
مدلهای زبان (LMs) نیروی محرکه بسیاری از پیشرفتهای اخیر در پردازش زبان طبیعی هستند. مدل هایی مانند T5، LaMDA، GPT-3، و PalM عملکرد چشمگیری در کارهای مختلف زبانی از خود نشان داده اند. در حالی که عوامل متعددی میتوانند به بهبود عملکرد LMها کمک کنند، برخی از مطالعات اخیر نشان میدهند که افزایش اندازه مدل برای آشکار کردن قابلیتهای اضطراری بسیار مهم است. به عبارت دیگر، برخی از نمونه ها را می توان با مدل های کوچک حل کرد، در حالی که به نظر می رسد برخی دیگر از افزایش مقیاس سود می برند.
علیرغم تلاشهای اخیر که آموزش کارآمد LMها را بر روی مقادیر زیادی داده ممکن میسازد، مدلهای آموزشدیده هنوز میتوانند برای استفاده عملی کند و پرهزینه باشند. هنگام تولید متن در زمان استنتاج، اکثر LM های خودبازگشت محتوایی مشابه نحوه صحبت و نوشتن ما (کلمه به کلمه) تولید می کنند و هر کلمه جدید را بر اساس کلمات قبلی پیش بینی می کنند. این فرآیند را نمی توان موازی کرد زیرا LM ها باید پیش بینی یک کلمه را قبل از شروع به محاسبه کلمه بعدی کامل کنند. علاوه بر این، پیشبینی هر کلمه به محاسبات قابل توجهی با توجه به میلیاردها پارامتر مدل نیاز دارد.
در “مدل سازی زبان تطبیقی مطمئن”، ارائه شده در NeurIPS 2022، ما یک روش جدید برای تسریع تولید متن LM ها با بهبود کارایی در زمان استنتاج معرفی می کنیم. روش ما که CALM نام دارد، با این شهود ایجاد می شود که برخی از پیش بینی کلمات بعدی آسان تر از دیگران هستند. هنگام نوشتن یک جمله، برخی از ادامه ها بی اهمیت هستند، در حالی که برخی دیگر ممکن است به تلاش بیشتری نیاز داشته باشند. LM های کنونی به همان میزان توان محاسباتی را برای همه پیش بینی ها اختصاص می دهند. در عوض، CALM به صورت پویا تلاش محاسباتی را در طول مراحل تولید توزیع می کند. CALM با تخصیص انتخابی منابع محاسباتی بیشتر فقط به پیشبینیهای سختتر، متن را سریعتر تولید میکند و در عین حال کیفیت خروجی را حفظ میکند.
مدلسازی زبان تطبیقی مطمئن
در صورت امکان، CALM از برخی تلاشهای محاسباتی برای پیشبینیهای خاص صرفنظر میکند. برای نشان دادن این موضوع، از معماری محبوب رمزگذار-رمزگشا T5 استفاده می کنیم. رمزگذار متن ورودی را می خواند (مثلاً یک مقاله خبری برای خلاصه کردن) و متن را به نمایش های متراکم تبدیل می کند. سپس، رمزگشا با پیشبینی کلمه به کلمه، خلاصه را خروجی میدهد. هم رمزگذار و هم رمزگشا شامل یک توالی طولانی از لایه های ترانسفورماتور هستند. هر لایه شامل ماژولهای توجه و پیشخور با ضربهای ماتریس زیادی است. این لایه ها به تدریج نمایش پنهان را که در نهایت برای پیش بینی کلمه بعدی استفاده می شود، تغییر می دهند.
CALM به جای منتظر ماندن برای تکمیل همه لایههای رمزگشا، سعی میکند کلمه بعدی را زودتر، بعد از لایههای میانی پیشبینی کند. برای تصمیم گیری در مورد تعهد به یک پیش بینی خاص یا به تعویق انداختن پیش بینی به لایه بعدی، اطمینان مدل را در پیش بینی میانی آن اندازه گیری می کنیم. بقیه محاسبات تنها زمانی نادیده گرفته می شود که مدل به اندازه کافی مطمئن باشد که پیش بینی تغییر نخواهد کرد. برای تعیین کمیت آنچه که “به اندازه کافی مطمئن” است، آستانه ای را کالیبره می کنیم که از نظر آماری تضمین های کیفیت دلخواه را در تمام توالی خروجی برآورده می کند.
