حوزه پردازش زبان طبیعی (NLP) با مدلهای زبانی که بر روی مقادیر زیادی از دادههای متنی آموزش دیدهاند، متحول شده است. افزایش اندازه مدلهای زبان اغلب منجر به بهبود عملکرد و کارایی نمونه در طیف وسیعی از وظایف NLP پاییندستی میشود. در بسیاری از موارد، عملکرد یک مدل زبان بزرگ را می توان با برون یابی روند عملکرد مدل های کوچکتر پیش بینی کرد. به عنوان مثال، تأثیر مقیاس بر گیجی مدل زبان به طور تجربی نشان داده شده است که بیش از هفت مرتبه بزرگی را در بر می گیرد.
از سوی دیگر، عملکرد برای برخی وظایف دیگر به شکل قابل پیش بینی بهبود نمی یابد. به عنوان مثال مقاله GPT-3 نشان داد که توانایی مدلهای زبان برای انجام جمع چند رقمی دارای یک منحنی مقیاسبندی مسطح (عملکرد تقریباً تصادفی) برای مدلها از پارامترهای 100M تا 13B است که در آن نقطه عملکرد به طور قابلتوجهی افزایش یافت. با توجه به استفاده روزافزون از مدلهای زبانی در تحقیقات و کاربردهای NLP، درک بهتر تواناییهایی مانند اینها که میتوانند به طور غیرمنتظره ایجاد شوند، مهم است.
در «تواناییهای نوظهور مدلهای زبانی بزرگ» که اخیراً در نشریه منتشر شده است معاملات در تحقیقات یادگیری ماشینی (TMLR)، ما در مورد پدیده بحث می کنیم توانایی های نوظهور، که به عنوان توانایی هایی تعریف می کنیم که در مدل های کوچک وجود ندارد اما در مدل های بزرگتر وجود دارد. به طور خاص، ما ظهور را با تجزیه و تحلیل عملکرد مدلهای زبان به عنوان تابعی از مقیاس مدل زبان، که با کل عملیات ممیز شناور (FLOPs) اندازهگیری میشود، یا اینکه چقدر محاسبه برای آموزش مدل زبان استفاده شده است، مطالعه میکنیم. با این حال، ما ظهور را به عنوان تابعی از متغیرهای دیگر، مانند اندازه مجموعه داده یا تعداد پارامترهای مدل نیز بررسی می کنیم (برای جزئیات کامل به مقاله مراجعه کنید). به طور کلی، ما دهها نمونه از تواناییهای نوظهور را ارائه میدهیم که از بزرگتر کردن مدلهای زبان ناشی میشوند. وجود چنین توانایی های نوظهوری این سوال را مطرح می کند که آیا مقیاس بندی اضافی می تواند به طور بالقوه دامنه قابلیت های مدل های زبانی را بیشتر گسترش دهد.
وظایف اضطراری
ابتدا در مورد توانایی های اضطراری که ممکن است در کارهای برانگیخته به وجود بیایند بحث می کنیم. در چنین وظایفی، به یک مدل زبان از پیش آموزشدیده، دستوری برای کار به عنوان پیشبینی کلمه بعدی داده میشود و با تکمیل پاسخ، کار را انجام میدهد. بدون هیچ گونه تنظیم دقیق بیشتر، مدل های زبان اغلب می توانند کارهایی را انجام دهند که در طول آموزش دیده نمی شوند.
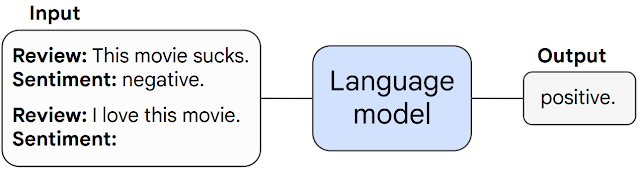 |
| نمونه ای از تحریک چند شات در طبقه بندی احساسات نقد فیلم. به مدل یک مثال از یک کار داده می شود (طبقه بندی یک نقد فیلم به عنوان مثبت یا منفی) و سپس کار را بر روی یک مثال نادیده انجام می دهد. |
زمانی که به طور غیرقابل پیشبینی از عملکرد تصادفی به بالاتر از حد تصادفی در یک آستانه مقیاس خاص افزایش مییابد، یک کار تحریکشده را اضطراری مینامیم. در زیر ما سه نمونه از وظایف با عملکرد اضطراری را نشان میدهیم: حساب چند مرحلهای، شرکت در آزمونهای سطح کالج، و شناسایی معنای مورد نظر یک کلمه. در هر مورد، مدلهای زبان عملکرد ضعیفی دارند و وابستگی بسیار کمی به اندازه مدل تا آستانهای دارند که در آن نقطه عملکرد آنها به طور ناگهانی شروع به برتری میکند.
 |
| توانایی انجام محاسبات چند مرحله ای (ترک کردموفقیت در امتحانات سطح کالج (وسط، و معنای مورد نظر یک کلمه را در متن مشخص کنید (درست) همه فقط برای مدل هایی با مقیاس به اندازه کافی بزرگ ظاهر می شوند. مدل های نشان داده شده شامل LaMDA، GPT-3، Gopher، Chinchilla و PaLM هستند. |
عملکرد در این وظایف فقط برای مدل هایی با مقیاس کافی غیر تصادفی می شود – به عنوان مثال، بالاتر از 1022 آموزش FLOP برای وظایف NLU حسابی و چند وظیفه ای و بالاتر از 1024 آموزش FLOP برای کلمه در وظایف زمینه. توجه داشته باشید که اگرچه مقیاسی که در آن ظهور رخ میدهد میتواند برای وظایف و مدلهای مختلف متفاوت باشد، هیچ مدلی بهبود آرامی را در رفتار در هیچ یک از این وظایف نشان نداد. دهها کار اضطراری دیگر در مقاله ما فهرست شدهاند.
