حریم خصوصی دیفرانسیل (DP) رویکردی است که تجزیه و تحلیل داده ها و یادگیری ماشین (ML) را با تضمین ریاضی حریم خصوصی داده های کاربر امکان پذیر می کند. DP مقدار “هزینه حریم خصوصی” یک الگوریتم را تعیین می کند، به عنوان مثال، سطح تضمینی که توزیع خروجی الگوریتم برای یک مجموعه داده معین به طور قابل توجهی تغییر نخواهد کرد اگر داده های یک کاربر به آن اضافه شود یا از آن حذف شود. الگوریتم با دو پارامتر ε و δ مشخص می شود که مقادیر کوچکتر هر دو نشان دهنده “خصوصی تر” است. تنش طبیعی بین بودجه حریم خصوصی (ε, δ) و کاربرد الگوریتم وجود دارد: یک بودجه حفظ حریم خصوصی کوچکتر نیاز به خروجی بیشتر “پر سر و صدا” دارد که اغلب منجر به مطلوبیت کمتر می شود. بنابراین، یک هدف اساسی DP دستیابی به مطلوبیت هر چه بیشتر برای بودجه حریم خصوصی مطلوب است.
یکی از ویژگی های کلیدی DP که اغلب نقش اصلی را در درک هزینه های حفظ حریم خصوصی ایفا می کند، ویژگی است ترکیب بندی، که منعکس کننده هزینه خالص حریم خصوصی ترکیبی از الگوریتم های DP است که با هم به عنوان یک الگوریتم مشاهده می شوند. یک مثال قابل توجه الگوریتم شیب نزولی تصادفی خصوصی متفاوت (DP-SGD) است. این الگوریتم مدلهای ML را در چندین تکرار آموزش میدهد – که هر کدام به طور متفاوت خصوصی هستند – و بنابراین نیاز به استفاده از ویژگی ترکیب DP دارد. یک قضیه ترکیب پایه در DP می گوید