
مدلهای یادگیری عمیق معاصر در بسیاری از حوزهها، از زبان طبیعی گرفته تا بینایی رایانه، بهطور چشمگیری موفق بودهاند. شبکههای عصبی ترانسفورماتور (ترانسفورماتورها) یک معماری یادگیری عمیق محبوب هستند که امروزه پایه و اساس اکثر وظایف در پردازش زبان طبیعی را تشکیل میدهند و همچنین شروع به گسترش به برنامههای کاربردی در حوزههای دیگر، مانند بینایی کامپیوتر، رباتیک، و رانندگی مستقل کردهاند. علاوه بر این، آنها ستون فقرات همه مدلهای زبانی پیشرفته را تشکیل میدهند.
افزایش مقیاس در شبکه های ترانسفورماتور منجر به بهبود عملکرد و ظهور رفتاری شده است که در شبکه های کوچکتر وجود ندارد. با این حال، این افزایش در مقیاس اغلب با افزایش غیرمنتظره در هزینه محاسباتی و تأخیر استنتاج همراه است. یک سوال طبیعی این است که آیا می توانیم از مزایای مدل های بزرگتر بدون تحمل بار محاسباتی بهره مند شویم؟
در «بهروزرسانیهای متناوب برای ترانسفورماتورهای کارآمد»، که در NeurIPS 2023 بهعنوان یک کانون توجه پذیرفته شد، AltUp را معرفی میکنیم، روشی برای استفاده از افزایش نمایش توکن بدون افزایش هزینههای محاسباتی. اجرای AltUp آسان است، به طور گسترده برای هر معماری ترانسفورماتور قابل استفاده است و به حداقل تنظیم هایپرپارامتر نیاز دارد. به عنوان مثال، با استفاده از یک نوع AltUp در مدل T5-Large با پارامتر 770M، افزودن 100 پارامتر به مدلی با کیفیت بسیار بهتری میدهد.
زمینه
برای درک اینکه چگونه می توانیم به این هدف دست یابیم، نحوه کار ترانسفورماتورها را بررسی می کنیم. اول، آنها ورودی را به دنباله ای از توکن ها تقسیم می کنند. سپس هر نشانه به یک بردار تعبیه شده (از طریق یک جدول جاسازی) نگاشت می شود که به آن جاسازی توکن می گویند. ما بعد این بردار را بعد نمایش نشانه می نامیم. سپس ترانسفورماتور با اعمال یک سری ماژولهای محاسباتی (به نام لایهها) روی این دنباله از توکنهای تعبیهشده کار میکند.) با استفاده از پارامترهای شبکه آن تعداد پارامترها در هر لایه ترانسفورماتور تابعی از لایه است عرض، که توسط بعد نمایش نشانه تعیین می شود.
برای دستیابی به مزایای مقیاس بدون تحمیل بار محاسباتی، کارهای قبلی مانند مدلهای ترکیبی پراکنده (Sparse MoE) (مانند Switch Transformer، Expert Choice، V-MoE) عمدتاً بر افزایش کارآمد پارامترهای شبکه متمرکز شدهاند. در لایههای خود توجه و پیشخور) با فعال کردن مشروط یک زیرمجموعه بر اساس ورودی. این به ما امکان می دهد تا اندازه شبکه را بدون افزایش محاسباتی در هر ورودی به میزان قابل توجهی افزایش دهیم. با این حال، یک شکاف تحقیقاتی در افزایش مقیاس خود بعد نمایش توکن با فعال کردن مشروط بخشهایی از بردار نمایش نشانه وجود دارد.
کارهای اخیر (به عنوان مثال، قوانین مقیاسبندی و شبکههای با عرض نامتناهی) بهطور تجربی و نظری ثابت کردهاند که نمایش توکن گستردهتر به یادگیری توابع پیچیدهتر کمک میکند. این پدیده در معماری های مدرن با قابلیت فزاینده نیز مشهود است. به عنوان مثال، بعد نمایش از 512 (کوچک) به 768 (پایه) و 1024 (مرتبط با مدل هایی با پارامترهای 770M، 3B و 11B به ترتیب) در مدل های T5 و از 4096 (8B) به 8192 (684B) و 1024 افزایش می یابد. (540B) در مدل های PalM. بعد بازنمایی گسترده نیز به طور قابل توجهی عملکرد مدل های بازیابی رمزگذار دوگانه را بهبود می بخشد. با این حال، گسترش ساده بردار نمایش مستلزم افزایش ابعاد مدل بر این اساس است، که به صورت درجه دوم1 مقدار محاسبات را در محاسبات پیشخور افزایش می دهد.
