ارائه دهندگان فناوری تبلیغات به طور گسترده از مدلهای یادگیری ماشینی (ML) برای پیشبینی و ارائه مرتبطترین تبلیغات به کاربران و اندازهگیری اثربخشی آن تبلیغات استفاده میکنند. با افزایش تمرکز بر حریم خصوصی آنلاین، فرصتی برای شناسایی الگوریتمهای ML وجود دارد که دارای معاوضههای بهتری برای حفظ حریم خصوصی هستند. حریم خصوصی دیفرانسیل (DP) به عنوان یک چارچوب محبوب برای توسعه الگوریتم های ML به طور مسئولانه با تضمین های حفظ حریم خصوصی قابل اثبات پدیدار شده است. این به طور گسترده در ادبیات حفظ حریم خصوصی مورد مطالعه قرار گرفته است، در برنامه های کاربردی صنعتی مستقر شده و توسط سرشماری ایالات متحده به کار گرفته شده است. به طور شهودی، چارچوب DP، مدلهای ML را قادر میسازد تا ویژگیهای کل جمعیت را یاد بگیرند، در حالی که از اطلاعات سطح کاربر محافظت میکند.
هنگام آموزش مدل های ML، الگوریتم ها یک مجموعه داده را به عنوان ورودی خود می گیرند و یک مدل آموزش دیده را به عنوان خروجی تولید می کنند. نزول گرادیان تصادفی (SGD) یک الگوریتم آموزشی غیرخصوصی است که معمولاً مورد استفاده قرار می گیرد که گرادیان متوسط را از زیر مجموعه ای تصادفی از مثال ها محاسبه می کند (به نام یک مینی دسته) و از آن برای نشان دادن جهتی که مدل باید به سمت آن حرکت کند تا با آن دسته کوچک مطابقت داشته باشد، استفاده می کند. پرکاربردترین الگوریتم آموزشی DP در یادگیری عمیق، توسعه SGD به نام DP-SGD است.
DP-SGD شامل دو مرحله اضافی است: 1) قبل از میانگینگیری، اگر هنجار L2 گرادیان از یک آستانه از پیش تعریفشده فراتر رود، گرادیان هر مثال هنجار بریده میشود. و 2) نویز گاوسی قبل از به روز رسانی مدل به گرادیان متوسط اضافه می شود. DP-SGD را می توان با جایگزین کردن بهینه ساز، مانند SGD یا Adam، با انواع DP خود، با هر خط لوله یادگیری عمیق موجود با حداقل تغییرات سازگار کرد. با این حال، استفاده از DP-SGD در عمل میتواند منجر به از دست دادن قابلتوجه مطلوبیت مدل (یعنی دقت) با سربار محاسباتی بزرگ شود. در نتیجه، تحقیقات مختلف تلاش میکنند تا آموزش DP-SGD را بر روی مسائل کاربردیتر و در مقیاس بزرگتر یادگیری عمیق اعمال کنند. مطالعات اخیر همچنین نتایج امیدوارکنندهای برای آموزش DP در بینایی کامپیوتر و مشکلات پردازش زبان طبیعی نشان دادهاند.
در “مدل سازی تبلیغات خصوصی با DP-SGD”، ما یک مطالعه سیستماتیک از آموزش DP-SGD در مورد مشکلات مدل سازی تبلیغات ارائه می دهیم، که چالش های منحصر به فردی را در مقایسه با وظایف بینایی و زبان ایجاد می کند. مجموعه دادههای تبلیغات اغلب دارای عدم تعادل بالایی بین کلاسهای داده هستند و از ویژگیهای طبقهبندی با تعداد زیادی مقادیر منحصربهفرد تشکیل شدهاند که منجر به مدلهایی میشود که لایههای تعبیهشده بزرگ و بهروزرسانیهای گرادیان بسیار پراکنده دارند. با این مطالعه، ما نشان میدهیم که DP-SGD به مدلهای پیشبینی آگهی اجازه میدهد تا به صورت خصوصی با شکاف کاربردی بسیار کمتر از آنچه قبلاً انتظار میرفت، آموزش داده شوند، حتی در رژیم حفظ حریم خصوصی بالا. علاوه بر این، ما نشان میدهیم که با اجرای صحیح، محاسبات و سربار حافظه آموزش DP-SGD میتواند به میزان قابل توجهی کاهش یابد.