که هزینه حریم خصوصی مجموعه ای از الگوریتم ها حداکثر مجموع هزینه حریم خصوصی هر کدام است. با این حال، در بسیاری از موارد، این میتواند یک برآورد بیش از حد ناخالص باشد، و چندین قضیه ترکیب بهبود یافته تخمین بهتری از هزینه حریم خصوصی ترکیب ارائه میدهند.
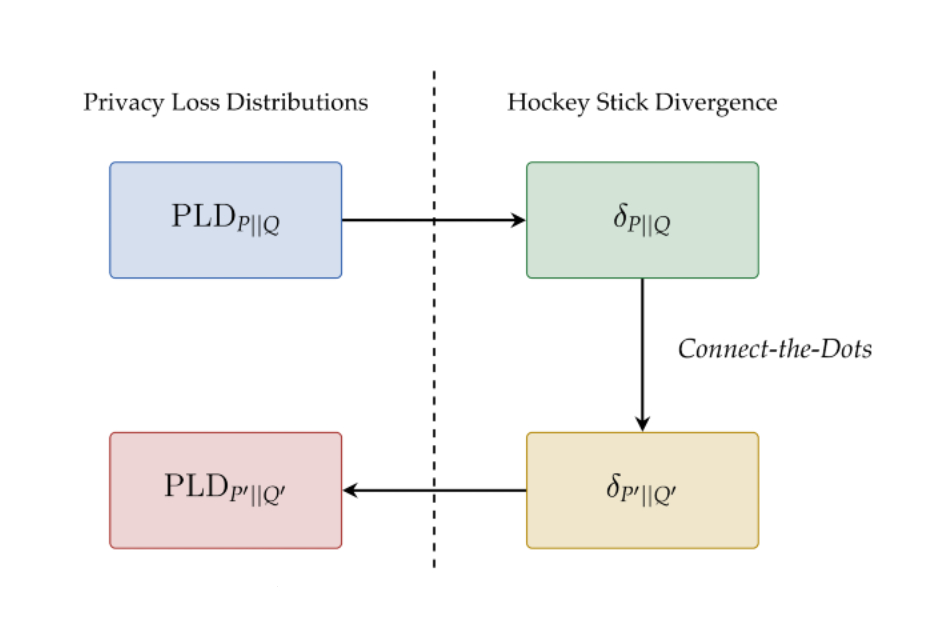
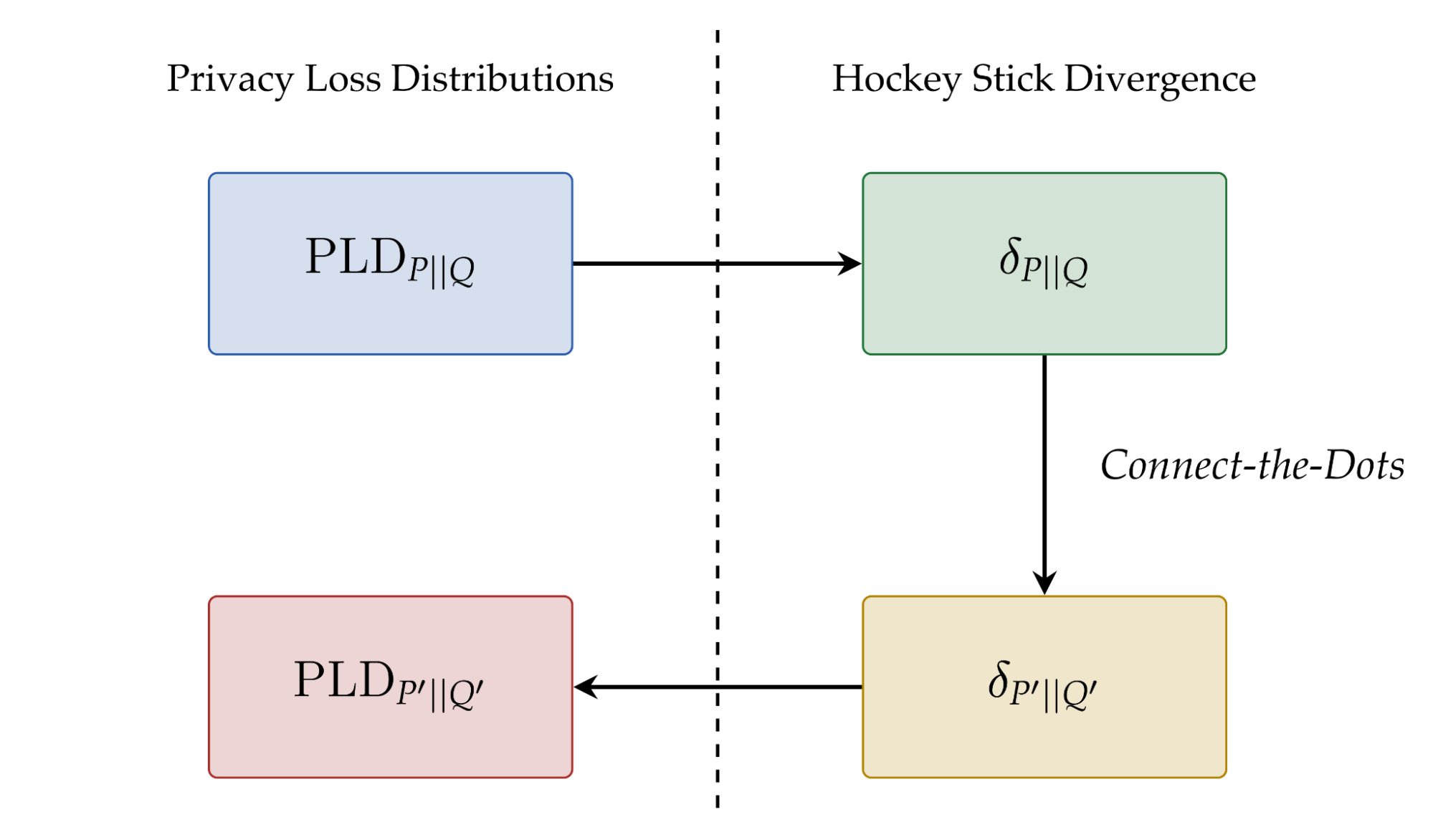
در سال 2019، یک کتابخانه منبع باز (در GitHub) منتشر کردیم تا توسعه دهندگان بتوانند از تکنیک های تحلیلی بر اساس DP استفاده کنند. امروز اضافه شدن به این کتابخانه را اعلام می کنیم نقاط را متصل کنید، یک الگوریتم حسابداری حریم خصوصی جدید بر اساس یک رویکرد جدید برای گسسته سازی توزیع های از دست دادن حریم خصوصی است که ابزار مفیدی برای درک هزینه حریم خصوصی ترکیب است. این الگوریتم مبتنی بر مقاله «اتصال نقاط: تقریبهای گسستهتر توزیعهای از دست دادن حریم خصوصی» است که در PETS 2022 ارائه شده است. تازگی اصلی این الگوریتم حسابداری این است که از یک رویکرد غیرمستقیم برای ایجاد گسستهسازی دقیقتر توزیعهای از دست دادن حریم خصوصی استفاده میکند. ما متوجه شدیم که Connect-the-Dots نسبت به سایر روشهای حسابداری حریم خصوصی در ادبیات، از نظر دقت و زمان اجرا، دستاوردهای قابلتوجهی دارد. این الگوریتم اخیراً برای حسابداری حریم خصوصی DP-SGD در آموزش مدلهای پیشبینی تبلیغات نیز استفاده شده است.