 |
| تولید متن با یک مدل زبان معمولی (بالا) و با آرامش (پایین). CALM تلاش می کند تا پیش بینی های اولیه را انجام دهد. هنگامی که به اندازه کافی اعتماد به نفس داشت (تن های آبی تیره تر)، جلوتر می رود و در زمان صرفه جویی می کند. |
مدل های زبان با خروجی های اولیه
فعال کردن این استراتژی خروج زودهنگام برای LMها نیازمند حداقل تغییرات در فرآیندهای آموزش و استنتاج است. در طول آموزش، ما مدل را تشویق میکنیم تا بازنماییهای معناداری را در لایههای میانی تولید کند. به جای پیشبینی فقط با استفاده از لایه بالایی، تابع کاهش یادگیری ما یک میانگین وزنی نسبت به پیشبینیهای همه لایهها است و وزن بیشتری را به لایههای بالایی اختصاص میدهد. آزمایشهای ما نشان میدهد که این به طور قابلتوجهی پیشبینیهای لایه میانی را در حالی که عملکرد کامل مدل را حفظ میکند، بهبود میبخشد. در یک مدل، ما یک مدل کوچک را نیز شامل میشویم طبقه بندی کننده خروج زود هنگام آموزش دیده تا طبقه بندی کند که آیا پیش بینی لایه میانی محلی با لایه بالایی مطابقت دارد یا خیر. ما این طبقه بندی کننده را در یک مرحله سریع دوم آموزش می دهیم و بقیه مدل را فریز می کنیم.
هنگامی که مدل آموزش داده شد، به روشی نیاز داریم که اجازه خروج زود هنگام را بدهد. ابتدا، ما یک معیار اطمینان محلی برای گرفتن اعتماد مدل در پیشبینی میانی آن تعریف میکنیم. ما سه معیار اطمینان را بررسی می کنیم (که در بخش نتایج زیر توضیح داده شده است): (1) پاسخ سافت مکس، با برداشتن حداکثر احتمال پیش بینی شده از توزیع softmax. (2) تبلیغ دولتی، فاصله کسینوس بین نمایش پنهان فعلی و لایه قبلی. و (3) طبقه بندی کننده خروج زود هنگام، خروجی طبقه بندی کننده ای که به طور خاص برای پیش بینی ثبات محلی آموزش داده شده است. ما پاسخ softmax را از نظر آماری قوی می دانیم در حالی که محاسبه آن ساده و سریع است. دو گزینه دیگر در عملیات ممیز شناور (FLOPS) سبک تر هستند.
چالش دیگر این است که توجه هر لایه به حالت های پنهان از کلمات قبلی بستگی دارد. اگر برای پیشبینی کلمات زودتر از آن خارج شویم، ممکن است این حالتهای پنهان وجود نداشته باشند. در عوض، ما به حالت پنهان آخرین لایه محاسبه شده برمی گردیم.
در نهایت، آستانه اطمینان محلی را برای خروج زودهنگام تنظیم کردیم. در بخش بعدی، فرآیند کنترل شده خود را برای یافتن مقادیر آستانه خوب شرح می دهیم. به عنوان اولین گام، ما این فضای جستجوی نامحدود را با ایجاد یک مشاهده مفید ساده می کنیم: اشتباهاتی که در ابتدای فرآیند تولید انجام می شوند مضرتر هستند زیرا می توانند بر روی همه خروجی های زیر تأثیر بگذارند. بنابراین، ما با یک آستانه بالاتر (محافظه کارانه) شروع می کنیم و به تدریج با گذشت زمان آن را کاهش می دهیم. ما از یک توان منفی با دمای تعریف شده توسط کاربر برای کنترل این نرخ واپاشی استفاده می کنیم. ما دریافتیم که این اجازه می دهد تا کنترل بهتری بر روی مبادله عملکرد-بازده (سرعت به دست آمده در هر سطح کیفیت) کنترل شود.
کنترل قابل اعتماد کیفیت مدل شتاب
تصمیمات خروج زودهنگام باید محلی باشد. آنها باید هنگام پیش بینی هر کلمه اتفاق بیفتند. اما در عمل، خروجی نهایی باید باشد در سطح جهانی سازگار است یا قابل مقایسه با مدل اصلی برای مثال، اگر مدل کامل اصلی «کنسرت فوقالعاده و طولانی بود» را ایجاد میکرد، میتوان با CALM ترتیب صفتها را تغییر داد و «کنسرت طولانی و فوقالعاده بود» را خروجی داد. با این حال، در سطح محلی، کلمه “شگفت انگیز” با “طولانی” جایگزین شد. بنابراین، این دو خروجی در سطح جهانی سازگار هستند، اما شامل برخی ناسازگاریهای محلی هستند. ما مبتنی بر چارچوب Learn then Test (LTT) هستیم تا تصمیمات مبتنی بر اعتماد محلی را به خروجیهای جهانی سازگار متصل کنیم.
