
ما در دنیایی با زیبایی های طبیعی زندگی می کنیم – کوه های باشکوه، مناظر دریایی چشمگیر، و جنگل های آرام. تصور کنید که این زیبایی را مانند پرنده ای ببینید که از کنار مناظر سه بعدی با جزئیات بسیار زیاد پرواز می کند. آیا کامپیوترها می توانند یاد بگیرند که این نوع تجربه بصری را ترکیب کنند؟ چنین قابلیتی به انواع جدیدی از محتوا برای بازیها و تجربههای واقعیت مجازی اجازه میدهد: به عنوان مثال، آرامش در یک پرواز غوطهور از یک صحنه طبیعت بینهایت. اما روشهای موجود که نماهای جدید را از تصاویر ترکیب میکنند، تنها امکان حرکت محدود دوربین را دارند.
در یک تلاش تحقیقاتی ما تماس می گیریم طبیعت بی نهایت، نشان می دهیم که کامپیوترها می توانند یاد بگیرند که چنین تجربیات سه بعدی غنی را به سادگی با مشاهده فیلم ها و عکس های طبیعت تولید کنند. آخرین کار ما در مورد این موضوع، InfiniteNature-Zero (ارائه شده در ECCV 2022) میتواند با استفاده از سیستمی که فقط بر روی عکسهای ثابت آموزش دیده است، تصاویری با وضوح بالا و با کیفیت بالا ایجاد کند که از یک تصویر تک دانه شروع میشود، با استفاده از سیستمی که فقط بر روی عکسهای ثابت آموزش دیده است، قابلیتی که قبلاً دیده نشده بود. ما مشکل اساسی تحقیق را می نامیم نسل دید دائمی: با توجه به یک نمای ورودی واحد از یک صحنه، چگونه میتوانیم مجموعهای از نماهای خروجی واقعگرایانه را که مربوط به یک مسیر سهبعدی خودسرانه طولانی و کنترلشده توسط کاربر از آن صحنه است، ترکیب کنیم؟ تولید نمایش دائمی بسیار چالش برانگیز است زیرا سیستم باید محتوای جدیدی را در طرف دیگر مکانهای دیدنی بزرگ (مثلا کوهها) تولید کند و محتوای جدید را با واقعگرایی بالا و وضوح بالا ارائه کند.
| نمونه پرواز با InfiniteNature-Zero ایجاد شده است. این یک تصویر ورودی منفرد از یک صحنه طبیعی می گیرد و یک مسیر طولانی دوربین را که در آن صحنه پرواز می کند ترکیب می کند و در حین حرکت محتوای صحنه جدیدی تولید می کند. |
پس زمینه: یادگیری Flythrough های سه بعدی از ویدیوها
برای ایجاد اصول اولیه نحوه عملکرد چنین سیستمی، اولین نسخه خود را شرح می دهیم، “طبیعت بی نهایت: نسل نمایش دائمی صحنه های طبیعی از یک تصویر واحد” (ارائه شده در ICCV 2021). در آن کار، رویکرد «یادگیری از ویدیو» را بررسی کردیم، جایی که مجموعهای از ویدیوهای آنلاین گرفتهشده از هواپیماهای بدون سرنشین در حال پرواز در خطوط ساحلی را جمعآوری کردیم، با این ایده که میتوانیم یاد بگیریم که پرندههای جدیدی را که شبیه این ویدیوهای واقعی هستند، ترکیب کنیم. این مجموعه از ویدئوهای آنلاین مجموعه داده تصاویر خط ساحلی هوایی (ACID) نامیده می شود. با این حال، برای یادگیری نحوه ترکیب صحنههایی که به صورت پویا به هر مسیر دوربین سه بعدی دلخواه پاسخ میدهند، نمیتوانیم این ویدیوها را بهعنوان مجموعهای خام از پیکسلها در نظر بگیریم. ما همچنین مجبور شدیم هندسه سه بعدی زیربنایی آنها را محاسبه کنیم، از جمله موقعیت دوربین در هر فریم.
ایده اصلی این است که ما یاد می گیریم که گام به گام پرنده ها را تولید کنیم. با توجه به نمای شروع، مانند تصویر اول در شکل زیر، ابتدا نقشه عمق را با استفاده از روش های پیش بینی عمق تک تصویری محاسبه می کنیم. سپس از آن نقشه عمق استفاده می کنیم ارائه دادن تصویر را به سمت یک نمای دوربین جدید، که در وسط نشان داده شده است، به جلو می برد، که منجر به یک تصویر جدید و نقشه عمق از آن دیدگاه جدید می شود.
با این حال، این تصویر میانی دارای مشکلاتی است – دارای حفره هایی است که می توانیم پشت اشیاء را در مناطقی که در تصویر شروع قابل مشاهده نبودند، ببینیم. همچنین تار است، زیرا ما اکنون به اشیا نزدیکتر هستیم، اما پیکسلهای فریم قبلی را برای نمایش این اشیاء بزرگتر کشیدهایم.
