یکی از مهمترین جنبههای یادگیری ماشین، بهینهسازی هایپرپارامتر است، زیرا یافتن فراپارامترهای مناسب برای یک کار یادگیری ماشینی میتواند عملکرد یک مدل را تغییر دهد یا آن را خراب کند. در داخل، ما مرتباً از Google Vizier به عنوان پلتفرم پیشفرض برای بهینهسازی هایپرپارامتر استفاده میکنیم. Google Vizier در طول استقرار خود در طول 5 سال گذشته بیش از 10 میلیون بار در کلاس وسیعی از برنامههای کاربردی، از جمله برنامههای یادگیری ماشین از دید، یادگیری تقویتی و زبان و همچنین برنامههای علمی مانند کشف پروتئین و شتاب سختافزار استفاده شده است. . از آنجایی که Google Vizier قادر است الگوهای استفاده را در پایگاه داده خود پیگیری کند، چنین داده هایی که معمولاً از مسیرهای بهینه سازی تشکیل شده اند، نامیده می شوند. مطالعات، حاوی اطلاعات قبلی بسیار ارزشمند در مورد اهداف تنظیم فراپارامتر واقعی است و بنابراین برای توسعه الگوریتم های بهتر بسیار جذاب است.
در حالی که بسیاری از روشهای قبلی برای فرایادگیری بر روی چنین دادههایی وجود داشته است، چنین روشهایی یک اشکال مشترک عمده دارند: روشهای فرایادگیری آنها به شدت به محدودیتهای عددی مانند تعداد فراپارامترها و محدودههای ارزش آنها بستگی دارد، و بنابراین نیاز به تمام وظایف دقیقاً از همان فضای جستجوی کل فراپارامتر (یعنی تنظیم مشخصات) استفاده کنید. اطلاعات متنی اضافی در مطالعه، مانند توضیحات و نام پارامترها، نیز به ندرت مورد استفاده قرار می گیرند، اما می توانند اطلاعات معنی داری در مورد نوع کار بهینه سازی شده در خود داشته باشند. چنین اشکالی برای مجموعه داده های بزرگتر که اغلب حاوی مقادیر قابل توجهی از چنین اطلاعات معناداری هستند تشدید می شود.
امروز در “به سوی یادگیری بهینه سازهای فراپارامتر جهانی با ترانسفورماتور”، ما هیجان زده هستیم که OptFormer، یکی از اولین چارچوب های مبتنی بر ترانسفورماتور برای تنظیم هایپرپارامتر، از داده های بهینه سازی در مقیاس بزرگ با استفاده از نمایش های مبتنی بر متن انعطاف پذیر آموخته شد. در حالی که آثار متعددی قبلاً تواناییهای قوی ترانسفورماتور را در حوزههای مختلف نشان دادهاند، تعداد کمی روی قابلیتهای مبتنی بر بهینهسازی آن، بهویژه در فضای متن، دست زدهاند. یافته های اصلی ما برای اولین بار برخی از توانایی های الگوریتمی جالب ترانسفورماتورها را نشان می دهد: 1) یک شبکه ترانسفورماتور واحد قادر به تقلید رفتارهای بسیار پیچیده از الگوریتم های متعدد در افق های طولانی است. 2) شبکه قادر است مقادیر هدف را با دقت بسیار زیادی پیش بینی کند، در بسیاری از موارد از فرآیندهای گاوسی که معمولاً در الگوریتم هایی مانند بهینه سازی بیزی استفاده می شود، پیشی می گیرد.
رویکرد: نشان دادن مطالعات به عنوان نشانه
روش جدید ما به جای استفاده از داده های عددی به عنوان رایج با روش های قبلی، در عوض از مفاهیم زبان طبیعی استفاده می کند و نشان می دهد. همه داده های مطالعه به عنوان دنباله ای از نشانه ها، از جمله اطلاعات متنی از ابرداده های اولیه. در انیمیشن زیر، این شامل «CIFAR10»، «نرخ یادگیری»، «نوع بهینهساز» و «دقت» است که OptFormer را از یک کار طبقهبندی تصویر مطلع میکند. سپس OptFormer ابرپارامترهای جدیدی را برای امتحان کردن کار تولید میکند، دقت کار را پیشبینی میکند و در نهایت دقت واقعی را دریافت میکند که برای تولید فراپارامترهای دور بعدی استفاده میشود. با استفاده از پایگاه کد T5X، OptFormer در یک روش رمزگذار-رمزگشای معمولی با استفاده از پیشآموزش مولد استاندارد بر روی طیف گستردهای از اهداف بهینهسازی فراپارامتر، از جمله دادههای دنیای واقعی جمعآوریشده توسط Google Vizier، و همچنین هایپرپارامتر عمومی (HPO-B) و جعبه سیاه آموزش داده میشود. معیارهای بهینه سازی (BBOB).