ارزیابی
ما آموزش خصوصی را با استفاده از سه کار پیشبینی تبلیغات ارزیابی میکنیم: (1) پیشبینی نرخ کلیک (pCTR) برای یک تبلیغ، (2) پیشبینی نرخ تبدیل (pCVR) برای یک آگهی پس از یک کلیک، و 3) پیشبینی تعداد مورد انتظار از تبدیل (pConvs) پس از کلیک بر روی تبلیغ. برای pCTR، ما از مجموعه داده Criteo استفاده می کنیم، که یک معیار عمومی پرکاربرد برای مدل های pCTR است. ما pCVR و pConvs را با استفاده از مجموعه دادههای داخلی Google ارزیابی میکنیم. pCTR و pCVR مشکلات طبقهبندی باینری هستند که با از دست دادن آنتروپی متقاطع باینری آموزش داده شدهاند و ما افت AUC آزمایشی را گزارش میکنیم (یعنی 1 – AUC). pConvs یک مشکل رگرسیونی است که با از دست دادن گزارش پواسون (PLL) آموزش داده شده است و ما آزمایش PLL را گزارش می کنیم.
برای هر کار، ما مبادله حریم خصوصی و ابزار DP-SGD را با افزایش نسبی در از دست دادن مدلهای آموزشدیده خصوصی تحت بودجههای مختلف حریم خصوصی (به عنوان مثال، از دست دادن حریم خصوصی) ارزیابی میکنیم. بودجه حفظ حریم خصوصی با یک اسکالر مشخص می شود ه، جایی که پایین تر است ه نشان دهنده حریم خصوصی بالاتر است. برای اندازهگیری شکاف سودمندی بین آموزش خصوصی و غیرخصوصی، افزایش نسبی ضرر را در مقایسه با مدل