روش
AltUp با پارتیشن بندی یک بردار بازنمایی گسترده به بلوک های با اندازه مساوی، پردازش تنها یک بلوک در هر لایه و استفاده از مکانیزم پیش بینی-اصلاح کارآمد برای استنتاج خروجی های بلوک های دیگر (در زیر در سمت راست) کار می کند. این به AltUp اجازه می دهد تا به طور همزمان بعد مدل، بنابراین هزینه محاسبات را تقریباً ثابت نگه دارد و از استفاده از یک بعد توکن افزایش یافته استفاده کند. بعد توکن افزایش یافته به مدل اجازه می دهد تا اطلاعات بیشتری را در جاسازی هر توکن قرار دهد. با ثابت نگه داشتن عرض هر لایه ترانسفورماتور، AltUp از تحمیل افزایش درجه دوم در هزینه محاسباتی جلوگیری می کند که در غیر این صورت با یک بسط ساده نمایش وجود خواهد داشت.
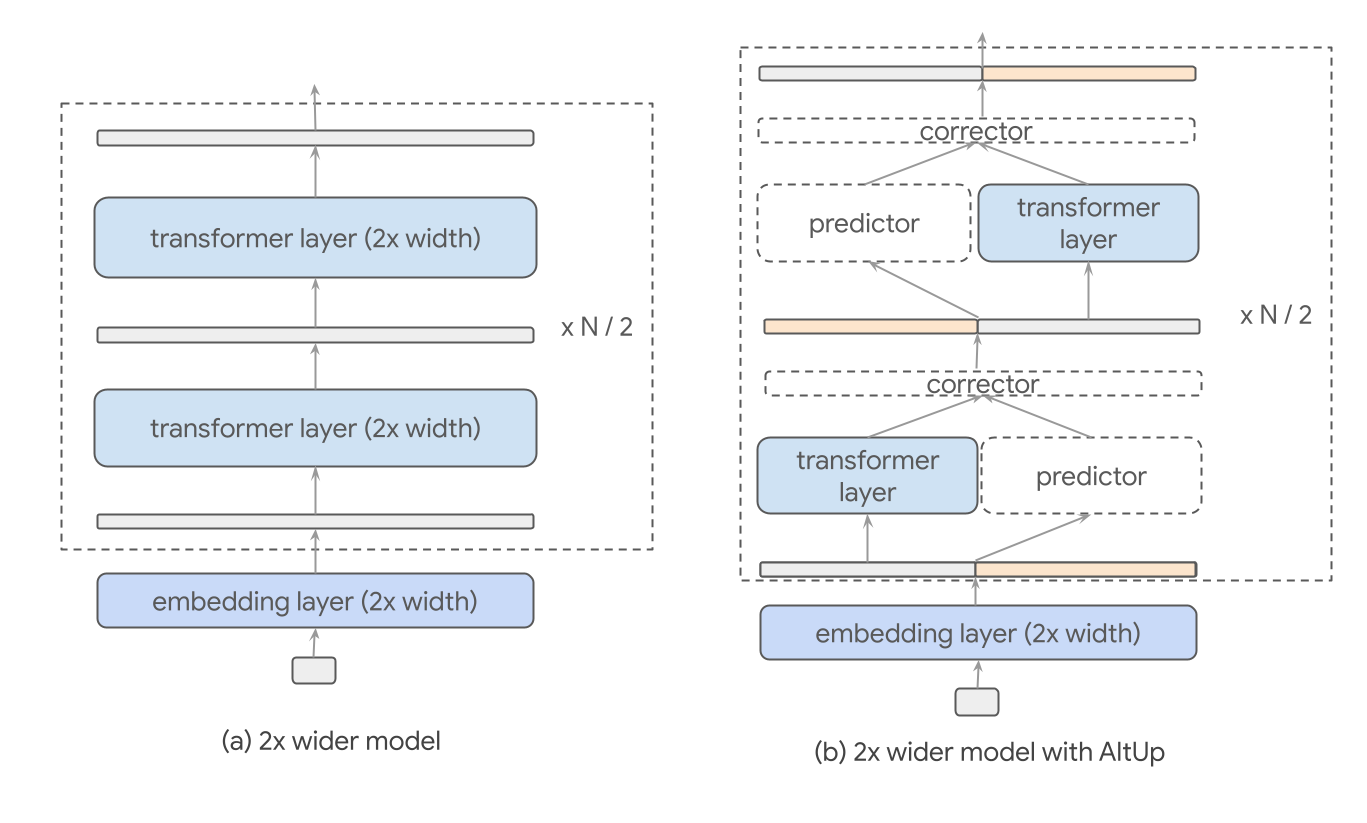 |
| تصویری از گسترش نمایش نشانه بدون (ترک کرد) و با AltUp (درست). این گشاد شدن باعث افزایش تقریباً درجه دوم در محاسبات در ترانسفورماتور وانیلی به دلیل افزایش عرض لایه می شود. در مقابل، بهروزرسانیهای متناوب، عرض لایه را ثابت نگه میدارد و خروجی را با عملکرد بر روی یک بلوک فرعی از نمایش در هر لایه، به طور موثر محاسبه میکند. |
به طور خاص، ورودی هر لایه دو یا چند بلوک است که یکی از آنها به لایه ترانسفورماتور عرض 1x منتقل می شود (شکل زیر را ببینید). ما به این بلوک به عنوان بلوک “فعال شده” اشاره می کنیم. این محاسبه منجر به خروجی دقیق بلوک فعال می شود. به موازات آن، یک پیش بینی سبک وزن را فراخوانی می کنیم که ترکیب وزنی از تمام بلوک های ورودی را محاسبه می کند. مقادیر