تفاوت حریم خصوصی و از دست دادن حریم خصوصی
گفته میشود که یک الگوریتم تصادفیشده تضمینهای DP را برآورده میکند اگر خروجی آن «به طور قابلتوجهی» به یک ورودی در مجموعه داده آموزشی آن وابسته نباشد، که به صورت ریاضی با پارامترهای (ε, δ) کمیسازی شود. به عنوان مثال، مثال انگیزشی DP-SGD را در نظر بگیرید. هنگامی که یک شبکه عصبی با SGD (غیر خصوصی) آموزش داده می شود، در اصل می تواند کل مجموعه داده آموزشی را در وزن خود رمزگذاری کند، در نتیجه به فرد اجازه می دهد تا برخی از نمونه های آموزشی را از یک مدل آموزش دیده بازسازی کند. از سوی دیگر، هنگامی که با DP-SGD آموزش می بینیم، ما تضمین رسمی داریم که اگر کسی بتواند یک نمونه آموزشی را با احتمال غیر پیش پا افتاده بازسازی کند، می تواند همان مثال را بازسازی کند، حتی اگر در آن گنجانده نشده باشد. مجموعه داده آموزشی
واگرایی چوب هاکی، با پارامتر ε، اندازه گیری فاصله بین دو توزیع احتمال است، همانطور که در شکل زیر نشان داده شده است. هزینه حریم خصوصی اکثر الگوریتم های DP توسط واگرایی چوب هاکی بین دو توزیع احتمال P و Q تعیین می شود. الگوریتم DP را با پارامترهای (ε, δ) برآورده می کند، اگر مقدار واگرایی چوب هاکی برای ε بین P و Q باشد. حداکثر δ. واگرایی چوب هاکی بین (P، Q)، نشان داده شده δپ||ق(ε) به نوبه خود کاملاً با توزیع از دست دادن حریم خصوصی مرتبط با آن مشخص می شود که با PLD نشان داده می شودپ||ق.
