ناهنجاری مختلف دادههای آموزشی بدون برچسب ارزیابی میکنیم و نشان میدهیم که SRR به طور قابلتوجهی عملکرد AD را افزایش میدهد. به عنوان مثال، SRR بیش از 15.0 میانگین دقت (AP) را با نسبت ناهنجاری 10٪ در مقایسه با یک مدل عمیق یک کلاس پیشرفته در CIFAR-10 بهبود می بخشد. به طور مشابه، در MVTec، SRR عملکرد ثابت خود را حفظ میکند و کمتر از 1.0 AUC با نسبت ناهنجاری 10 درصد کاهش مییابد، در حالی که بهترین OCC موجود بیش از 6.0 AUC کاهش مییابد. در نهایت، در مورد تیروئید (دادههای جدولی)، SRR با 22.9 امتیاز F1 با نسبت ناهنجاری 2.5 درصد از طبقهبندیکننده تککلاس پیشرفته بهتر عمل میکند.
.png) |
| در دامنه های مختلف، SRR (خط آبی) به طور قابل توجهی عملکرد AD را با نسبت های مختلف ناهنجاری در تنظیمات کاملاً بدون نظارت افزایش می دهد. |
SPADE: تشخیص ناهنجاری شبه لیبلر نیمه نظارت شده با Ensembling
اکثر روش های یادگیری نیمه نظارت شده (به عنوان مثال، FixMatch، VIME) فرض می کنند که داده های برچسب دار و بدون برچسب از توزیع های یکسانی می آیند. با این حال، در عمل، عدم تطابق توزیع معمولاً رخ می دهد، با داده های برچسب دار و بدون برچسب که از توزیع های مختلف می آیند. یکی از این موارد تنظیمات مثبت و بدون برچسب (PU) یا منفی و بدون برچسب (NU) است، که در آن توزیع بین نمونه های برچسب دار (اعم از مثبت یا منفی) و بدون برچسب (هم مثبت و هم منفی) متفاوت است. یکی دیگر از دلایل تغییر توزیع، داده های بدون برچسب اضافی است که پس از برچسب زدن جمع آوری می شود. به عنوان مثال، فرآیندهای تولید ممکن است به تکامل خود ادامه دهند و باعث شود عیوب مربوطه تغییر کنند و انواع عیب در برچسبگذاری با انواع عیب در دادههای بدون برچسب متفاوت باشد. علاوه بر این، برای کاربردهایی مانند کشف تقلب مالی و مبارزه با پولشویی، ناهنجاریهای جدیدی میتوانند پس از فرآیند برچسبگذاری دادهها ظاهر شوند، زیرا رفتار مجرمانه ممکن است سازگار شود. در نهایت، برچسبها وقتی نمونههای آسان را برچسبگذاری میکنند، اطمینان بیشتری دارند. بنابراین، نمونههای آسان/سخت به احتمال زیاد در دادههای برچسبدار/بدون برچسب گنجانده میشوند. به عنوان مثال، با برخی برچسبگذاریهای مبتنی بر جمعسپاری، تنها نمونههایی که روی برچسبها اتفاق نظر دارند (به عنوان معیار اطمینان) در مجموعه برچسبگذاری شده گنجانده میشوند.
 |
| سه سناریوی رایج در دنیای واقعی با عدم تطابق توزیع (جعبه آبی: نمونههای عادی، جعبه قرمز: نمونههای ناهنجاری شناخته شده/آسان، جعبه زرد: نمونههای ناهنجاری جدید/سخت). |
روشهای یادگیری نیمهنظارتشده استاندارد فرض میکنند که دادههای برچسبدار و بدون برچسب از توزیع یکسانی میآیند، بنابراین برای AD نیمهنظارتشده تحت عدم تطابق توزیع، زیربهینه هستند. SPADE از مجموعه ای از OCC ها برای تخمین شبه برچسب های داده های بدون برچسب استفاده می کند – این کار را مستقل از داده های برچسب گذاری شده مثبت انجام می دهد، بنابراین وابستگی به برچسب ها را کاهش می دهد. این امر به ویژه زمانی مفید است که عدم تطابق توزیع وجود داشته باشد. علاوه بر این، SPADE از تطبیق جزئی استفاده میکند تا بهطور خودکار پارامترهای فوقالعاده حیاتی را برای برچسبگذاری شبه بدون تکیه بر دادههای اعتبار سنجی برچسبگذاریشده انتخاب کند، یک قابلیت حیاتی با توجه به دادههای برچسبگذاری شده محدود.