غیرخصوصی محاسبه میکنیم (معادل ه = ∞). مشاهدات اصلی ما این است که در هر سه کار رایج پیشبینی آگهی، افزایش ضرر نسبی را میتوان بسیار کمتر از آنچه قبلاً انتظار میرفت، حتی برای رژیمهای حریم خصوصی بسیار بالا (به عنوان مثال ε <= 1) انجام داد.
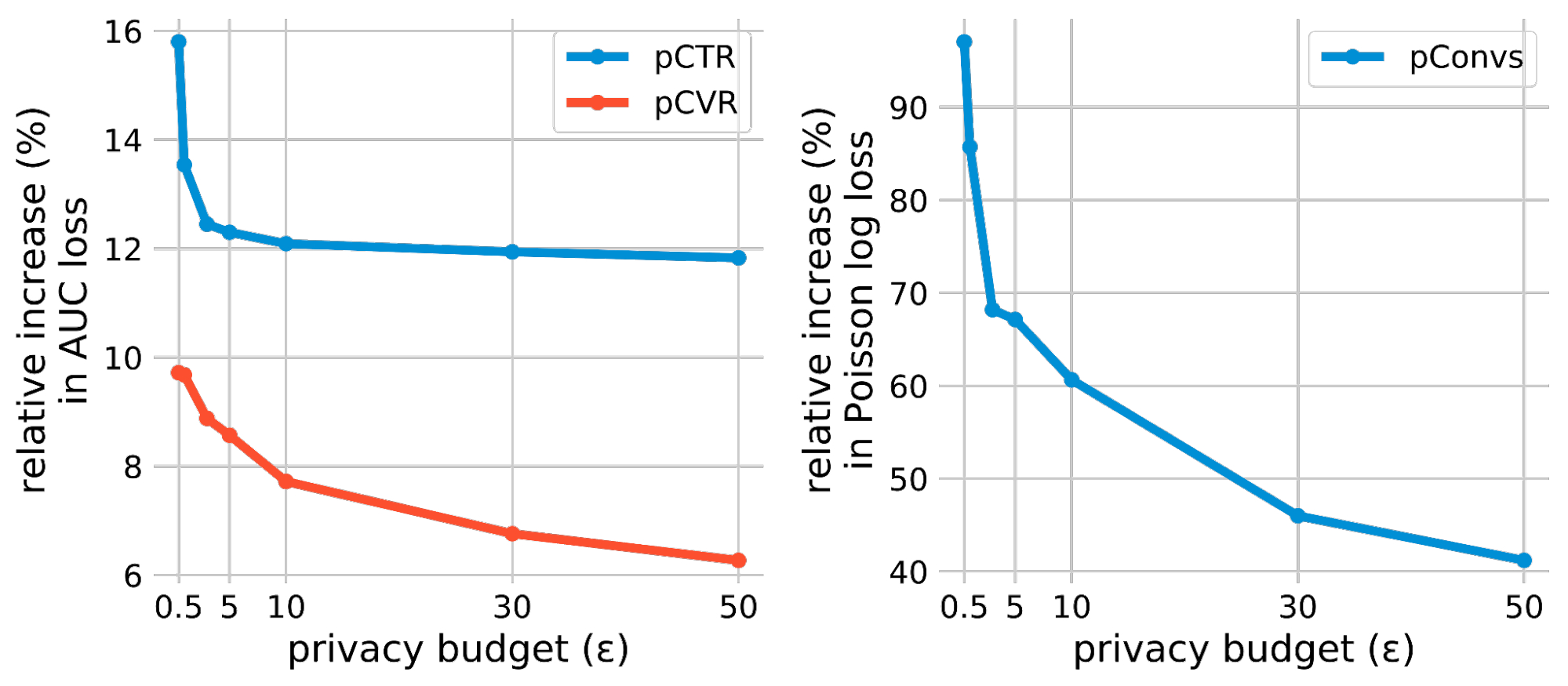 |
| نتایج DP-SGD بر روی سه وظیفه پیشبینی تبلیغات است. افزایش نسبی ضرر در برابر خط پایه غیر خصوصی محاسبه می شود (یعنی ه = ∞) مدل هر کار. |
بهبود حسابداری حریم خصوصی
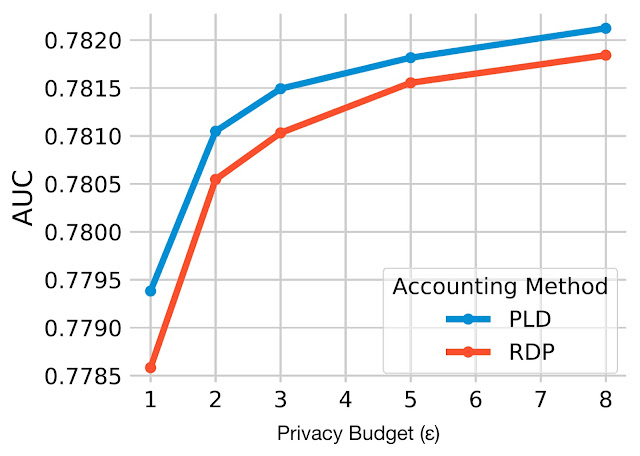
حسابداری حریم خصوصی بودجه حریم خصوصی را برآورد می کند (ه) برای یک مدل آموزش دیده DP-SGD، با توجه به ضرب کننده نویز گاوسی و سایر فراپارامترهای آموزشی. حسابداری Rényi Differential Privacy (RDP) پرکاربردترین رویکرد در DP-SGD از زمان مقاله اصلی بوده است. ما آخرین پیشرفتها در روشهای حسابداری را برای ارائه برآوردهای دقیقتر بررسی میکنیم. به طور خاص، ما از اتصال نقاط برای حسابداری بر اساس توزیع از دست دادن حریم خصوصی (PLD) استفاده می کنیم. شکل زیر این حسابداری بهبود یافته را با حسابداری RDP کلاسیک مقایسه می کند و نشان می دهد که حسابداری PLD AUC را در مجموعه داده pCTR برای تمام بودجه های حریم خصوصی بهبود می بخشد.ه).