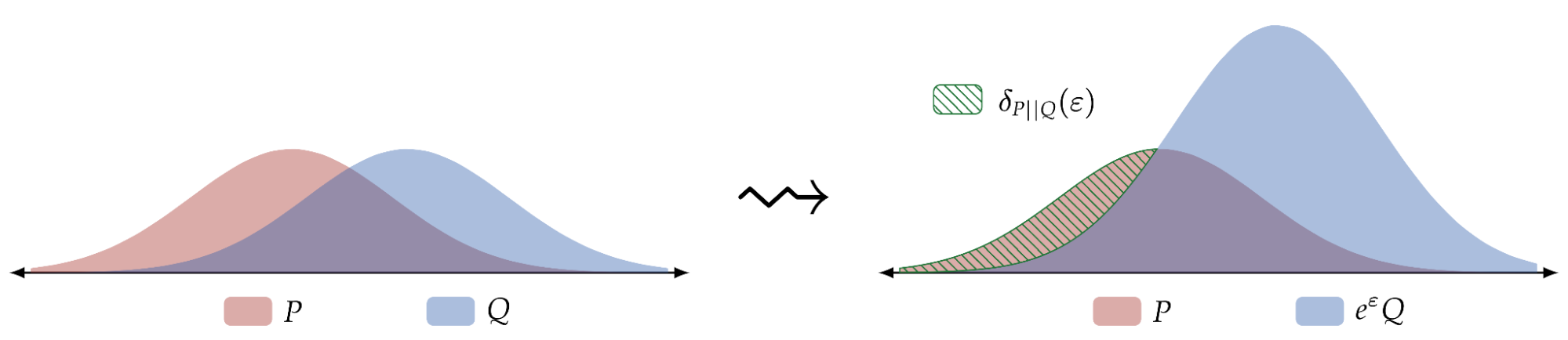 |
| تصویر واگرایی چوب هاکی δپ||ق(ε) بین توزیع های P و Q (ترک کرد) که مربوط به جرم احتمال P است که بالاتر از e استهس، جایی که eهQ یک e استه مقیاس بندی جرم احتمال Q (درست). |
مزیت اصلی برخورد با PLD ها این است که ترکیب الگوریتم ها با پیچیدگی PLD های مربوطه مطابقت دارد. با بهرهبرداری از این واقعیت، کار قبلی الگوریتمهای کارآمدی را برای محاسبه PLD مربوط به ترکیب الگوریتمهای منفرد با انجام کانولوشن هر PLD با استفاده از الگوریتم تبدیل فوریه سریع طراحی کرده است.
با این حال، یک چالش در هنگام برخورد با بسیاری از PLD ها این است که آنها اغلب توزیع های پیوسته هستند، که عملیات پیچیدگی را در عمل غیرقابل حل می کند. بنابراین، محققان اغلب رویکردهای گسسته سازی مختلف را برای تقریب PLD ها با استفاده از نقاط با فاصله یکسان اعمال می کنند. به عنوان مثال، نسخه اصلی الگوریتم سطل های حریم خصوصی، جرم احتمال فاصله بین دو نقطه گسسته را به طور کامل به انتهای بالاتر بازه اختصاص می دهد.
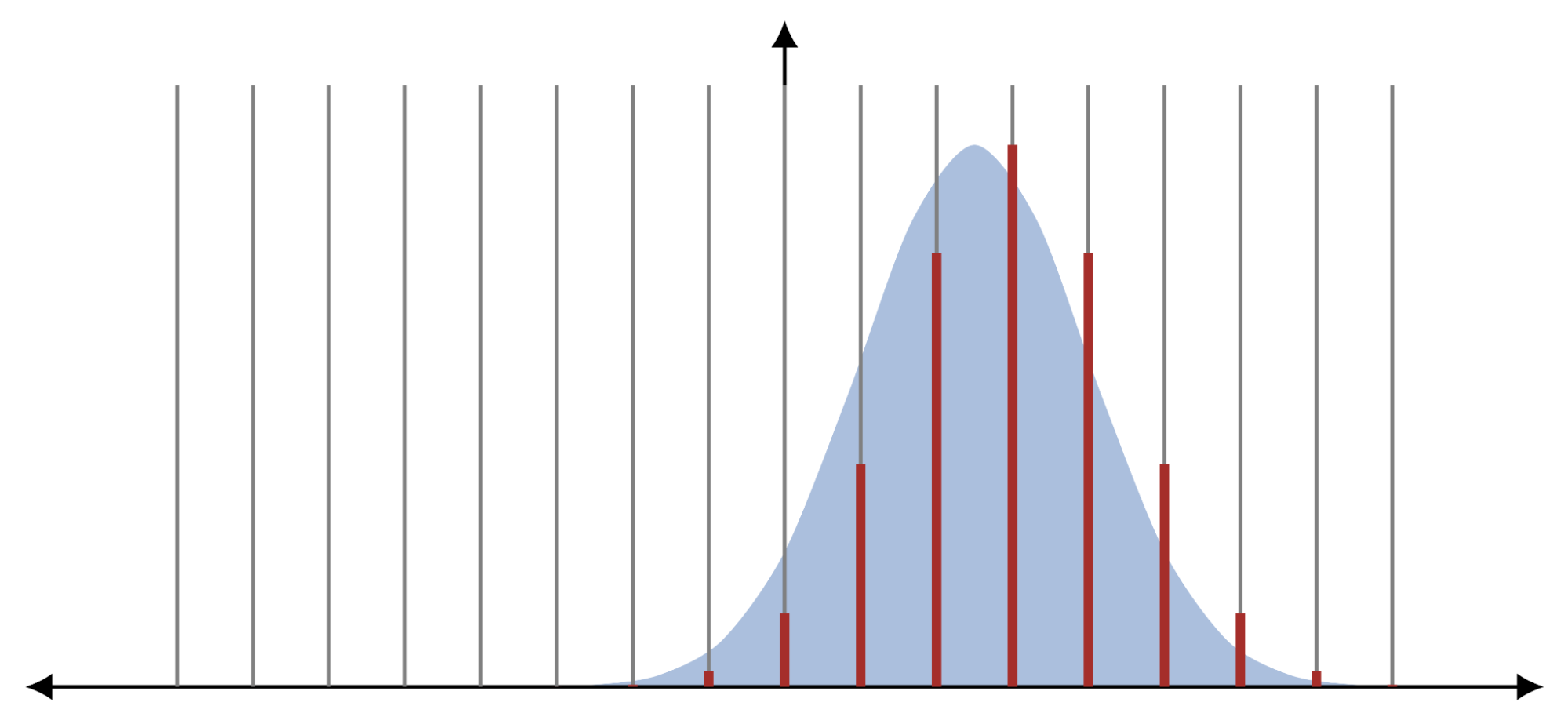 |
| تصویر گسسته سازی با گرد کردن توده های احتمال. در اینجا یک PLD پیوسته (به رنگ آبی) با گرد کردن جرم احتمال بین نقاط متوالی به یک PLD گسسته (قرمز) گسسته می شود. |
Connect-the-Dots: یک الگوریتم جدید