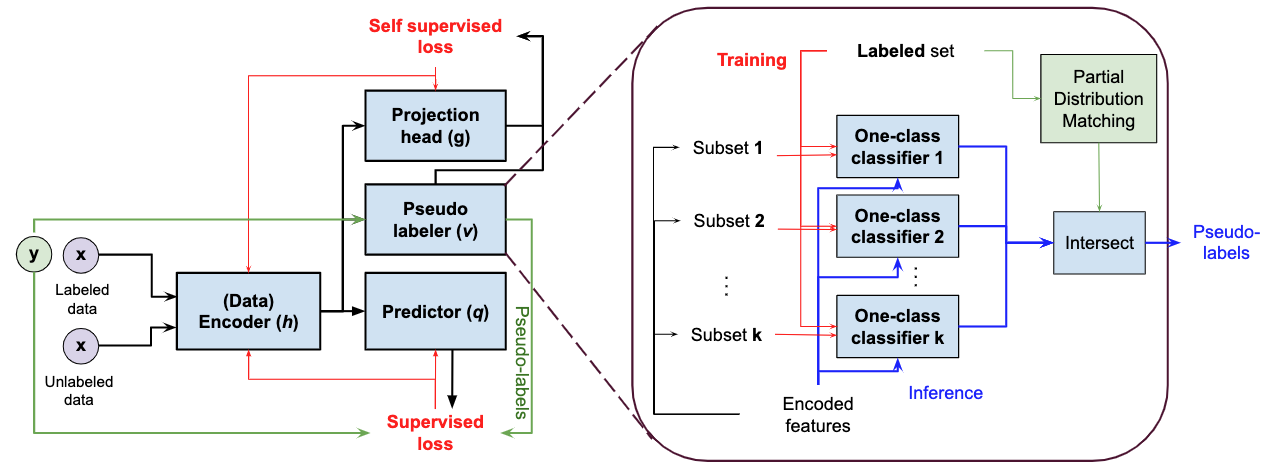 |
| بلوک دیاگرام SPADE با زوم در بلوک دیاگرام دقیق شبه نشانگرهای پیشنهادی. |
نتایج SPADE
ما آزمایشهای گستردهای انجام میدهیم تا مزایای SPADE را در تنظیمات مختلف دنیای واقعی یادگیری نیمه نظارت شده با عدم تطابق توزیع نشان دهیم. ما چندین مجموعه داده AD را برای داده های تصویری (از جمله MVTec) و جدولی (از جمله Covertype، Thyroid) در نظر می گیریم.
SPADE پیشرفته ترین عملکرد تشخیص ناهنجاری نیمه نظارت شده را در طیف گسترده ای از سناریوها نشان می دهد: (1) انواع جدید ناهنجاری ها، (2) نمونه های آسان برای برچسب زدن، و (iii) نمونه های مثبت-بدون برچسب. همانطور که در زیر نشان داده شده است، با انواع جدید ناهنجاری ها، SPADE به طور متوسط 5% AUC از جایگزین های پیشرفته برتری دارد.
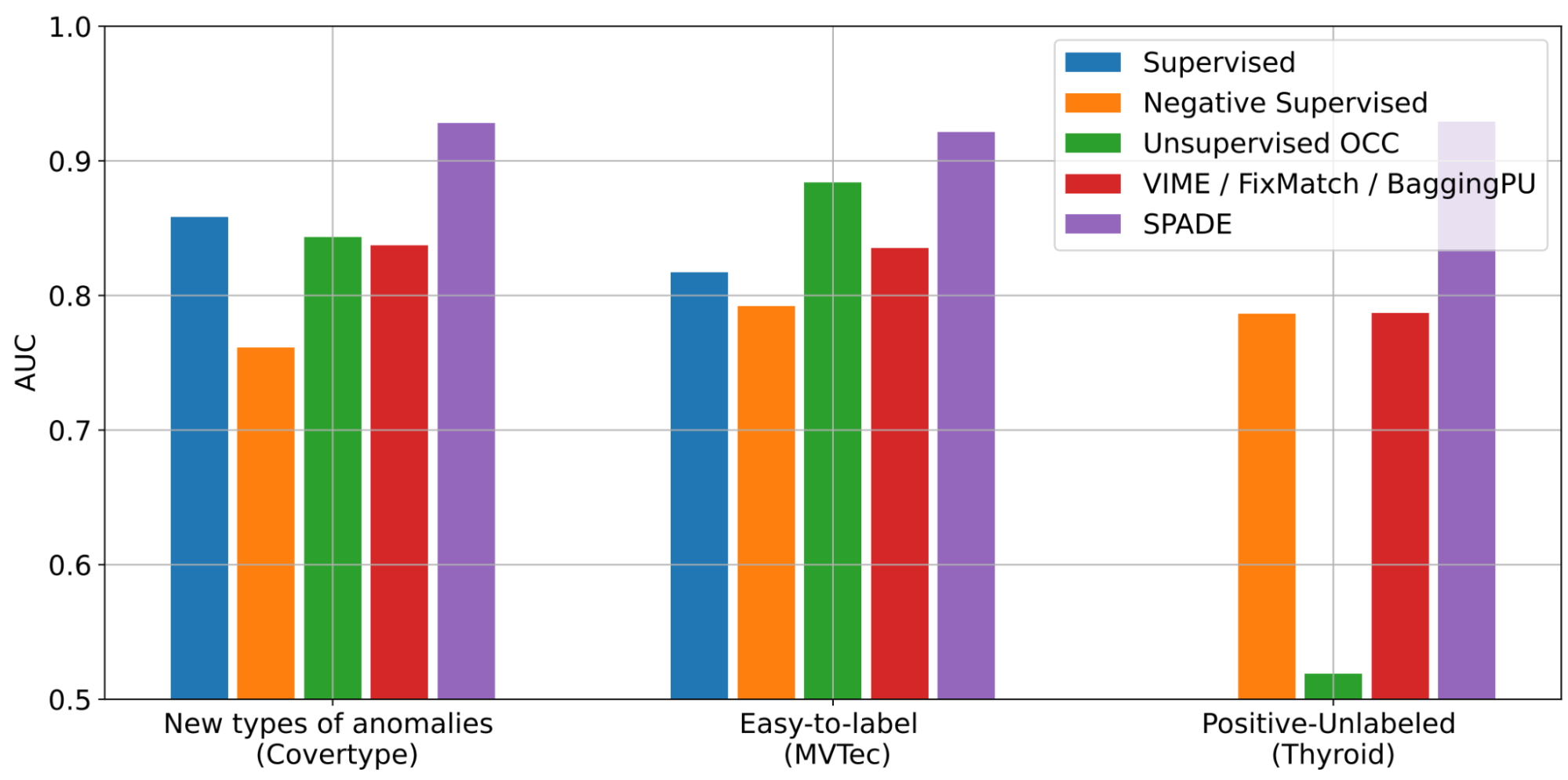 |
| عملکرد AD با سه سناریو مختلف در مجموعه داده های مختلف (Covertype، MVTec، Thyroid) از نظر AUC. برخی از خطوط پایه فقط برای برخی سناریوها قابل اجرا هستند. نتایج بیشتر با سایر خطوط پایه و مجموعه داده را می توان در مقاله یافت. |