پیشبینیشده، همراه با مقدار محاسبهشده بلوک فعال شده، به یک تصحیحکننده سبک منتقل میشوند که پیشبینیها را بر اساس مقادیر مشاهدهشده بهروزرسانی میکند. این مکانیسم اصلاح بلوک های غیرفعال شده را قادر می سازد تا به عنوان تابعی از بلوک فعال شده به روز شوند. هر دو مرحله پیشبینی و تصحیح فقط شامل تعداد محدودی از جمعها و ضربهای بردار هستند و از این رو بسیار سریعتر از یک لایه ترانسفورماتور معمولی هستند. توجه داریم که این رویه را می توان به تعداد دلخواه بلوک تعمیم داد.
 |
| محاسبات پیش بینی کننده و تصحیح کننده: پیش بینی بلوک های فرعی را با ضرایب اسکالر قابل آموزش مخلوط می کند. تصحیح کننده میانگین وزنی خروجی پیش بینی کننده و خروجی ترانسفورماتور را برمی گرداند. پیشبینیکننده و تصحیحکننده ضربهای اسکالر بردار را انجام میدهند و هزینه محاسباتی ناچیزی را در مقایسه با ترانسفورماتور متحمل میشوند. پیش بینی اختلاط خطی بلوک ها با ضرایب اختلاط اسکالر p را خروجی می دهدمن، ج و تصحیح کننده خروجی پیش بینی کننده و خروجی ترانسفورماتور را با وزن های g ترکیب می کندمن. |
در سطح بالاتر، AltUp شبیه MoE پراکنده است زیرا روشی برای افزودن ظرفیت به مدل در قالب پارامترهای مشروط (خارجی) است. در Sparse MoE، پارامترهای اضافی به صورت خبرگان شبکه پیشخور (FFN) هستند و مشروط بودن با توجه به ورودی است. در AltUp، پارامترهای خارجی از جدول تعبیهشده گسترده میآیند و شرطیسازی به شکل فعالسازی متناوب بلوک بردار نمایش مانند شکل بالا است. از این رو، AltUp دارای پشتوانه مشابهی با مدلهای Sparse MoE است.