برای رسیدگی به این مشکلات، یک عصبی را یاد می گیریم اصلاح تصویر شبکه ای که این تصویر متوسط با کیفیت پایین را می گیرد و یک تصویر کامل و با کیفیت بالا و نقشه عمق مربوطه را به بیرون می دهد. سپس این مراحل را می توان با این تصویر سنتز شده به عنوان نقطه شروع جدید تکرار کرد. از آنجایی که هم تصویر و هم نقشه عمق را اصلاح میکنیم، این فرآیند میتواند هر چند بار که میخواهید تکرار شود – سیستم بهطور خودکار یاد میگیرد که مناظر جدیدی مانند کوهها، جزایر و اقیانوسها ایجاد کند، همانطور که دوربین بیشتر به سمت صحنه حرکت میکند.
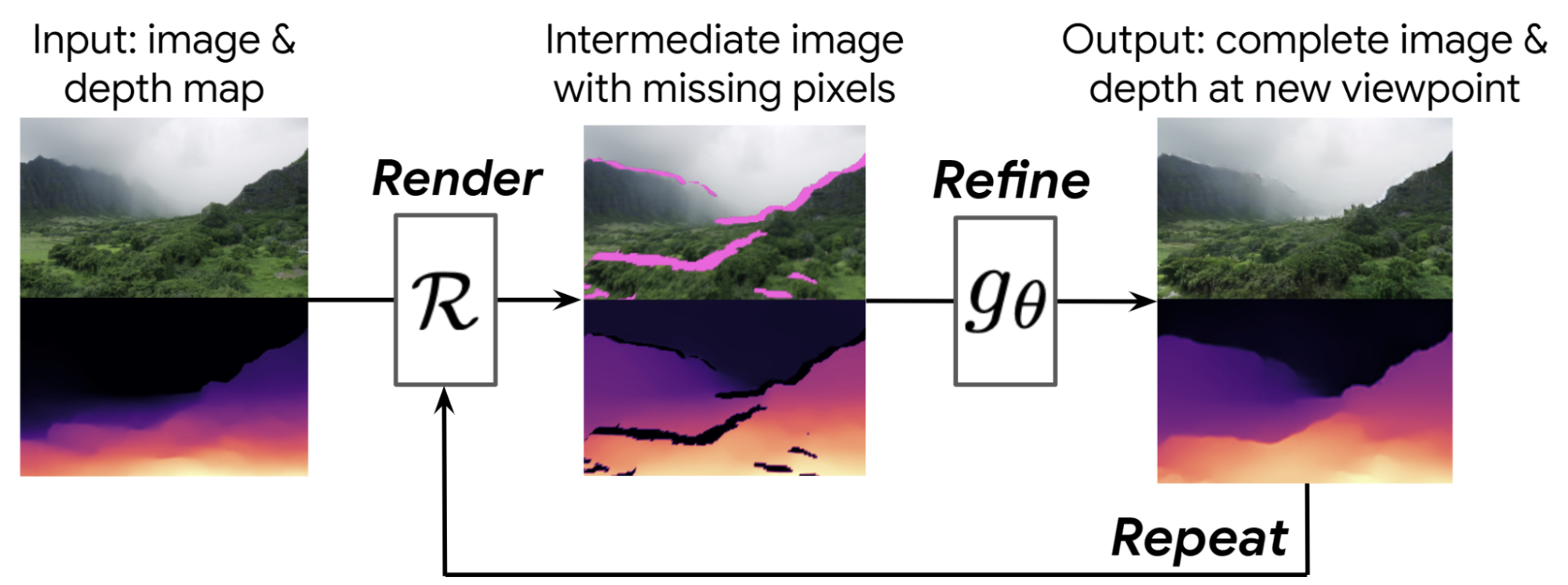 |
| روشهای طبیعت بینهایت ما یک نمای ورودی و نقشه عمق مربوط به آن را میگیرند (ترک کرد). با استفاده از این نقشه عمق، سیستم تصویر ورودی را به یک نمای دلخواه جدید نمایش می دهد (مرکز). این تصویر میانی دارای مشکلاتی است، مانند پیکسلهای از دست رفته در پشت محتوای پیشزمینه (به رنگ سرخابی نشان داده شده است). ما یک شبکه عمیق را یاد می گیریم که این تصویر را برای تولید یک تصویر با کیفیت بالا اصلاح می کند (درست). این فرآیند می تواند تکرار شود تا یک مسیر طولانی از نماها ایجاد شود. بنابراین ما این رویکرد را “render-refine-repeat” می نامیم. |
ما این را آموزش می دهیم render-refine-repeat رویکرد سنتز با استفاده از مجموعه داده ACID. به طور خاص، یک ویدئو از مجموعه داده و سپس یک فریم از آن ویدئو را نمونهبرداری میکنیم. سپس از این روش برای رندر کردن چندین نمای جدید در حال حرکت به داخل صحنه در امتداد همان مسیر دوربین به عنوان ویدیوی حقیقت زمینی استفاده می کنیم، همانطور که در شکل زیر نشان داده شده است، و این فریم های رندر شده را با فریم های ویدیویی حقیقت زمینی مربوطه مقایسه می کنیم تا یک سیگنال آموزشی بدست آوریم. ما همچنین شامل یک تنظیم متخاصم میشویم که سعی میکند فریمهای سنتز شده را از تصاویر واقعی متمایز کند، و تصاویر تولید شده را تشویق میکند تا واقعیتر به نظر برسند.