راهبردهای اضطراری
دسته دوم توانایی های نوظهور را شامل می شود استراتژی های تحریک کننده که قابلیت های مدل های زبان را افزایش می دهد. راهبردهای انگیزشی پارادایم های گسترده ای برای تحریک هستند که می توانند برای طیف وسیعی از وظایف مختلف اعمال شوند. آنها زمانی که برای مدل های کوچک شکست می خورند، اضطراری در نظر گرفته می شوند و فقط می توانند توسط یک مدل به اندازه کافی بزرگ استفاده شوند.
یک مثال از یک استراتژی محرک اضطراری به نام “تحریک زنجیره ای از فکر“، که از مدل خواسته می شود قبل از دادن پاسخ نهایی، یک سری مراحل میانی تولید کند. تحریک زنجیرهای از فکر، مدلهای زبان را قادر میسازد تا کارهایی را که نیاز به استدلال پیچیده دارند، مانند یک مسئله چند مرحلهای کلمه ریاضی، انجام دهند. قابلتوجه است که مدلها توانایی انجام استدلال زنجیرهای از فکر را بدون آموزش صریح برای انجام این کار به دست میآورند. نمونه ای از تحریک زنجیره ای در شکل زیر نشان داده شده است.
 |
| تحریک زنجیرهای فکر، مدلهای به اندازه کافی بزرگ را قادر میسازد تا مسائل استدلال چند مرحلهای را حل کنند. |
نتایج تجربی تحریک زنجیرهای از فکر در زیر نشان داده شده است. برای مدلهای کوچکتر، بهکارگیری اعلان زنجیرهای از فکر عملکرد بهتری از اعلان استاندارد ندارد، بهعنوان مثال، زمانی که برای GSM8K، معیار چالشبرانگیز مسائل کلمات ریاضی اعمال میشود. با این حال، برای مدل های بزرگ (1024 FLOP)، پیشنهاد زنجیرهای فکری به طور قابلتوجهی عملکرد را در آزمایشهای ما بهبود میبخشد و به نرخ حل ۵۷% در GSM8K میرسد.
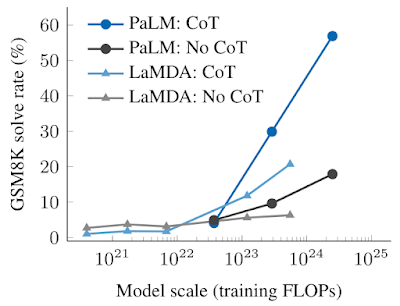 |
| تحریک زنجیرهای از فکر یک توانایی نوظهور است – نمیتواند عملکرد مدلهای زبان کوچک را بهبود بخشد، اما عملکرد را برای مدلهای بزرگ به طور قابلتوجهی بهبود میبخشد. در اینجا ما تفاوت بین اعلان استاندارد و زنجیرهای از فکر را در مقیاسهای مختلف برای دو مدل زبان، LaMDA و PalM نشان میدهیم. |
پیامدهای توانایی های اضطراری
وجود توانایی های نوظهور دارای طیف وسیعی از مفاهیم است. برای مثال، از آنجایی که تواناییها و استراتژیهای اضطراری چند شات به طور صریح در پیشآموزش کدگذاری نشدهاند، محققان ممکن است دامنه کامل تواناییهای چند شات را در مدلهای زبان فعلی ندانند. علاوه بر این، ظهور تواناییهای جدید بهعنوان تابعی از مقیاس مدل، این سؤال را مطرح میکند که آیا مقیاسبندی بیشتر بهطور بالقوه به مدلهای بزرگتر نیز تواناییهای نوظهور جدیدی را میبخشد.
شناسایی تواناییهای نوظهور در مدلهای زبان بزرگ اولین گام در درک چنین پدیدههایی و تأثیر بالقوه آنها بر قابلیتهای مدل آینده است. چرا مقیاس بندی توانایی های اضطراری را باز می کند؟ از آنجایی که منابع محاسباتی گران هستند، آیا می توان توانایی های نوظهور را از طریق روش های دیگر بدون افزایش مقیاس (مثلاً معماری های مدل بهتر یا تکنیک های آموزشی) باز کرد؟ آیا با ظهور تواناییهای خاص، برنامههای کاربردی جدید مدلهای زبان در دنیای واقعی باز میشوند؟ تجزیه و تحلیل و درک رفتارهای مدلهای زبانی، از جمله رفتارهای نوظهور که از مقیاسبندی ناشی میشوند، یک سؤال مهم تحقیقاتی است زیرا زمینه NLP همچنان در حال رشد است.
سپاسگزاریها
کار با ریشی بوماسانی، کالین رافل، بارت زوف، سباستین بورگو، دنی یوگاتاما، مارتن بوسما، دنی ژو، دونالد متزلر، اد اچ چی، تاتسونوری هاشیموتو، اوریول وینیالز، پرسی لیانگ، جف دین، افتخار و افتخار بود. و ویلیام فدوس