
پیشرفتهای اخیر کاربرد مدلهای زبان (LM) را برای کارهای پاییندستی گسترش داده است. از یک سو، مدلهای زبانی موجود که بهدرستی از طریق زنجیرهای از فکر ارائه میشوند، قابلیتهای نوظهوری را نشان میدهند که ردپای استدلالی خود مشروط را برای استخراج پاسخها از پرسشها انجام میدهند و در کارهای مختلف حسابی، عقل سلیم و استدلال نمادین برتری مییابند. با این حال، با تحریک زنجیرهای از فکر، یک مدل در دنیای بیرونی پایهگذاری نمیشود و از بازنماییهای درونی خود برای ایجاد ردپای استدلالی استفاده میکند و توانایی آن را برای کاوش واکنشی و استدلال یا بهروزرسانی دانش خود محدود میکند. از سوی دیگر، کار اخیر از مدلهای زبانی از پیش آموزشدیده برای برنامهریزی و عمل در محیطهای تعاملی مختلف (مثلاً بازیهای متنی، ناوبری وب، وظایف تجسمیافته، روباتیک) با تمرکز بر نگاشت بافتهای متن به اقدامات متنی از طریق مدل زبانی استفاده میکند. دانش داخلی با این حال، آنها به طور انتزاعی در مورد اهداف سطح بالا استدلال نمی کنند یا یک حافظه فعال را برای حمایت از عمل در افق های طولانی حفظ نمی کنند.
در “ReAct: هم افزایی استدلال و عمل در مدل های زبانی”، ما یک الگوی کلی پیشنهاد می کنیم که پیشرفت های استدلال و عمل را ترکیب می کند تا مدل های زبانی را قادر می سازد تا وظایف مختلف استدلال و تصمیم گیری زبان را حل کنند. ما نشان می دهیم که دلیل + عمل پارادایم (ReAct) به طور سیستماتیک بهتر از پارادایمهای استدلال و عمل، زمانی که مدلهای زبانی بزرگتر را مطرح میکند و مدلهای زبانی کوچکتر را تنظیم میکند، بهتر عمل میکند. ادغام دقیق استدلال و عمل همچنین مسیرهای حل کار همسو با انسان را ارائه می دهد که تفسیرپذیری، تشخیص پذیری و کنترل پذیری را بهبود می بخشد.
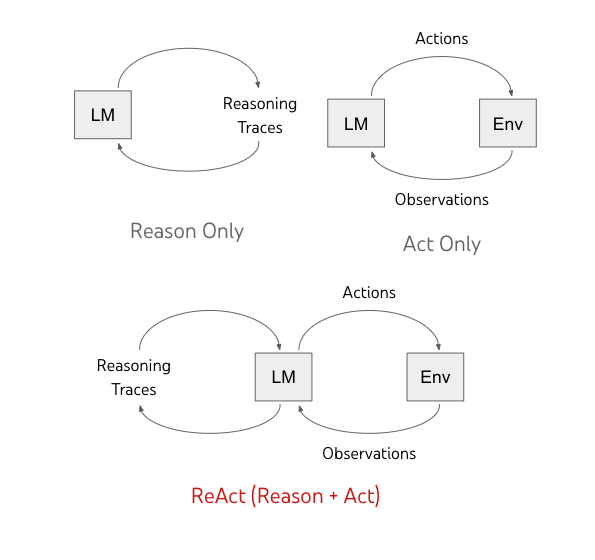
نمای کلی مدل
ReAct مدلهای زبان را قادر میسازد تا هم ردپای استدلال کلامی و هم کنشهای متنی را بهصورت درهمپیچیده ایجاد کنند. در حالی که اقدامات منجر به بازخورد مشاهده از یک محیط خارجی می شود (“Env” در شکل زیر)، ردپای استدلال بر محیط خارجی تأثیر نمی گذارد. در عوض، آنها با استدلال در زمینه و به روز رسانی آن با اطلاعات مفید برای پشتیبانی از استدلال و عمل آینده، بر وضعیت داخلی مدل تأثیر می گذارند.
|
| روشهای قبلی، مدلهای زبانی (LM) را وادار میکنند که ردپای استدلال خود شرطی یا کنشهای خاص کار را ایجاد کنند. ما ReAct را پیشنهاد میکنیم، الگوی جدیدی که استدلال و پیشرفتهای عملی را در مدلهای زبانی ترکیب میکند. |
ReAct Prompting
ما بر روی تنظیماتی تمرکز میکنیم که در آن یک مدل زبان ثابت، PaLM-540B، با نمونههای چند تصویری در زمینه برای ایجاد هر دو کنش خاص دامنه (مثلاً «جستجو» در پاسخگویی به سؤال و «رفتن به» در ناوبری اتاق درخواست میشود. ) و ردپای استدلال زبان به شکل آزاد (مثلاً «حالا باید یک فنجان پیدا کنم و روی میز بگذارم») برای حل کار.