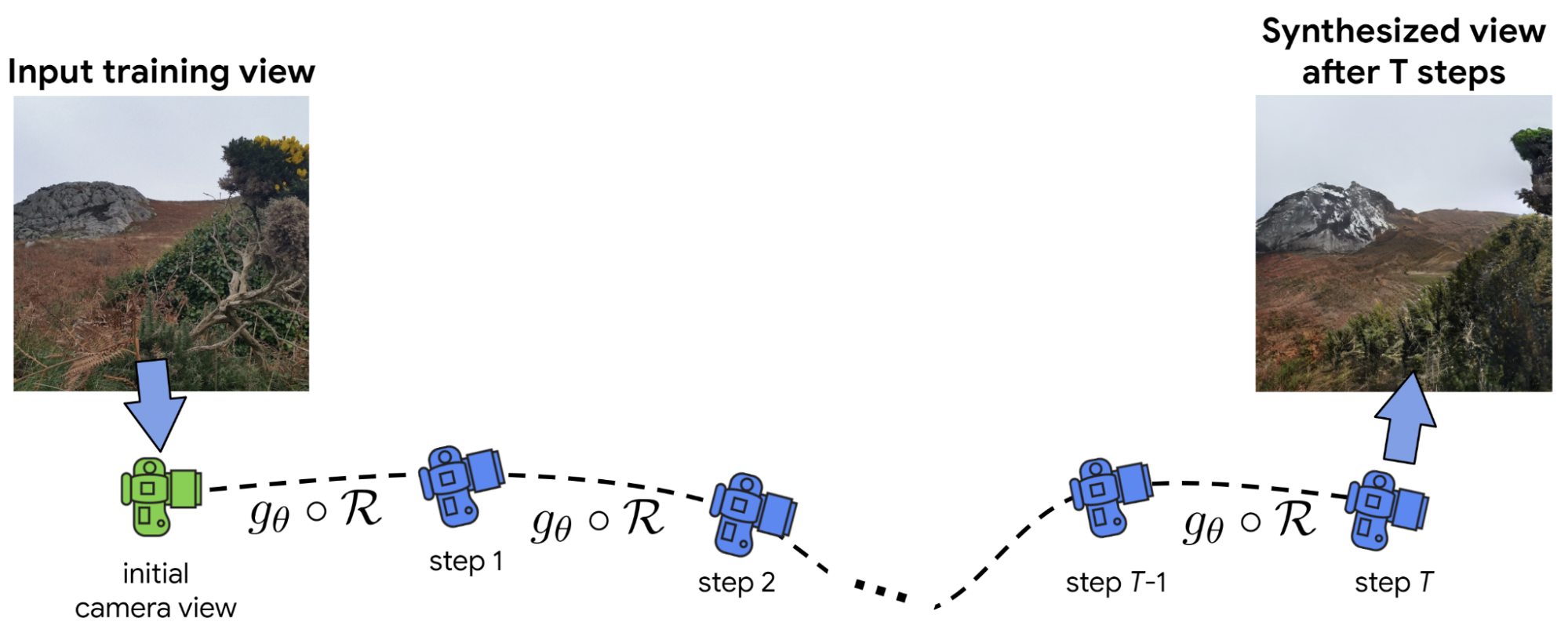 |
| Infinite Nature می تواند نماهای مربوط به هر مسیر دوربین را ترکیب کند. در طول آموزش، ما سیستم خود را برای تی مراحل تولید تی نماها در امتداد یک مسیر دوربین محاسبه شده از یک توالی ویدیوی آموزشی، سپس نماهای ترکیب شده حاصل را با نماهای واقعی مقایسه کنید. در شکل، هر دیدگاه دوربین از دیدگاه قبلی با انجام یک عمل تاب برداشته شده است آرو به دنبال آن عملیات پالایش عصبی انجام می شود gمن. |
سیستم به دست آمده می تواند پروازهای قانع کننده ای را ایجاد کند، همانطور که در صفحه وب پروژه نشان داده شده است، همراه با نسخه نمایشی Colab “شبیه ساز پرواز”. برخلاف روشهای قبلی در سنتز ویدیو، این روش به کاربر اجازه میدهد تا به صورت تعاملی دوربین را کنترل کند و میتواند مسیرهای بسیار طولانیتری برای دوربین ایجاد کند.