ما همچنین SPADE را در مجموعه دادههای کشف تقلب مالی در دنیای واقعی ارزیابی میکنیم: کلاهبرداری کارت اعتباری Kaggle و شناسایی تقلب Xente. برای این موارد، ناهنجاریها تکامل مییابند (یعنی توزیع آنها در طول زمان تغییر میکند) و برای شناسایی ناهنجاریهای در حال تکامل، باید به برچسب زدن برای ناهنجاریهای جدید ادامه دهیم و مدل AD را دوباره آموزش دهیم. با این حال، برچسب زدن پرهزینه و زمان بر خواهد بود. حتی بدون برچسبگذاری اضافی، SPADE میتواند عملکرد AD را با استفاده از دادههای برچسبگذاریشده و دادههای بدون برچسب تازه جمعآوریشده بهبود بخشد.
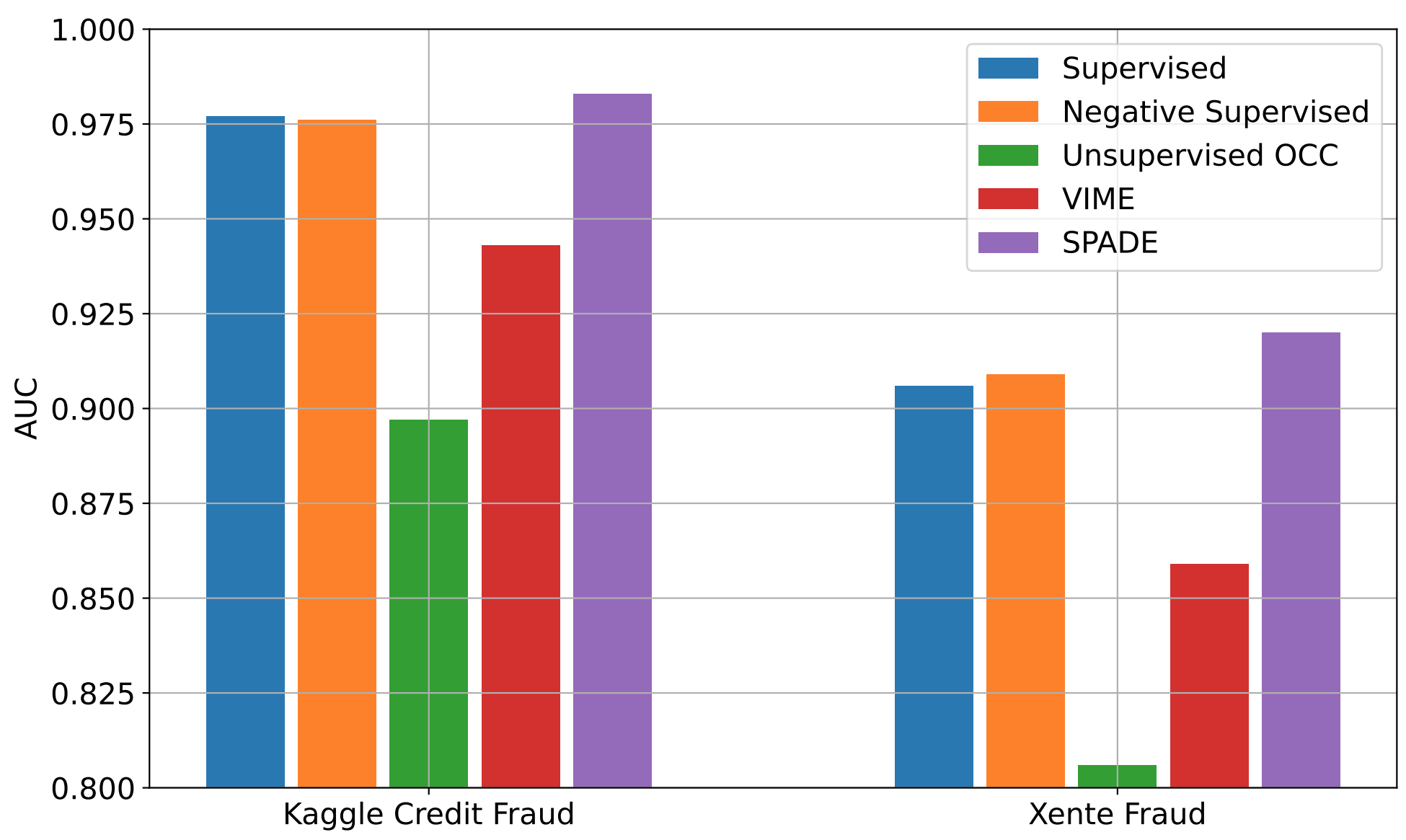 |
| عملکرد AD با توزیع های متغیر با زمان با استفاده از دو مجموعه داده کشف تقلب در دنیای واقعی با نسبت برچسب گذاری 10٪. خطوط پایه بیشتری را می توان در مقاله یافت. |
همانطور که در بالا نشان داده شد، SPADE به طور مداوم از جایگزین ها در هر دو مجموعه داده بهتر عمل می کند، و از داده های بدون برچسب استفاده می کند و برای توزیع های در حال تکامل استحکام نشان می دهد.
نتیجه گیری
AD دارای طیف گسترده ای از موارد استفاده با اهمیت قابل توجه در برنامه های کاربردی دنیای واقعی است، از شناسایی تهدیدات امنیتی در سیستم های مالی تا شناسایی رفتارهای معیوب ماشین های تولیدی.