برای کارهایی که استدلال از اهمیت اولیه برخوردار است، به طور متناوب تولید آثار و اقدامات استدلالی را تغییر می دهیم تا مسیر حل تکلیف از مراحل متعدد استدلال-اقدام-مشاهده تشکیل شود. در مقابل، برای کارهای تصمیمگیری که به طور بالقوه شامل تعداد زیادی کنش میشوند، ردپای استدلال فقط باید به صورت پراکنده در مرتبطترین موقعیتهای یک مسیر ظاهر شود، بنابراین ما دستورات را با استدلال پراکنده مینویسیم و اجازه میدهیم مدل زبان درباره وقوع ناهمزمان استدلال تصمیمگیری کند. آثار و اعمال برای خود.
همانطور که در زیر نشان داده شده است، انواع مختلفی از ردپای استدلال مفید وجود دارد، به عنوان مثال، تجزیه اهداف وظیفه برای ایجاد برنامه های اقدام، تزریق دانش عامیانه مربوط به حل کار، استخراج بخش های مهم از مشاهدات، ردیابی پیشرفت کار در حین حفظ اجرای طرح، مدیریت استثناها با تنظیم عمل طرح ها و غیره
هم افزایی بین استدلال و عمل به مدل اجازه می دهد تا استدلال پویا را برای ایجاد، حفظ و تنظیم برنامه های سطح بالا برای عمل (دلیل برای عمل) انجام دهد، در حالی که همچنین با محیط های خارجی (مثلا ویکی پدیا) تعامل داشته باشد تا اطلاعات اضافی را در استدلال بگنجاند. (به دلیل عمل کنید).
تنظیم دقیق ReAct
ما همچنین مدلهای زبان کوچکتر را با استفاده از مسیرهای قالب ReAct بررسی میکنیم. برای کاهش نیاز به حاشیه نویسی انسانی در مقیاس بزرگ، از مدل PaLM-540B برانگیخته شده ReAct برای تولید مسیرها استفاده می کنیم و از مسیرهایی با موفقیت در کار برای تنظیم دقیق مدل های زبان کوچکتر (PaLM-8/62B) استفاده می کنیم.
 |
| مقایسه چهار روش تحریک، (الف) استاندارد، (ب) زنجیره فکر (CoT، فقط دلیل)، (ج) فقط عمل، و (د) ReAct، حل یک سوال HotpotQA. نمونه های درون زمینه حذف شده اند و فقط مسیر کار نشان داده می شود. ReAct میتواند اطلاعاتی را برای پشتیبانی از استدلال بازیابی کند، در حالی که از استدلال برای هدف قرار دادن موارد بعدی استفاده میکند و همافزایی استدلال و عمل را نشان میدهد. |
نتایج
ما ارزیابیهای تجربی ReAct و خطوط پایه پیشرفته را در چهار معیار مختلف انجام میدهیم: پاسخگویی به سؤال (HotPotQA)، تأیید واقعیت (Fever)، بازی مبتنی بر متن (ALFWorld) و ناوبری صفحه وب (WebShop). برای HotPotQA و Fever، با دسترسی به API ویکیپدیا که مدل میتواند با آن تعامل داشته باشد، ReAct از مدلهای تولید کنش وانیلی بهتر عمل میکند در حالی که با عملکرد استدلال زنجیرهای فکر (CoT) رقابت میکند. رویکردی که بهترین نتایج را دارد، ترکیبی از ReAct و CoT است که هم از دانش داخلی و هم از اطلاعات بیرونی بهدستآمده در طول استدلال استفاده میکند.
| HotpotQA (تطابق دقیق، 6 شات) | تب (دقت، 3 تیر) | |
| استاندارد | 28.7 | 57.1 |
| فقط دلیل (CoT) | 29.4 | 56.3 |
| فقط عمل | 25.7 | 58.9 |
| واکنش نشان دهید | 27.4 | 60.9 |
| بهترین روش ReAct + CoT | 35.1 | 64.6 |
| SoTA تحت نظارت | 67.5 (با استفاده از 140 هزار نمونه) | 89.5 (با استفاده از 90 هزار نمونه) |
| PaLM-540B نتایج را در مورد HotpotQA و Fever نشان می دهد. |
در ALFWorld و WebShop، ReAct با هر دو روش یک شات و دو شات بهتر از روشهای یادگیری تقلید و تقویتی که با 105 نمونه کار آموزش دیدهاند، با بهبود مطلق 34% و 10% در میزان موفقیت نسبت به خطوط پایه موجود، بهتر عمل میکند.