الگوریتم Connect-the-Dots جدید ما راه بهتری برای گسسته سازی PLD ها در راستای هدف تخمین واگرایی چوب هاکی ارائه می دهد. این رویکرد به طور غیرمستقیم با ابتدا گسسته کردن تابع واگرایی چوب هاکی و سپس نگاشت آن به یک PLD گسسته که در نقاط با فاصله مساوی پشتیبانی می شود، کار می کند.
 |
| تصویر مراحل سطح بالا در الگوریتم Connect-the-Dots. |
این رویکرد بر مفهوم “PLD غالب”، یعنی PLD تکیه داردP’||Q’ بر PLD تسلط داردپ||ق اگر واگرایی چوب هاکی اولی بیشتر یا مساوی با واگرایی چوب هاکی دومی برای همه مقادیر ε باشد. ویژگی کلیدی PLD های تسلط بر این است که پس از ترکیب بندی ها همچنان غالب باقی می مانند. بنابراین برای اهداف حسابداری حریم خصوصی، کار با یک PLD مسلط کافی است، که به ما یک حد بالایی در هزینه دقیق حریم خصوصی می دهد.
بینش اصلی ما در پشت الگوریتم Connect-the-Dots، توصیف یک PLD گسسته است، به این معنی که یک PLD بر روی مجموعه محدودی از مقادیر ε پشتیبانی میشود، اگر و تنها در صورتی که واگرایی چوب هاکی مربوطه به عنوان تابعی از e باشد.ه بین e متوالی خطی استه ارزش های. این به ما این امکان را می دهد که واگرایی چوب هاکی را به سادگی با اتصال نقطه ها برای بدست آوردن یک تابع خطی تکه تکه که دقیقاً برابر تابع واگرایی چوب هاکی در e داده شده است، گسسته کنیم.ه ارزش های. توضیحات بیشتر در مورد الگوریتم را ببینید.