InfiniteNature-Zero: آموزش Flythroughs از Still Photos
یکی از مشکلات این رویکرد اول این است که کار با ویدیو به عنوان داده آموزشی دشوار است. یافتن ویدیوی با کیفیت بالا با نوع مناسب حرکت دوربین چالش برانگیز است و کیفیت زیبایی شناختی یک فریم ویدیویی به طور کلی نمی تواند با یک عکس طبیعت که عمداً گرفته شده است مقایسه شود. بنابراین، در “InfiniteNature-Zero: Learning Perpetual View Generation of Natural Scenes from Single Images”، ما بر اساس render-refine-repeat استراتژی بالا، اما راهی برای یادگیری ترکیب دیدگاه دائمی از مجموعههای عکس های ثابت – بدون نیاز به ویدیو ما به این روش می گوییم InfiniteNature-Zero زیرا از ویدیوهای “صفر” یاد می گیرد. در ابتدا، ممکن است این یک کار غیرممکن به نظر برسد – چگونه میتوانیم مدلی را برای تولید تصاویر ویدئویی از صحنهها آموزش دهیم، در حالی که تمام چیزی که تا به حال دیدهایم عکسهای مجزا هستند؟
برای حل این مشکل، ما این بینش کلیدی داشتیم که اگر یک تصویر بگیریم و یک مسیر دوربین را رندر کنیم که یک چرخه – یعنی در جایی که مسیر به عقب برمی گردد به طوری که آخرین تصویر از همان نقطه نظر اول باشد – آنگاه می دانیم که آخرین تصویر سنتز شده در این مسیر باید مانند تصویر ورودی باشد. چنین ثبات چرخه یک محدودیت آموزشی ارائه میکند که به مدل کمک میکند تا یاد بگیرد مناطق از دست رفته را پر کند و وضوح تصویر را در طول هر مرحله از تولید نمای افزایش دهد.
با این حال، آموزش با این چرخههای دوربین برای ایجاد توالیهای دید طولانی و پایدار کافی نیست، بنابراین مانند کار اصلی ما، یک استراتژی متخاصم را شامل میکنیم که مسیرهای طولانی و غیر چرخهای دوربین را در نظر میگیرد، مانند آنچه در شکل بالا نشان داده شده است. به ویژه اگر رندر کنیم تی فریم های یک فریم شروع، ما خود را بهینه می کنیم render-refine-repeat مدلی به گونه ای است که شبکه تفکیک کننده نمی تواند تشخیص دهد که فریم شروع و کدام فریم سنتز شده نهایی است. در نهایت، ما یک مؤلفه را اضافه میکنیم که برای تولید مناطق آسمان با کیفیت بالا آموزش داده شده است تا واقعیت درک نتایج را افزایش دهیم.
با این بینشها، InfiniteNature-Zero را در مورد مجموعهای از عکسهای منظره، که در مقادیر زیادی به صورت آنلاین در دسترس هستند، آموزش دادیم. چندین ویدیوی بهدستآمده در زیر نشان داده شدهاند – اینها مناظر طبیعی زیبا و متنوع را نشان میدهند که میتوان در مسیرهای خودسرانه طولانی دوربین کاوش کرد. در مقایسه با کار قبلی ما – و با روشهای سنتز ویدیوی قبلی – این نتایج پیشرفتهای قابل توجهی را در کیفیت و تنوع محتوا نشان میدهند (جزئیات موجود در مقاله).
| چندین پرواز در طبیعت توسط InfiniteNature-Zero از تک عکس های شروع ایجاد شده است. |
نتیجه
تعدادی مسیر هیجان انگیز آینده برای این کار وجود دارد. برای مثال، روشهای ما در حال حاضر محتوای صحنه را فقط بر اساس فریم قبلی و نقشه عمق آن ترکیب میکنند. هیچ نمایش سه بعدی مستمری وجود ندارد. کار ما به الگوریتمهای آینده اشاره میکند که میتوانند جهانهای سهبعدی کامل، واقعی و سازگار ایجاد کنند.
سپاسگزاریها
Infinite Nature و InfiniteNature-Zero حاصل همکاری محققان در Google Research، UC Berkeley و Cornell University هستند. مشارکت کنندگان کلیدی در کار ارائه شده در این پست عبارتند از انگجو کانازاوا، اندرو لیو، ریچارد تاکر، ژنگچی لی، نوح اسناولی، کیانکیان وانگ، وارون جامپانی، و امیش ماکادیا.