 |
| OptFormer می تواند سبک رمزگذار-رمزگشای بهینه سازی هایپرپارامتر را با استفاده از نمایش های مبتنی بر توکن انجام دهد. در ابتدا ابرداده مبتنی بر متن (در کادر خاکستری) حاوی اطلاعاتی مانند عنوان، نام پارامترهای فضای جستجو و معیارهایی را برای بهینهسازی مشاهده میکند و مکرراً پیشبینیهای پارامتر و ارزش هدف را خروجی میدهد. |
سیاست های تقلید
از آنجایی که OptFormer بر روی مسیرهای بهینه سازی توسط الگوریتم های مختلف آموزش دیده است، اکنون ممکن است به طور همزمان از چنین الگوریتم هایی تقلید کند. با ارائه یک اعلان مبتنی بر متن در فراداده برای الگوریتم تعیین شده (به عنوان مثال “تکامل منظم”)، OptFormer رفتار الگوریتم را تقلید می کند.
 |
| OptFormer بر روی یک تابع آزمایشی غیرقابل مشاهده، منحنی های بهینه سازی تقریباً یکسانی را با الگوریتم اصلی تولید می کند. نوارهای خطای میانگین و انحراف استاندارد نشان داده شده است. |
پیش بینی ارزش های عینی
علاوه بر این، OptFormer اکنون ممکن است مقدار هدف در حال بهینه سازی را پیش بینی کند (به عنوان مثال دقت) و تخمین های عدم قطعیت ارائه دهد. ما پیشبینی OptFormer را با یک فرآیند استاندارد گاوسی مقایسه کردیم و دریافتیم که OptFormer میتواند پیشبینیهای بسیار دقیقتری انجام دهد. این را می توان از نظر کیفی در زیر مشاهده کرد، جایی که منحنی کالیبراسیون OptFormer از خط مورب ایدهآل در یک تست خوب بودن و از نظر کمی از طریق معیارهای کل استاندارد مانند چگالی پیشبینی لاگ پیروی میکند.
ترکیب هر دو: بهینه سازی مبتنی بر مدل
اکنون میتوانیم از قابلیت پیشبینی عملکرد OptFormer برای هدایت بهتر خطمشی تقلیدمان، مشابه تکنیکهای موجود در بهینهسازی بیزی، استفاده کنیم. با استفاده از نمونهبرداری تامپسون، ممکن است پیشنهادات خطمشی تقلید خود را رتبهبندی کنیم و فقط بهترین را بر اساس پیشبینیکننده تابع انتخاب کنیم. این یک خطمشی تقویتشده ایجاد میکند که قادر به عملکرد بهتر از الگوریتم بهینهسازی بیزی درجه صنعتی ما در Google Vizier در هنگام بهینهسازی اهداف معیار مصنوعی کلاسیک و تنظیم فراپارامترهای نرخ یادگیری یک خط لوله آموزشی استاندارد CIFAR-10 است.