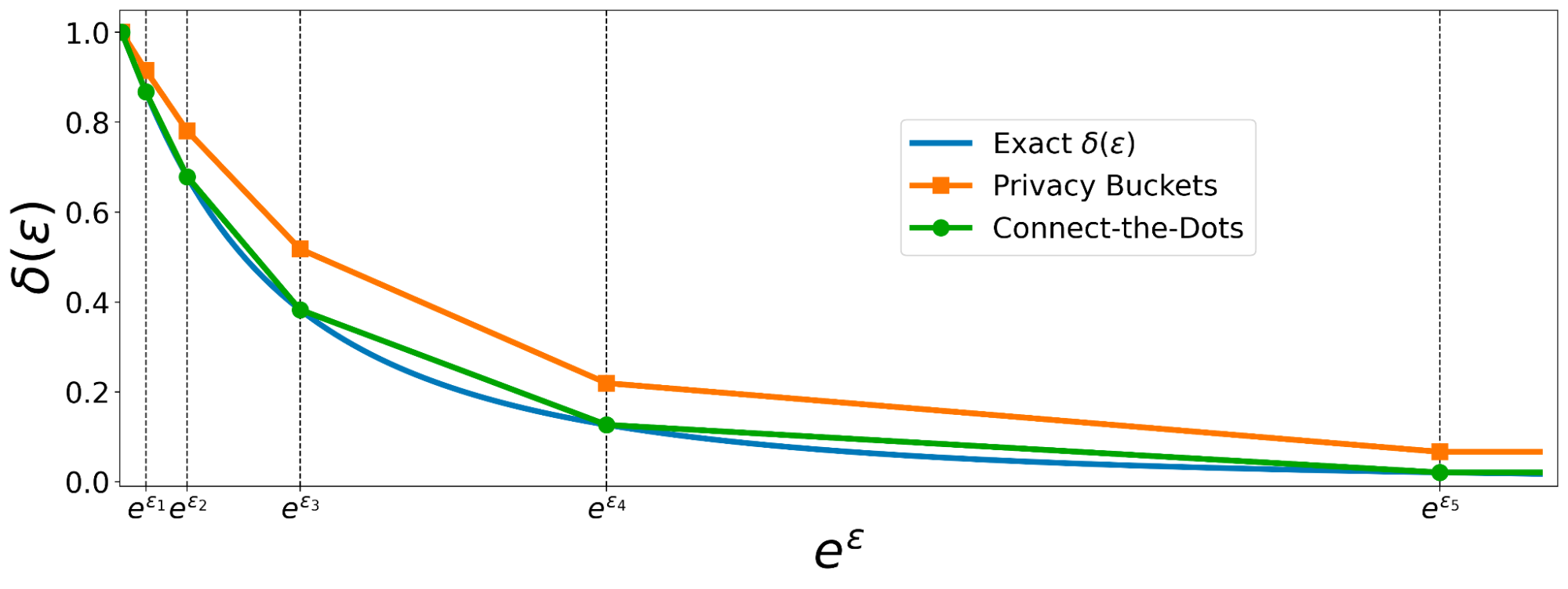 |
| مقایسه گسسته سازی واگرایی چوب هاکی توسط Connect-the-Dots در مقابل سطل های حریم خصوصی. |
ارزیابی تجربی
الگوریتم DP-SGD شامل یک ضرب کننده نویز پارامتر، که میزان نویز اضافه شده در هر مرحله گرادیان را کنترل می کند و a احتمال نمونه گیری، که تعداد نمونه های موجود در هر دسته کوچک را کنترل می کند. ما Connect-the-Dots را با الگوریتم های فهرست شده در زیر در مورد وظیفه حسابداری حریم خصوصی DP-SGD با ضریب نویز = 0.5، احتمال نمونه برداری = 0.2 x 10 مقایسه می کنیم.-4 و δ = 10-8.
مقدار ε محاسبهشده توسط هر یک از الگوریتمها را در برابر تعداد مراحل ترکیب رسم میکنیم، و علاوه بر این، زمان اجرای پیادهسازیها را رسم میکنیم. همانطور که در نمودارهای زیر نشان داده شده است، حسابداری حریم خصوصی با استفاده از Renyi DP تخمین ضعیفی از ضرر حریم خصوصی ارائه می دهد. با این حال، هنگام مقایسه رویکردهای با استفاده از PLD، متوجه میشویم که در این مثال، پیادهسازی Connect-the-Dots به برآورد دقیقتری از از دست دادن حریم خصوصی دست مییابد، با زمان اجرا که 5 برابر سریعتر از Microsoft PRV Accountant و بیش از 200 برابر سریعتر است. نسبت به رویکرد قبلی Privacy Buckets در کتابخانه Google-DP.
