انتشار اولیه: 5 دسامبر 2022
آخرین به روز رسانی: 25 ژانویه 2023
به تازگی کنفرانس re:Invent شرکت که میزبان 50000 نفر از متخصصان برتر این صنعت بود، خدمات وب آمازون (AWS) در منطقه US-East 2 خود دچار اختلال شد. این قطعی دقیقاً 40 دقیقه از ساعت 12:26 بعد از ظهر تا 1:06 بعد از ظهر به وقت PST ادامه داشت و مشتریانی را که از VPN سایت به سایت و اتصال اینترنت AWS از طریق منطقه در دسترس بودن US-East 2 استفاده می کردند، تحت تأثیر قرار داد.
نمایندگان AWS از اظهار نظر در مورد علت قطعی امتناع کردند و به ما به بیانیه رسمی خود به صورت آنلاین اشاره کردند.
مسلماً US-East 2 تنها یک منطقه از مجموع 96 منطقه برای AWS است، اما همچنان بر آسیبپذیری اتصال از طریق ابر برای شرکتها تأکید میکند. اگر بزرگترین ارائهدهنده خدمات ابری جهان، حتی برای مدت کوتاهی از کار بیفتد، میلیونها مشتری و تعداد بیشتری از مشتریان آن مشتریان را تحت تأثیر قرار میدهد.
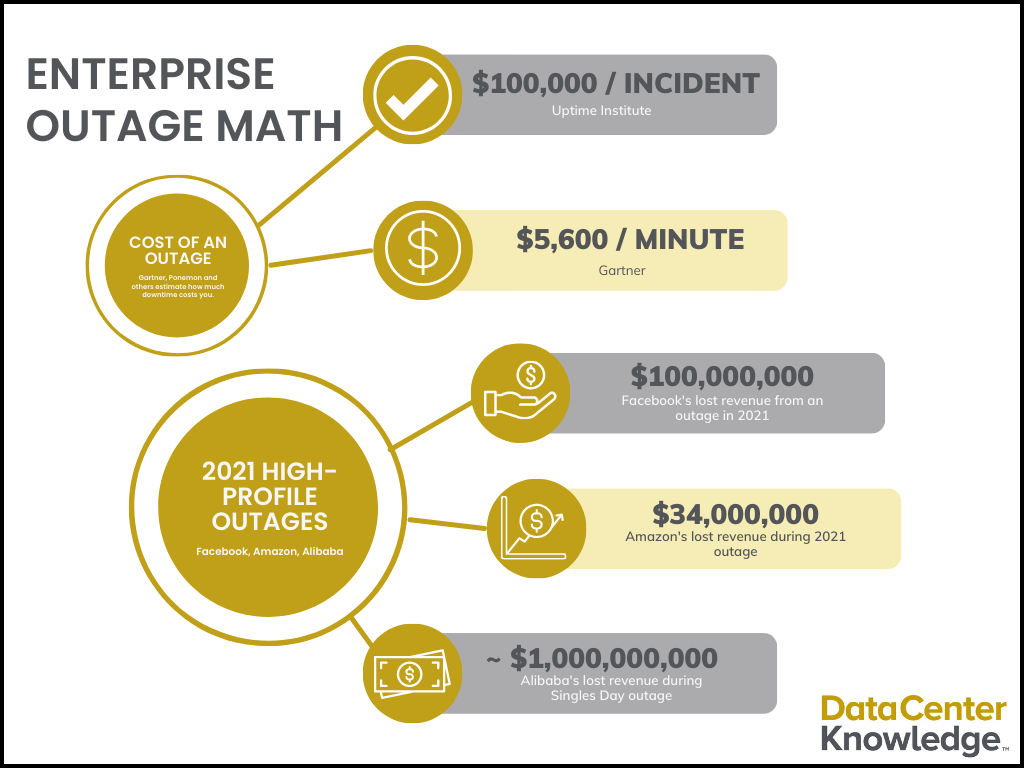
اثر ضربه ای می تواند به معنای تفاوت بین مبارزه یا بقا در این دوران ضعیف اقتصادی باشد.
چه چیزی باعث قطعی در منطقه در دسترس بودن US-East 2 AWS شد؟
تا زمان انتشار، AWS چیزی را که برخی «پس از مرگ» یا خلاصهای از قطعی پس از حادثه میخوانند، منتشر نکرده است. زمانی که از AWS پرسیده شد که چه زمانی یا اینکه آیا AWS یک پس از مرگ را ارائه می دهد، یکی از مقامات این شرکت این را گفت:
سخنگوی AWS در این باره نوشت: «ما خلاصههای پس از رویداد را برای هر رویداد سرویس منتشر نمیکنیم. دانش مرکز داده در پاسخ ایمیلی به درخواست ما در این هفته.