 |
| در CALM، آستانههای اطمینان محلی در هر مرحله برای تصمیمهای خروج اولیه، از طریق کالیبراسیون LTT، از محدودیتهای سازگاری تعریفشده توسط کاربر بر روی متن خروجی کامل به دست میآیند. جعبه های قرمز نشان می دهد که CALM از بیشتر لایه های رمزگشا برای آن پیش بینی خاص استفاده می کند. جعبههای سبز نشان میدهند که CALM تنها با استفاده از چند لایه Transformer در زمان صرفهجویی میکند. جمله کامل در آخرین نمونه این پست نشان داده شده است. |
ابتدا، ما دو نوع محدودیت سازگاری را تعریف و فرموله میکنیم که از میان آنها میتوان انتخاب کرد:
- سازگاری متنی: ما فاصله متنی مورد انتظار بین خروجی های CALM و خروجی های مدل کامل را محدود کردیم. این به هیچ داده برچسبگذاری شده نیاز ندارد.
- ثبات ریسک: ما افزایش مورد انتظار در ضرر را که برای CALM در مقایسه با مدل کامل مجاز میدانیم، محدود کردیم. این به خروجی های مرجعی نیاز دارد که با آنها مقایسه شود.
برای هر یک از این محدودیتها، میتوانیم تلورانسی را که اجازه میدهیم تنظیم کنیم و آستانه اطمینان را برای اجازه خروج زودهنگام تنظیم کنیم، در حالی که به طور قابل اعتماد محدودیت تعریفشده خود را با احتمال بالا دلخواه برآورده کنیم.
CALM باعث صرفه جویی در زمان استنتاج می شود
ما آزمایشهایی را روی سه مجموعه داده نسل محبوب اجرا میکنیم: CNN/DM برای خلاصهسازی، WMT برای ترجمه ماشینی، و SQuAD برای پاسخگویی به سؤال. ما هر یک از سه معیار اطمینان (پاسخ softmax، انتشار حالت و طبقهبندی کننده خروج زود هنگام) را با استفاده از یک مدل رمزگذار-رمزگشا 8 لایه ارزیابی میکنیم. برای ارزیابی عملکرد سطح توالی جهانی، از امتیازات استاندارد Rouge-L، BLEU، و Token-F1 استفاده میکنیم که فاصلهها را با منابع نوشته شده توسط انسان اندازهگیری میکند. ما نشان میدهیم که میتوان عملکرد کامل مدل را در حالی که به طور متوسط فقط از یک سوم یا نیمی از لایهها استفاده میکند، حفظ کرد. CALM با توزیع پویا تلاش محاسباتی در طول مراحل پیشبینی به این امر دست مییابد.
به عنوان یک کران بالا تقریبی، ما همچنین پیشبینیها را با استفاده از یک معیار اطمینان محلی اوراکل محاسبه میکنیم، که خروج از اولین لایه را امکانپذیر میکند که به همان پیشبینی لایه بالا منجر میشود. در هر سه کار، اندازهگیری اوراکل میتواند عملکرد کامل مدل را با استفاده از تنها 1.5 لایه رمزگشا حفظ کند. برخلاف CALM، یک خط پایه ایستا از تعداد لایه های یکسانی برای همه پیش بینی ها استفاده می کند و برای حفظ عملکرد خود به 3 تا 7 لایه (بسته به مجموعه داده ها) نیاز دارد. این نشان می دهد که چرا تخصیص پویا تلاش محاسباتی مهم است. تنها بخش کوچکی از پیشبینیها به بیشتر پیچیدگی مدل نیاز دارند، در حالی که برای دیگران بسیار کمتر از این کافی است.