| AlfWorld (2-shot) | فروشگاه اینترنتی (1 شات) | |
| فقط اقدام | 45 | 30.1 |
| واکنش نشان دهید | 71 | 40 |
| مبانی یادگیری تقلیدی | 37 (با استفاده از 100 هزار نمونه) | 29.1 (با استفاده از 90 هزار نمونه) |
| PaLM-540B نرخ موفقیت کار را در AlfWorld و WebShop نشان می دهد. |
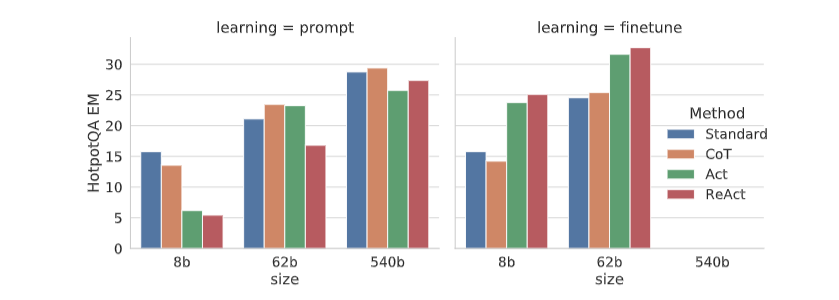 |
| مقیاس بندی نتایج برای درخواست و تنظیم دقیق در HotPotQA با ReAct و خطوط پایه مختلف. ReAct به طور مداوم به بهترین عملکردهای تنظیم دقیق دست می یابد. |
 |
 |
| مقایسه ReAct (بالا) و CoT (پایین) مسیرهای استدلال در مثالی از Fever (مشاهده ReAct برای کاهش فضا حذف شده است). در این مورد ReAct پاسخ درستی را ارائه کرد و میتوان دریافت که مسیر استدلالی ReAct بر خلاف رفتار توهمآمیز CoT بیشتر مبتنی بر حقایق و دانش است. |
ما همچنین با اجازه دادن به بازرس انسانی برای ویرایش ردپای استدلال ReAct، تعاملات انسان در حلقه را با ReAct بررسی میکنیم. ما نشان میدهیم که با جایگزین کردن یک جمله توهمآمیز با نکات بازرس، ReAct میتواند رفتار خود را تغییر دهد تا با ویرایشهای بازرس هماهنگ شود و یک کار را با موفقیت انجام دهد. حل کارها هنگام استفاده از ReAct به طور قابل توجهی آسان تر می شود زیرا فقط به ویرایش دستی چند فکر نیاز دارد که اشکال جدیدی از همکاری انسان و ماشین را امکان پذیر می کند.
 |
| یک مثال اصلاح رفتار انسان در حلقه با ReAct در AlfWorld. (الف) مسیر ReAct به دلیل یک رد استدلال توهمآمیز از کار میافتد (قانون 17). (ب) یک بازرس انسانی دو رد استدلال را ویرایش می کند (قانون 17، 23)، سپس ReAct ردپای استدلالی و اقدامات مطلوبی را برای تکمیل کار ایجاد می کند. |
نتیجه
ما ReAct را ارائه می کنیم، روشی ساده و در عین حال موثر برای هم افزایی استدلال و عمل در مدل های زبانی. از طریق آزمایشهای مختلف که بر پاسخگویی به سؤالات چند جهشی، بررسی واقعیت، و وظایف تصمیمگیری تعاملی تمرکز دارند، نشان میدهیم که ReAct منجر به عملکرد برتر با ردیابیهای تصمیم قابل تفسیر میشود.
ReAct امکان مدلسازی مشترک فکر، اعمال و بازخورد از محیط را در یک مدل زبان نشان میدهد و آن را به عاملی همهکاره تبدیل میکند که قادر به حل وظایفی است که نیاز به تعامل با محیط دارند. ما قصد داریم این خط تحقیقاتی را بیشتر گسترش دهیم و از پتانسیل قوی مدل زبان برای مقابله با وظایف تجسم یافته گسترده تر، از طریق رویکردهایی مانند آموزش چندوظیفه ای عظیم و جفت کردن ReAct با مدل های پاداش به همان اندازه قوی استفاده کنیم.
سپاسگزاریها
مایلیم از جفری ژائو، دیان یو، نان دو، ایژاک شافران و کارتیک ناراسیمهان برای مشارکت بزرگشان در این کار تشکر کنیم. ما همچنین میخواهیم از تیم مغز Google و گروه NLP پرینستون برای حمایت و بازخورد مشترکشان، از جمله محدوده پروژه، مشاوره و بحثهای روشنگرانه تشکر کنیم.