
دسترسی به مجموعه دادهها برای بسیاری از تلاشهای امروزی در بخشهای عمودی و صنایع، اعم از تحقیقات علمی، تجزیه و تحلیل تجاری یا سیاستهای عمومی، حیاتی است. در جامعه علمی و در سطوح مختلف بخش عمومی، تکرارپذیری و شفافیت برای پیشرفت ضروری است، بنابراین اشتراک گذاری داده ها حیاتی است. به عنوان مثال، در ایالات متحده یک سیاست جدید اخیر مستلزم دسترسی آزاد و عادلانه به نتایج تمام تحقیقات با بودجه فدرال، از جمله داده ها و اطلاعات آماری همراه با انتشارات است.
برای تسهیل کشف محتوا با این سطح از جزئیات آماری و استخراج بهتر این اطلاعات از سراسر وب، Google اکنون جستجوی مجموعههای داده را آسانتر میکند. میتوانید روی هر یک از سه نتیجه برتر کلیک کنید (به زیر مراجعه کنید) تا به صفحه مجموعه دادهها برسید یا میتوانید با کلیک کردن روی «مجموعههای داده بیشتر» بیشتر کاوش کنید. به عنوان مثال:
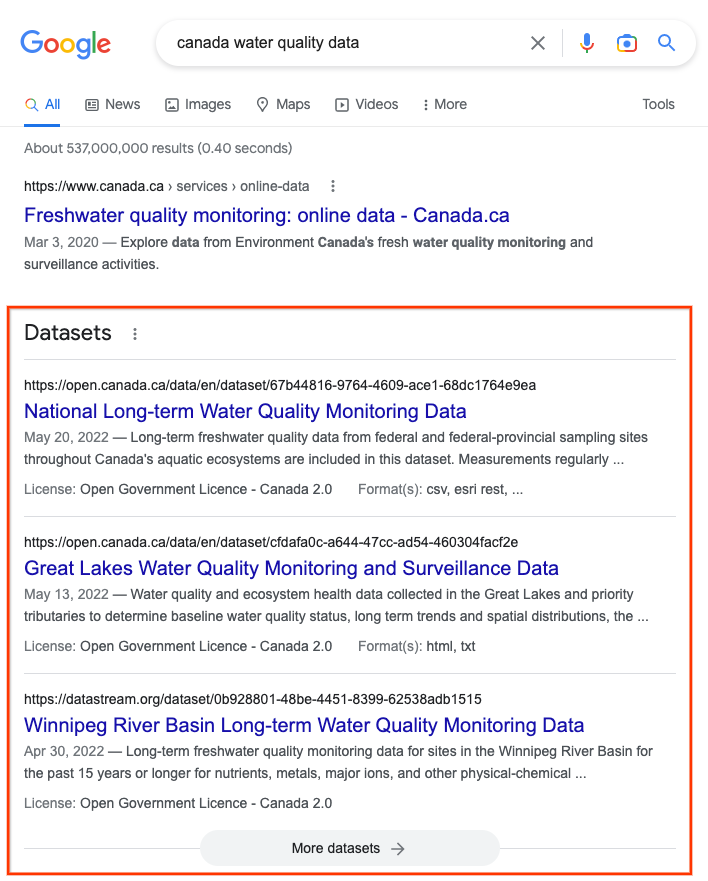 |
| وقتی کاربران در جستجوی Google مجموعه دادهها را جستجو میکنند، یک بخش اختصاصی پیدا میکنند که صفحاتی با توضیحات مجموعه داده را برجسته میکند. آنها میتوانند با کلیک بر روی «مجموعههای داده بیشتر» و رفتن به جستجوی مجموعه دادههای بسیار بیشتری را کاوش کنند. |
پشتیبانی شده توسط Dataset Search
Dataset Search، یک موتور جستجوی اختصاصی برای مجموعه داده ها، این ویژگی را تقویت می کند و بیش از 45 میلیون مجموعه داده از بیش از 13000 وب سایت را فهرست می کند. مجموعه داده ها بسیاری از رشته ها و موضوعات، از جمله مجموعه داده های دولتی، علمی و تجاری را پوشش می دهند. جستجوی مجموعه دادهها، ابردادههای ضروری درباره مجموعه دادهها و پیشنمایش دادهها را در صورت وجود به کاربران نشان میدهد. سپس کاربران می توانند پیوندهای مربوط به مخازن داده ای را که مجموعه داده ها را میزبانی می کنند دنبال کنند.
جستجوی مجموعه داده در درجه اول صفحات مجموعه داده در وب را که حاوی داده های ساختار یافته schema.org هستند فهرست می کند. ابرداده schema.org به نویسندگان صفحه وب اجازه می دهد تا معنای صفحه را توصیف کنند: موجودیت های موجود در صفحات و ویژگی های آنها. برای صفحات مجموعه داده، ابرداده schema.org عناصر کلیدی مجموعه دادهها را توصیف میکند، مانند توضیحات، مجوز، پوشش زمانی و مکانی، و قالبهای دانلود موجود. Dataset Search علاوه بر تجمیع این ابرداده و دسترسی آسان به آن، متادیتاهایی را که مستقیماً از صفحات وب میآیند، عادی و مطابقت میدهد.
اگر نویسنده یا ارائهدهنده مجموعه دادهها هستید و میخواهید دیگران مجموعه دادههای شما را در «جستجو» بیابند، مطمئن شوید که مجموعه دادههایتان را بهگونهای منتشر میکنید که قابل کشف باشد و مشخص کنید دیگران چگونه میتوانند از دادهها استفاده مجدد کنند. به طور خاص، اطمینان حاصل کنید که صفحه وب که مجموعه داده را توصیف می کند دارای ابرداده قابل خواندن توسط ماشین باشد. سادهترین راه برای اطمینان از این موضوع، انتشار مجموعه دادههای خود در یک مخزن مجموعه دادههای مستقر است. برخی از مخازن به جوامع تحقیقاتی خاصی پاسخ می دهند، در حالی که برخی دیگر «عمومی» هستند (figshare.com، zenodo.org، datadryad.org، kaggle.com، و غیره). این مخازن به طور خودکار متادیتا را در صفحات مجموعه داده برای هر مجموعه داده قرار می دهند، که این امر باعث می شود موتورهای جستجو به راحتی آن ها را کشف کرده و در بخش های نتایج تخصصی قرار دهند، مانند شکل بالا.
با ادامه رشد و تکامل اشتراک گذاری داده ها، ما همچنان به آسانی یافتن، دسترسی و استفاده از مجموعه داده ها را مانند هر نوع دیگر اطلاعات در وب می کنیم.
قدردانی ها
ما از بسیاری از کارمندان Google که در توسعه و راهاندازی این ویژگی مشارکت داشتند، بسیار سپاسگزاریم، از جمله: راشل زاکس، دامیان بیولو، شییو چن، جاناتان دریک، سونیل وموری، استفان تسو، آمیت باپات، ویل لسچوک، مارک نایورک، سرگئی واسیلویتسکی، برونو پوساس و کورینا کورتس.