 |
آموزش دسته بزرگ
اندازه دسته ای یک فراپارامتر است که بر جنبه های مختلف آموزش DP-SGD تأثیر می گذارد. به عنوان مثال، افزایش اندازه دسته می تواند میزان نویز اضافه شده در طول آموزش را تحت ضمانت حفظ حریم خصوصی یکسان کاهش دهد، که واریانس آموزشی را کاهش می دهد. اندازه دسته همچنین از طریق پارامترهای دیگر، مانند احتمال نمونه برداری فرعی و مراحل آموزشی، بر تضمین حریم خصوصی تأثیر می گذارد. هیچ فرمول ساده ای برای تعیین کمیت تأثیر اندازه دسته وجود ندارد. با این حال، رابطه بین اندازه دسته و مقیاس نویز با استفاده از حسابداری حریم خصوصی، که مقیاس نویز مورد نیاز (که بر حسب انحراف استاندارد اندازهگیری میشود) را تحت یک بودجه حفظ حریم خصوصی محاسبه میکند، اندازهگیری میشود.ه) هنگام استفاده از یک اندازه دسته خاص. شکل زیر چنین روابطی را در دو سناریو مختلف نشان می دهد. سناریوی اول از دورههای ثابت استفاده میکند، که در آن تعداد عبور از مجموعه داده آموزشی را ثابت میکنیم. در این حالت، تعداد مراحل آموزش با افزایش اندازه دسته کاهش مییابد که میتواند منجر به کمآموزی مدل شود. دومین سناریوی ساده تر از مراحل آموزشی ثابت (مراحل ثابت) استفاده می کند.
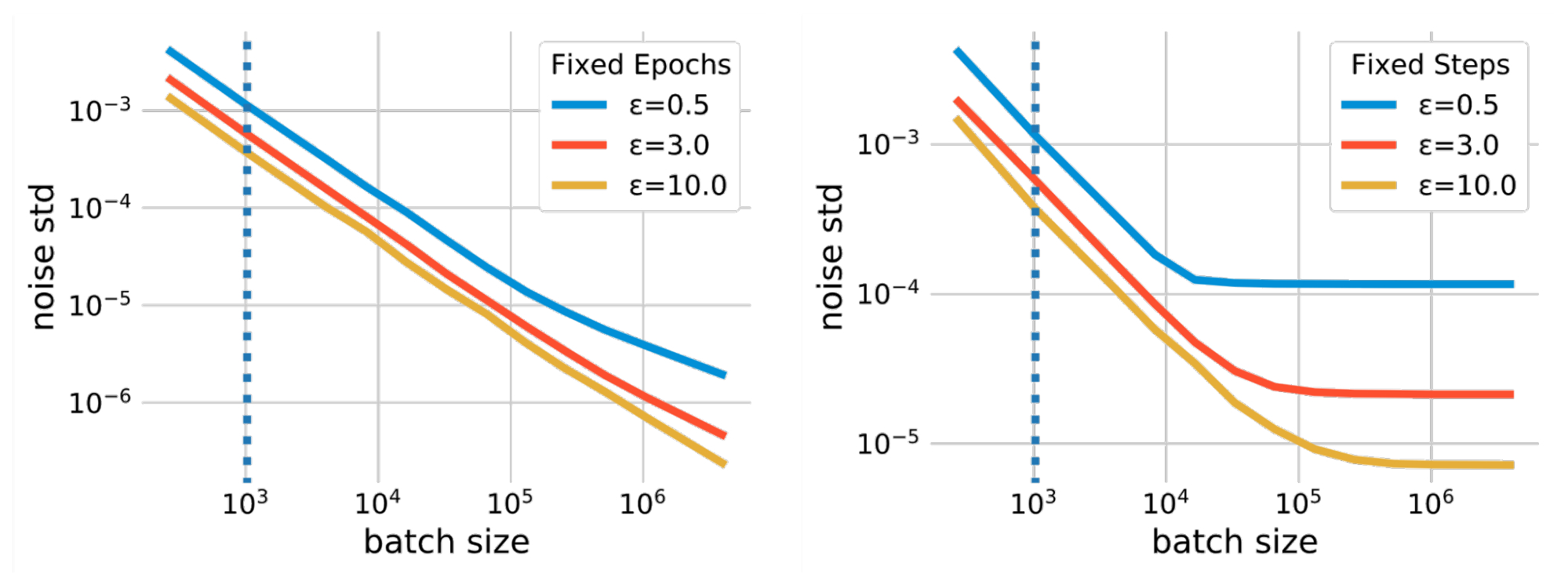 |
| رابطه بین اندازه دسته و مقیاس نویز. حسابداری حریم خصوصی به یک انحراف استاندارد نویز نیاز دارد که با افزایش اندازه دسته ای کاهش می یابد تا بودجه حریم خصوصی مشخصی برآورده شود. در نتیجه، با استفاده از اندازه های دسته ای بسیار بزرگتر از خط پایه غیر خصوصی (که با خط نقطه چین عمودی نشان داده می شود)، مقیاس نویز گاوسی اضافه شده توسط DP-SGD می تواند به طور قابل توجهی کاهش یابد. |
علاوه بر اجازه دادن به مقیاس نویز کوچکتر، اندازههای دستهای بزرگتر همچنین به ما اجازه میدهند تا از آستانه بزرگتری برای برش هنجار هر گرادیان برای هر نمونه، همانطور که توسط DP-SGD نیاز است، استفاده کنیم. از آنجایی که مرحله برش هنجار، سوگیریهایی را در برآورد گرادیان متوسط