یکی از جنبه های چالش برانگیز و پرهزینه ساخت یک سیستم AD این است که ناهنجاری ها نادر هستند و به راحتی توسط مردم قابل تشخیص نیستند. برای این منظور، ما SRR را پیشنهاد کردهایم، یک چارچوب AD متعارف برای فعال کردن AD با کارایی بالا بدون نیاز به برچسبهای دستی برای آموزش. SRR را می توان به طور انعطاف پذیر با هر OCC ادغام کرد و روی داده های خام یا نمایش های قابل آموزش اعمال کرد.
AD نیمه نظارت شده یکی دیگر از چالش های بسیار مهم است – در بسیاری از سناریوها، توزیع نمونه های برچسب دار و بدون برچسب مطابقت ندارند. SPADE یک مکانیسم شبه برچسب گذاری قوی با استفاده از مجموعه ای از OCC ها و روشی عاقلانه برای ترکیب یادگیری تحت نظارت و خود نظارتی معرفی می کند. علاوه بر این، SPADE یک رویکرد کارآمد برای انتخاب فراپارامترهای حیاتی بدون مجموعه اعتبار سنجی، یک جزء حیاتی برای AD کارآمد از نظر داده، معرفی می کند.
به طور کلی، ما نشان میدهیم که SRR و SPADE در سناریوهای مختلف در انواع مختلف مجموعه دادهها به طور مداوم از جایگزینها بهتر عمل میکنند.
سپاسگزاریها
ما از کمک های کیهیوک سون، چون-لیانگ لی، چن-یو لی، کایل زیگلر، نیت یودر، و توماس فایستر سپاسگزاریم.