یکی از مزایای AltUp نسبت به Sparse MoE این است که نیازی به اشتراک گذاری ندارد زیرا تعداد پارامترهای اضافی معرفی شده یک عامل است.2 اندازه جدول تعبیه شده، که معمولاً بخش کوچکی از اندازه کلی مدل را تشکیل می دهد. علاوه بر این، از آنجایی که AltUp روی فعال کردن بخشهای یک نمایش توکن گستردهتر متمرکز است، میتوان آن را به صورت همافزایی با تکنیکهای متعامد مانند MoE برای به دست آوردن دستاوردهای عملکرد مکمل اعمال کرد.
ارزیابی
AltUp بر روی مدل های T5 در وظایف مختلف زبان معیار ارزیابی شد. مدلهای تقویتشده با AltUp به طور یکنواخت سریعتر از مدلهای متراکم برونیابی شده با همان دقت هستند. برای مثال، مشاهده میکنیم که یک مدل T5 Large که با AltUp تقویت شده است، به ترتیب منجر به افزایش سرعت 27، 39، 87 و 29 درصدی در معیارهای GLUE، SuperGLUE، SQuAD و Trivia-QA میشود.
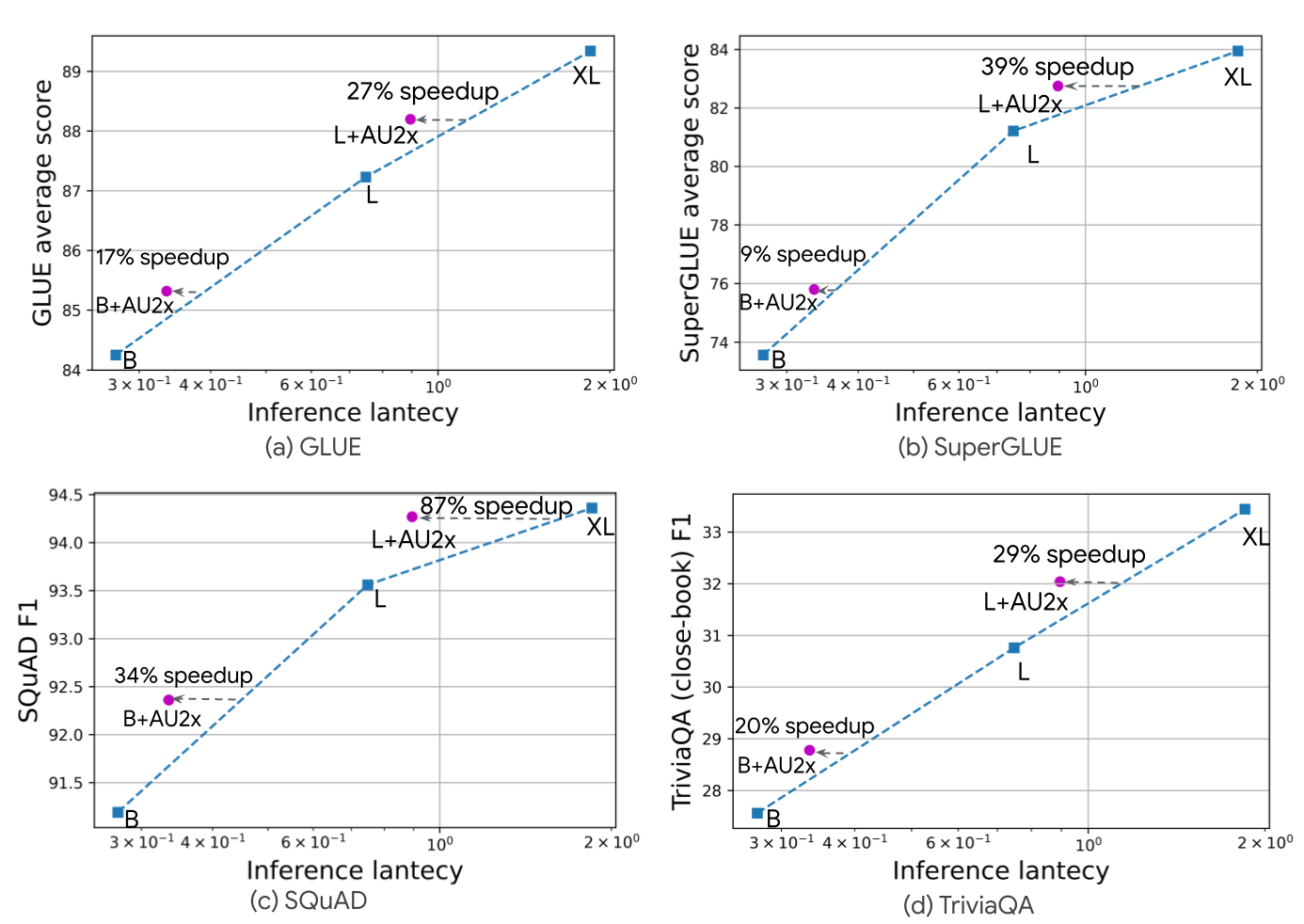 |
| ارزیابی AltUp در مدل های T5 در اندازه های مختلف و معیارهای محبوب. AltUp به طور مداوم منجر به افزایش سرعت قابل توجهی نسبت به خطوط پایه با دقت یکسان می شود. تأخیر در TPUv3 با 8 هسته اندازه گیری می شود. Speedup به عنوان تغییر در تأخیر تقسیم بر تأخیر AltUp (مدل های B = T5 Base، L = T5 Large، XL = T5 XL) تعریف می شود. |