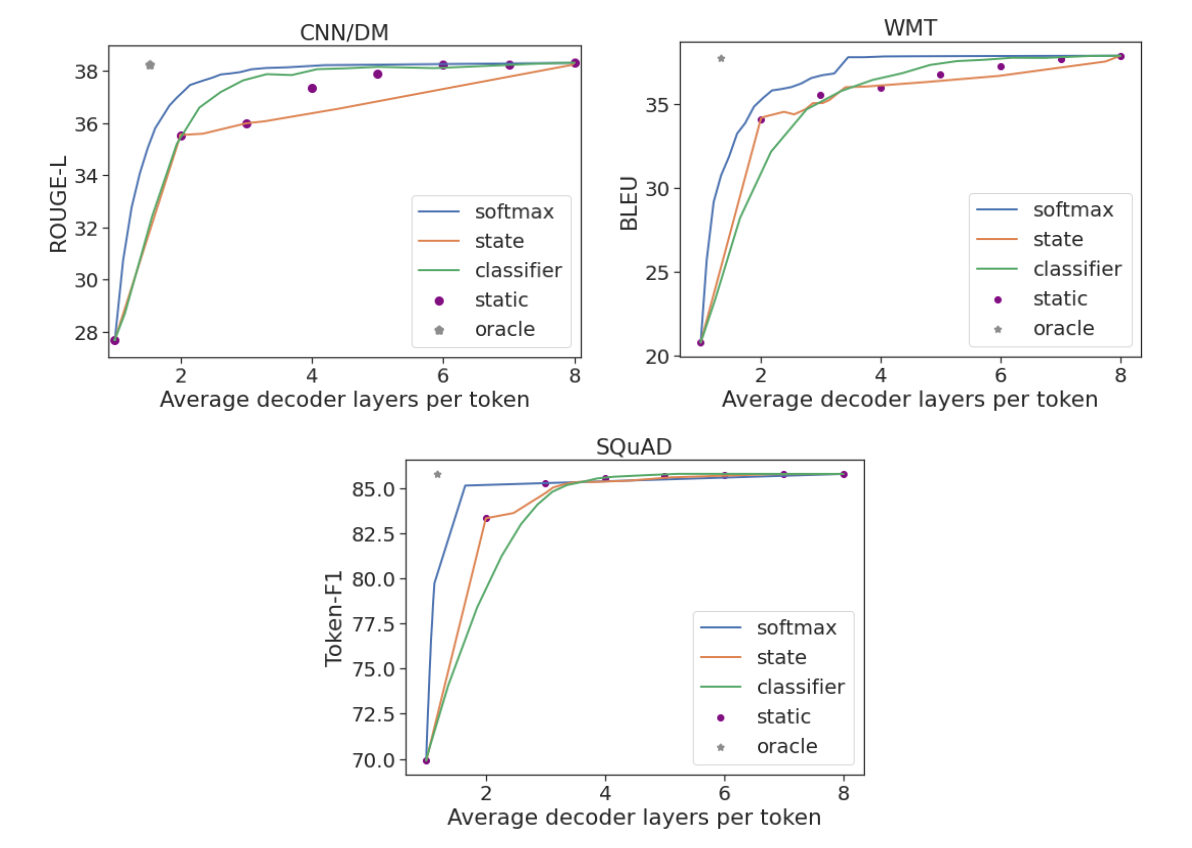 |
| عملکرد در هر کار در برابر میانگین تعداد لایههای رمزگشای استفاده شده. |
در نهایت، ما همچنین دریافتیم که CALM افزایش سرعت عملی را امکان پذیر می کند. هنگام محک زدن روی TPU ها، تقریباً نیمی از زمان محاسبه را صرفه جویی کردیم و در عین حال کیفیت خروجی ها را حفظ کردیم.
 |
| نمونه ای از خلاصه اخبار تولید شده سلول بالا خلاصه نوشته شده توسط انسان مرجع را ارائه می دهد. در زیر پیشبینی مدل کامل (8 لایه) و به دنبال آن دو نمونه خروجی CALM متفاوت است. خروجی CALM اول 2.9 برابر سریعتر و خروجی دوم 3.6 برابر سریعتر از مدل کامل است که بر روی TPUها محک زده شده است. |
نتیجه
CALM امکان تولید سریعتر متن با LMها را بدون کاهش کیفیت متن خروجی فراهم می کند. این امر با تغییر پویا مقدار محاسبه در هر مرحله زمانی حاصل میشود و به مدل اجازه میدهد تا در صورت اطمینان کافی از توالی محاسباتی خارج شود.
از آنجایی که اندازه مدل های زبان همچنان در حال رشد است، مطالعه نحوه استفاده کارآمد از آنها بسیار مهم می شود. CALM متعامد است و میتواند با بسیاری از تلاشهای مرتبط با کارایی، از جمله کوانتیزهسازی مدل، تقطیر، پراکندگی، تقسیمبندی مؤثر و جریانهای کنترل توزیعشده ترکیب شود.
سپاسگزاریها
کار در این زمینه با آدام فیش، یونل گوگ، سئونگیون کیم، جای گوپتا، مصطفی دهقانی، دارا بحری، وین کیو تران، یی تای و دونالد متزلر باعث افتخار و افتخار بود. ما همچنین از Anselm Levskaya، Hyung Won Chung، Tao Wang، Paul Barham، Michael Isard، Orhan Firat، Carlos Riquelme، Aditya Menon، Zhifeng Chen، Sanjiv Kumar و Jeff Dean برای بحث و بازخورد مفید تشکر می کنیم. در پایان از تام اسمال برای تهیه انیمیشن در این پست وبلاگ تشکر می کنیم.