معرفی میکند، این آرامش، چنین سوگیریهایی را کاهش میدهد. جدول زیر نتایج مربوط به مجموعه داده Criteo را برای pCTR با اندازه دسته ای استاندارد (1024 نمونه) و اندازه دسته بزرگ (16384 نمونه)، همراه با برش بزرگ و افزایش دوره های آموزشی مقایسه می کند. مشاهده میکنیم که آموزش دستهای بزرگ به طور قابلتوجهی کاربرد مدل را بهبود میبخشد. توجه داشته باشید که برش بزرگ فقط با اندازه های بزرگ امکان پذیر است. همچنین مشخص شد که آموزش دستهای بزرگ برای آموزش DP-SGD در حوزههای زبان و بینایی رایانه ضروری است.
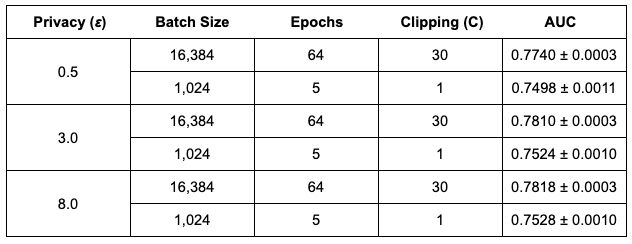 |
| اثرات تمرین دسته ای بزرگ برای سه بودجه مختلف حریم خصوصی (همشاهده می کنیم که هنگام آموزش مدل های pCTR با اندازه دسته بزرگ (16384)، AUC به طور قابل توجهی بیشتر از اندازه دسته معمولی (1024) است. |
محاسبه هنجار گرادیان سریع برای هر مثال
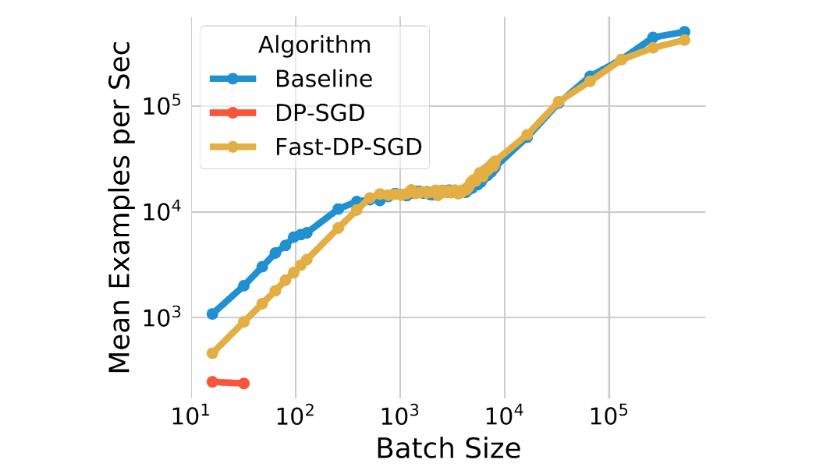
محاسبه هنجار گرادیان هر مثال که برای DP-SGD استفاده می شود، اغلب باعث سربار محاسباتی و حافظه می شود. این محاسبه کارایی پس انتشار استاندارد را در شتاب دهنده ها (مانند GPU) که گرادیان متوسط را برای یک دسته بدون تحقق هر گرادیان هر مثال محاسبه می کنند، حذف می کند. با این حال، برای انواع لایه های شبکه عصبی خاص، یک الگوریتم محاسبه هنجار گرادیان کارآمد، گرادیان هر مثال را امکان پذیر می کند. هنجار بدون نیاز به مادیت کردن گرادیان هر مثال محاسبه شود بردار. همچنین خاطرنشان میکنیم که این الگوریتم میتواند مدلهای شبکه عصبی را که بر روی لایههای تعبیه شده و لایههای کاملاً متصل برای حل مشکلات پیشبینی تبلیغات متکی هستند، به طور موثر مدیریت کند. با ترکیب این دو مشاهده، ما از این الگوریتم برای پیاده سازی نسخه سریع الگوریتم DP-SGD استفاده می کنیم. ما نشان میدهیم که Fast-DP-SGD در pCTR میتواند تعداد مشابهی از نمونههای آموزشی و حداکثر اندازه دستهای را روی یک هسته واحد پردازشگر گرافیکی بهعنوان یک پایه غیرخصوصی انجام دهد.