عملکرد نسبی AltUp با اعمال آن در مدلهای بزرگتر بهبود مییابد – سرعت نسبی T5 Base + AltUp را با T5 Large + AltUp مقایسه کنید. این مقیاس پذیری AltUp و عملکرد بهبود یافته آن را در مدل های حتی بزرگتر نشان می دهد. به طور کلی، AltUp به طور مداوم به مدلهایی با عملکرد پیشبینی بهتر نسبت به مدلهای پایه مربوطه با سرعت یکسان در تمام اندازهها و معیارهای مدل ارزیابیشده منجر میشود.
برنامه های افزودنی: AltUp بازیافتی
فرمول AltUp مقدار ناچیزی از محاسبات در هر لایه را اضافه می کند، با این حال، نیاز به استفاده از جدول تعبیه گسترده تری دارد. در سناریوهای خاصی که اندازه واژگان (یعنی تعداد توکنهای متمایز که توکنایزر میتواند تولید کند) بسیار زیاد است، این ممکن است منجر به یک محاسبات غیر ضروری برای جستجوی تعبیه اولیه و عملیات خطی + نرمافزار نهایی شود. واژگان بسیار بزرگ نیز ممکن است منجر به مقدار نامطلوب پارامترهای تعبیه شده شود. برای رفع این مشکل، Recycled-AltUp توسعهای از AltUp است که با ثابت نگه داشتن عرض جدول جاسازی، از این هزینههای محاسباتی و پارامتری جلوگیری میکند.