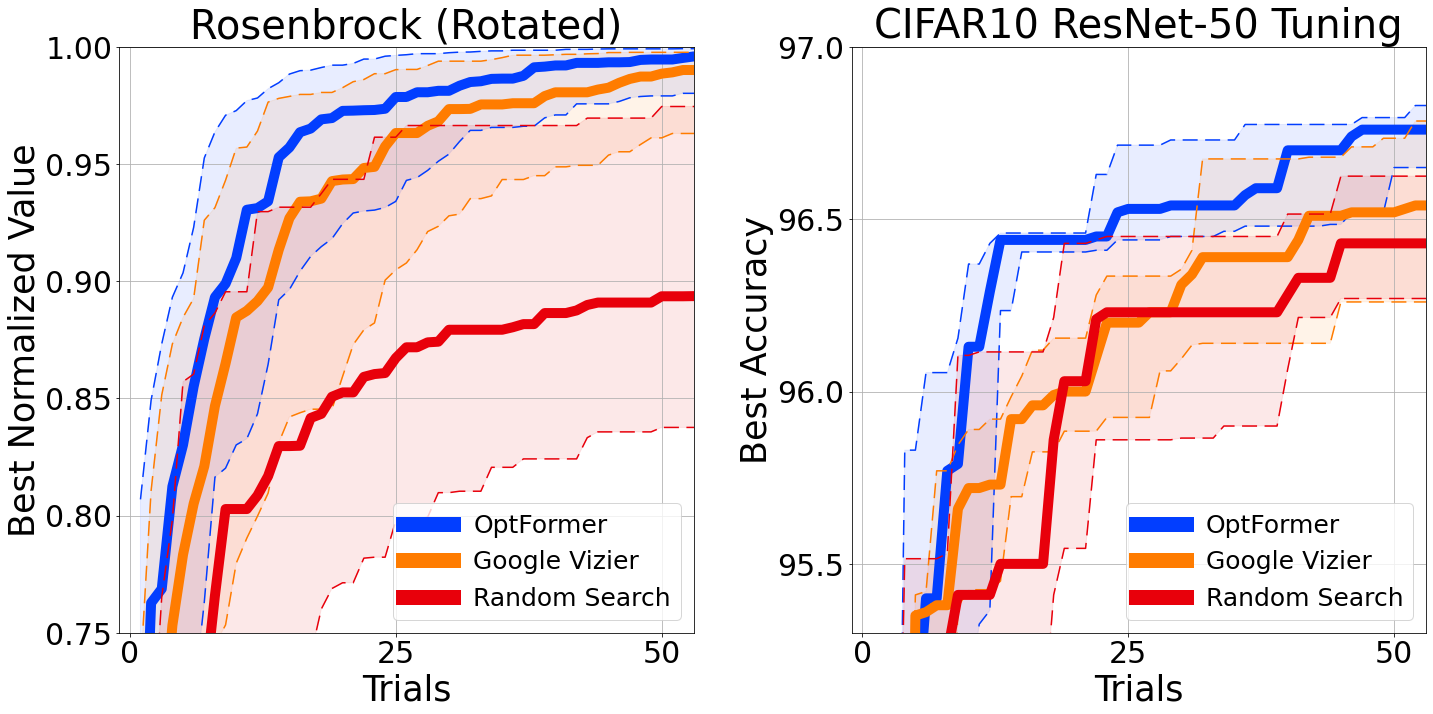 |
| ترک کرد: بهترین منحنی بهینه سازی تا کنون بر روی یک تابع کلاسیک روزنبراک. درست: بهترین منحنی بهینهسازی تا کنون بر روی فراپارامترها برای آموزش ResNet-50 در CIFAR-10 از طریق init2winit. هر دو مورد از 10 دانه در هر منحنی و نوارهای خطا در صدک های 25 و 75 استفاده می کنند. |
نتیجه
در طول این کار، ما برخی از قابلیتهای بهینهسازی مفید و ناشناخته ترانسفورماتور را کشف کردیم. در آینده، ما امیدواریم که راه را برای یک رابط جهانی بهینه سازی هایپرپارامتر و جعبه سیاه برای استفاده از داده های عددی و متنی برای تسهیل بهینه سازی در فضاهای جستجوی پیچیده، و ادغام OptFormer با بقیه اکوسیستم Transformer (مانند زبان، دید، کد) با استفاده از مجموعه عظیم Google از داده های AutoML آفلاین.
سپاسگزاریها
اعضای زیر DeepMind و تیم تحقیقاتی مغز گوگل این تحقیق را انجام دادند: Yutian Chen، Xingyou Song، Chansoo Lee، Zi Wang، Qiuyi Zhang، David Dohan، Kazuya Kawakami، Greg Kochanski، Arnaud Doucet، Marc’aurelio Ranzato، Sagi Perel، و ناندو دی فریتاس.
همچنین میخواهیم از کریس دایر، لوک متز، کوین مورفی، یانیس اسائل، فرانک هاتر و استبان رئال برای ارائه بازخورد ارزشمند تشکر کنیم و از سباستین پیندا آرانگو، کریستوف آنگرمولر و زکری نادو برای بحثهای فنی در مورد معیارها تشکر کنیم. علاوه بر این، ما از دانیل گولووین، دائی پنگ، یینگجی میائو، جک پارکر هولدر، جی تان، لوسیو دری و الکساندرا فاوست برای چندین مکالمه مفید تشکر می کنیم.
در پایان از تام اسمال برای طراحی انیمیشن این پست تشکر می کنیم.