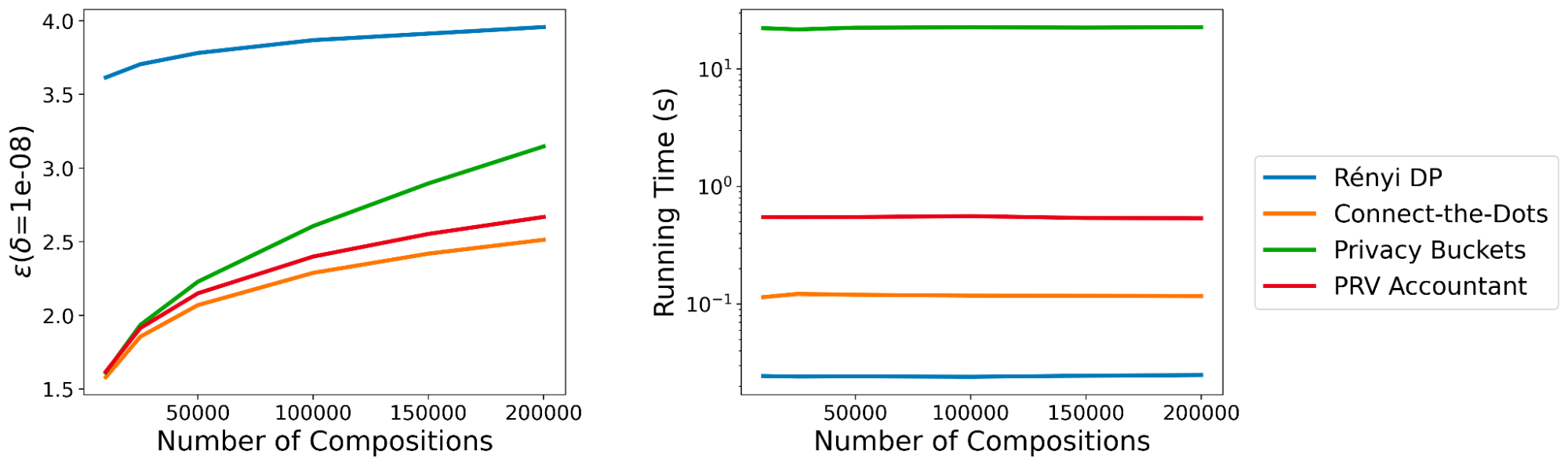 |
| ترک کرد: کران های بالایی در پارامتر حفظ حریم خصوصی ε برای تعداد مراحل مختلف DP-SGD، همانطور که توسط الگوریتم های مختلف برگردانده شده است (برای δ = 10 ثابت-8). درست: زمان اجرای الگوریتم های مختلف |
نتیجه گیری و مسیرهای آینده
این کار Connect-the-Dots را پیشنهاد میکند، یک الگوریتم جدید برای محاسبه پارامترهای حریم خصوصی بهینه برای ترکیببندیهای الگوریتمهای خصوصی متفاوت. هنگامی که بر روی کار DP-SGD ارزیابی میشود، متوجه میشویم که این الگوریتم تخمینهای دقیقتری در مورد از دست دادن حریم خصوصی با زمان اجرای قابلتوجهی سریعتر ارائه میدهد.
تا کنون، کتابخانه تنها از نسخه تخمین بدبینانه الگوریتم Connect-the-Dots پشتیبانی میکند، که یک حد بالایی برای از دست دادن حریم خصوصی الگوریتمهای DP ارائه میدهد. با این حال، این مقاله همچنین گونهای از الگوریتم را معرفی میکند که یک تخمین خوشبینانه از PLD را ارائه میکند که میتواند برای استخراج استفاده شود. مرزهای پایین تر در مورد هزینه حریم خصوصی الگوریتمهای DP (به شرطی که آنها «بدترین حالت» PLD را بپذیرند). در حال حاضر، کتابخانه از برآوردهای خوشبینانه که توسط الگوریتم Privacy Buckets ارائه شده است، پشتیبانی می کند، و ما امیدواریم که نسخه Connect-the-Dots را نیز به کار ببریم.
سپاسگزاریها
این کار با همکاری وادیم دوروشنکو، بدیه غازی، راوی کومار انجام شد. از گالن اندرو، استان باشتونکو، استیو چین، کریستوف دیباک، میگل گوارا، پیتر کایروز، ساشا کولانخینا، استفان ملم، جودی اسپیچک، یوری سوشکو و آندریاس ترزیس برای کمکشان تشکر میکنیم.