هنگامی که یک مشکل تأثیر گسترده و قابل توجهی بر مشتری دارد که منجر به شکست درصد قابل توجهی از تماسهای API هواپیمای کنترلی میشود، درصد قابلتوجهی از زیرساختها، منابع یا APIهای سرویس را تحت تأثیر قرار میدهد یا نتیجه قطعی کامل برق یا خرابی قابلتوجه شبکه است، AWS متعهد به ارائه یک خلاصه عمومی پس از رویداد (PES) پس از بسته شدن موضوع است.”
مشتریان AWS که کسبوکارشان به منطقه دسترسپذیری US-East-2 شرکت متکی است، سر خود را میخراشند و به این فکر میکنند که چگونه یک مشکل را بدون هیچ دلیل گزارش شده کاهش دهند.
آیا قطعی های دیگری در منطقه دسترسی AWS US-East 2 رخ داده است؟
آره. حادثه در 5 دسامبر دومین مورد در سال جاری در منطقه در دسترس بودن US-East-2 برای AWS است. در 28 جولای، حادثه قطعی گستردهتر بود و میتوان گفت که الزاماتی را که نماینده AWS به اشتراک گذاشته بود، برآورده میکرد.
به مدت 2.8 ساعت، مشتریان AWS به 38 سرویس ارائه دهنده خدمات ابری پیشرو در منطقه در دسترس بودن US-East-2 دسترسی نداشتند. این 38 سرویس عبارتند از: API Gateway، CloudWatch، DynamoDB، و پرچمدار شرکت ارائه دهنده Elastic Compute Cloud (که معمولاً به عنوان EC2 نامیده می شود).
EC2 به عنوان کاهش خدمات در داشبورد سلامت AWS در طول دوره زمانی حادثه “از دست دادن نیرو” فهرست شد.
در حال حاضر AWS هیچ خلاصه ای پس از حادثه منتشر نکرده است که علت و کاهش آن مشکل را نیز شرح دهد.
راه هایی که شرکت ها می توانند اثرات قطعی ابر را کاهش دهند چیست؟
این خبر منجر می شود دانش مرکز داده تعجب کنید که اگر نمونه AWS شما خراب بود، چگونه آن را مدیریت می کنید. در اینجا چند تکنیک کاهش زمان خرابی ابر را از مایکل گیبز، مدیر عامل شرکت Go Cloud Careers کشف کردهایم.
- یک ابر تنها یک نقطه شکست است. بارهای کاری را در سراسر ارائه دهندگان خدمات ابری (CSP) پخش کنید تا در طول قطعی متصل بمانید.
- تمرکز بر ارائه دهندگان با سیستم های غیر اختصاصی. این اجازه می دهد تا برای جابجایی کمتر دشواری از بار کاری بین CSP ها. گیبس پایگاه داده اختصاصی NoSQL DynamoDB AWS را مثال میزند. Bibbs میگوید یک گزینه بدون اصطکاک، یک پایگاه داده باز NoSQL مانند Apache Casandra یا MongoDB است. اینها را می توان در هر ابری به طور همزمان استفاده کرد.
- با وجود سر و صدای پیچیدگی CSP ها از چند ابر استفاده کنید. اجرای سیستمهای موازی روی دو سیستم ابری، زمان و سودآوری شرکت شما را تضمین میکند. قطع شدن در CSP های اصلی به قدری رایج شده است که نمی تواند بار کاری شما را از زمان خاموشی محافظت کند.
- در مورد خرابی های ابر و خود CSP ها برنامه ریزی کنید. گیبز میگوید در حالی که شرکتها معماری ابری را حول برندها طراحی نمیکنند، بلکه بیشتر برای حل چالشهای مشتری هستند، برای تداوم کسبوکار نمیتوان از در نظر گرفتن برندها اجتناب کرد.
- گیبز می گوید تداوم کسب و کار در C-suite باقی می ماند و تنها حوزه فناوری نیست. معماران بهتر است هنگام طراحی سیستم های ابری، هر تهدیدی را در نظر بگیرند و آن را کاهش دهند.
توصیه نهایی گیبز این است که بر درک خود ابر تمرکز کنید نه برندهای منفرد، چه بزرگ و چه کمتر شناخته شده. حفظ این طرز فکر به شرکتها اجازه میدهد تا در مذاکره و عقبنشینی در برابر افزایش قیمت و سایر تصمیمات CSPها که منافع شرکت را تامین نمیکنند، آزاد باشند.
این بینشها از مقاله «تکیه به دستور العمل ارائهدهنده ابری برای فاجعه» برای اولین بار در سایت AFCOM منتشر شده است.
AFCOM یک سازمان خواهر است دانش مرکز داده و در جهت سردبیری نشریه تاثیری ندارد.
[Update, Jan. 25, 2023]: اطلاعاتی در مورد دلیل قطع و نمودار هزینه های خرابی اضافه شد.