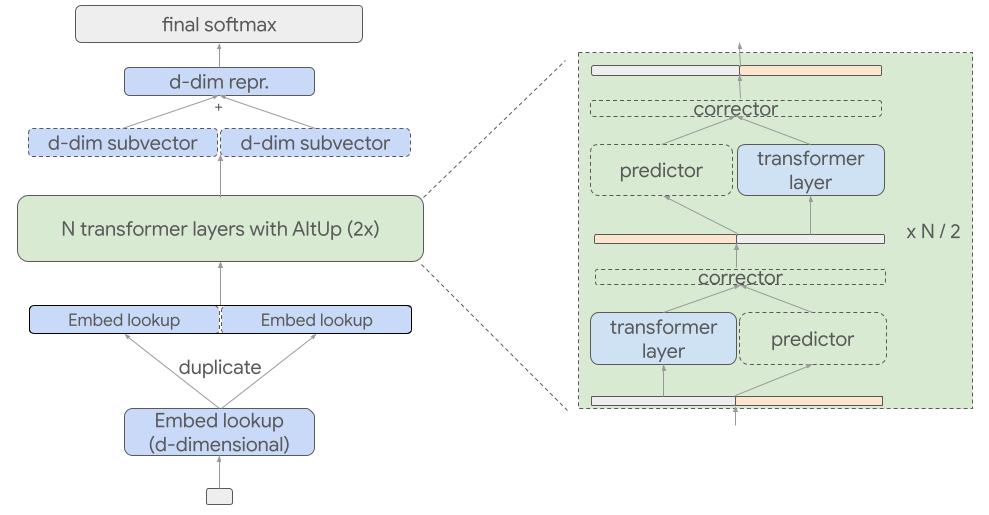 |
| تصویری از معماری برای بازیافت-AltUp با ک = 2. |
در Recycled-AltUp، به جای اینکه توکن های اولیه را گسترش دهیم، جاسازی ها را تکرار می کنیم. ک بارها برای تشکیل یک نمایش نمادین گسترده تر. از این رو، Recycled-AltUp عملاً هیچ پارامتر اضافی نسبت به ترانسفورماتور خط پایه اضافه نمی کند، در حالی که از یک نمایش توکن گسترده تر بهره می برد.
 |
| Recycled-AltUp در T5-B/L/XL در مقایسه با خطوط پایه. Recycled-AltUp منجر به بهبودهای شدید در عملکرد قبل از تمرین بدون کاهش سرعت محسوس می شود. |
ما همچنین پسوند سبک AltUp، Recycled-AltUp، را با ارزیابی می کنیم ک = 2 در مدل های پایه، بزرگ و XL T5 و دقت و سرعت از پیش آموزش دیده آن را با خطوط پایه مقایسه کنید. از آنجایی که Recycled-AltUp نیازی به بسط در بعد جدول جاسازی ندارد، مدلهای تقویتشده با آن تقریباً همان تعداد پارامترهای قابل آموزش را با مدلهای پایه دارند. ما دوباره بهبودهای ثابتی را در مقایسه با خطوط پایه متراکم مشاهده می کنیم.
چرا AltUp کار می کند؟
AltUp ظرفیت مدل را با اضافه کردن و افزایش می دهد به طور موثر اعمال نفوذ پارامترهای کمکی به جدول تعبیه، و حفظ نمایش ابعاد بالاتر در سراسر لایه ها. ما معتقدیم که یک عنصر کلیدی در این محاسبه در مکانیزم پیشبینی AltUp نهفته است که مجموعهای از بلوکهای مختلف را انجام میدهد. این ترکیب وزنی امکان ارسال پیام پیوسته به کل بردار را با وجود فعال کردن تنها بلوکهای فرعی آن در هر لایه، فراهم میکند. Recycled-AltUp، از سوی دیگر، هیچ پارامتر اضافی را به جاسازی توکن اضافه نمی کند. با این حال، همچنان مزایای شبیهسازی محاسبات در فضای نمایش ابعاد بالاتر را به همراه دارد، زیرا یک بردار نمایش ابعاد بالاتر هنگام حرکت از یک لایه ترانسفورماتور به لایه دیگر حفظ میشود. ما حدس می زنیم که این امر با افزایش جریان اطلاعات از طریق شبکه به آموزش کمک می کند. یک جهت تحقیقاتی جالب این است که بررسی کنیم که آیا مزایای Recycled-AltUp را می توان به طور کامل با پویایی آموزشی مطلوب تر توضیح داد.
سپاسگزاریها
ما از همکارانمان Cenk Baykal، Dylan Cutler، و Rina Panigrahy در Google Research، و Nikhil Ghosh در دانشگاه کالیفرنیا، برکلی (کار انجام شده در طول کارآموزی تحقیقاتی در Google) تشکر می کنیم.
1این به این دلیل است که لایههای پیشخور یک ترانسفورماتور معمولاً به صورت درجه دوم با ابعاد مدل مقیاسبندی میشوند. ↩
2این ضریب به ضریب گسترش مشخص شده توسط کاربر بستگی دارد، اما معمولاً 1 است، یعنی ما بعد جدول تعبیه را دو برابر می کنیم. ↩