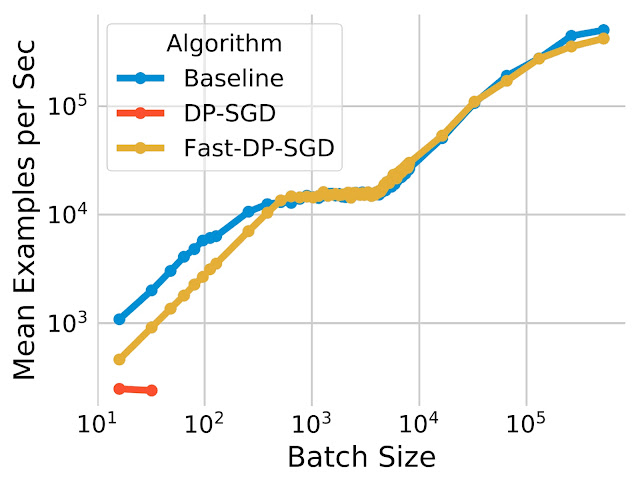 |
| راندمان محاسباتی اجرای سریع ما (Fast-DP-SGD) در pCTR. |
در مقایسه با خط پایه غیر خصوصی، توان عملیاتی آموزشی مشابه است، به جز در اندازه های بسیار کوچک دسته ای. ما همچنین آن را با یک پیادهسازی با استفاده از کامپایل JAX Just-in-Time (JIT) مقایسه میکنیم، که در حال حاضر بسیار سریعتر از پیادهسازی وانیلی DP-SGD است. پیاده سازی ما نه تنها سریعتر است، بلکه کارآمدتر حافظه نیز می باشد. پیادهسازی مبتنی بر JIT نمیتواند اندازههای دستهای بزرگتر از 64 را مدیریت کند، در حالی که پیادهسازی ما میتواند اندازههای دستهای تا 500000 را مدیریت کند. کارایی حافظه برای فعال کردن آموزش دستهای بزرگ مهم است، که در بالا نشان داده شد که برای بهبود کاربرد مهم است.
نتیجه
ما نشان دادهایم که آموزش مدلهای پیشبینی تبلیغات خصوصی با استفاده از DP-SGD که دارای شکاف کاربردی کوچکی در مقایسه با خطوط پایه غیرخصوصی هستند، با حداقل هزینه برای محاسبات و مصرف حافظه امکانپذیر است. ما معتقدیم که فضایی برای کاهش بیشتر شکاف ابزار از طریق تکنیک هایی مانند قبل از آموزش وجود دارد. لطفاً مقاله را برای جزئیات کامل آزمایش ها ببینید.
سپاسگزاریها
این کار با همکاری کارسون دنیسون، بدیه غازی، پریتیش کامات، راوی کومار، پسین مانورنگسی، عامر سینها و آویناش وارادارجان انجام شد. ما از Silvano Bonacina و Samuel Ieong برای بسیاری از بحث های مفید تشکر می کنیم.