
یکی از ویژگیهای کلیدی هوش انسان این است که انسانها میتوانند با استفاده از چند مثال، انجام وظایف جدید را بیاموزند. مقیاسپذیری مدلهای زبان طیفی از برنامهها و پارادایمهای جدید را در یادگیری ماشین باز کرده است، از جمله توانایی انجام وظایف استدلالی چالش برانگیز از طریق یادگیری درون متنی. با این حال، مدلهای زبانی هنوز به روشی که اعلانها داده میشود حساس هستند، که نشان میدهد آنها به شیوهای قوی استدلال نمیکنند. برای مثال، مدلهای زبان اغلب به کارهای مهندسی سریع یا عبارتنویسی به عنوان دستورالعملها نیاز دارند، و رفتارهای غیرمنتظرهای مانند عملکرد بر روی وظایف تحت تأثیر قرار نمیگیرند، حتی زمانی که برچسبهای نادرست نشان داده میشوند.
در “تنظیم نمادها یادگیری درون متنی را در مدل های زبانی بهبود می بخشد”، ما یک روش تنظیم دقیق ساده را پیشنهاد می کنیم که به آن می گوییم. تنظیم نماد، که می تواند یادگیری درون متنی را با تأکید بر نگاشت ورودی-برچسب بهبود بخشد. ما با تنظیم نماد در مدلهای Flan-PaLM آزمایش میکنیم و مزایایی را در تنظیمات مختلف مشاهده میکنیم.
- تنظیم نمادها کارایی را در کارهای یادگیری درون زمینهای که دیده نمیشوند افزایش میدهد و در برابر دستورات نامشخص، مانند موارد بدون دستورالعمل یا بدون برچسب زبان طبیعی، بسیار قویتر است.
- مدلهای تنظیمشده با نماد در کارهای استدلال الگوریتمی بسیار قویتر هستند.
- در نهایت، مدلهای تنظیمشده با نماد، پیشرفتهای زیادی را در برچسبهای برگرداندهشدهای که در متن ارائه میشوند نشان میدهند، به این معنی که آنها توانایی بیشتری در استفاده از اطلاعات درون زمینهای برای نادیده گرفتن دانش قبلی دارند.
 |
| مروری بر تنظیم نمادها، که در آن مدلها در کارهایی که برچسبهای زبان طبیعی با نمادهای دلخواه جایگزین میشوند، بهخوبی تنظیم میشوند. تنظیم نماد بر این شهود متکی است که وقتی دستورالعمل و برچسبهای مربوطه در دسترس نیستند، مدلها باید از مثالهای درون متنی برای یادگیری کار استفاده کنند. |
انگیزه
تنظیم دستورالعمل یک روش تنظیم دقیق متداول است که نشان داده شده است عملکرد را بهبود میبخشد و به مدلها اجازه میدهد نمونههای درون زمینه را بهتر دنبال کنند. با این حال، یکی از کاستیها این است که مدلها مجبور نیستند استفاده از مثالها را بیاموزند، زیرا این کار بهطور اضافی در مثال ارزیابی از طریق دستورالعملها و برچسبهای زبان طبیعی تعریف شده است. به عنوان مثال، در سمت چپ در شکل بالا، اگرچه مثالها میتوانند به مدل کمک کنند تا تکلیف را درک کند (تحلیل احساسات)، اما آنها کاملاً ضروری نیستند زیرا مدل میتواند مثالها را نادیده بگیرد و فقط دستورالعملی را بخواند که نشان میدهد تکلیف چیست.
در تنظیم نماد، مدل بر روی نمونههایی که دستورالعملها حذف میشوند و برچسبهای زبان طبیعی با برچسبهای معنایی نامرتبط جایگزین میشوند (مثلاً “Foo”، “Bar”، و غیره) به خوبی تنظیم میشود. در این تنظیمات، کار بدون نگاه کردن به مثالهای درون متنی نامشخص است. به عنوان مثال، در سمت راست در شکل بالا، چندین مثال در زمینه برای تعیین تکلیف مورد نیاز است. از آنجایی که تنظیم نماد به مدل می آموزد که بر روی مثال های درون متنی استدلال کند، مدل های تنظیم شده با نماد باید عملکرد بهتری در کارهایی داشته باشند که نیاز به استدلال بین مثال های درون متنی و برچسب های آنها دارند.
 |
| مجموعه داده ها و انواع وظایف مورد استفاده برای تنظیم نمادها. |
روش تنظیم نماد
ما 22 مجموعه داده پردازش زبان طبیعی (NLP) در دسترس عموم را انتخاب کردیم که برای رویه تنظیم نماد خود استفاده میکنیم. این وظایف در گذشته به طور گسترده مورد استفاده قرار گرفتهاند، و ما فقط وظایف نوع طبقهبندی را انتخاب میکنیم زیرا روش ما به برچسبهای مجزا نیاز دارد. سپس برچسبها را به یک برچسب تصادفی از مجموعهای از 30 هزار برچسب دلخواه انتخابشده از یکی از سه دسته: اعداد صحیح، ترکیبهای کاراکتر و کلمات بازنگری میکنیم.
برای آزمایشهای خود، ما نماد لحن Flan-PaLM، گونههای تنظیمشده توسط دستورالعملهای PalM هستیم. ما از سه اندازه مختلف از مدل های Flan-PaLM استفاده می کنیم: Flan-PaLM-8B، Flan-PaLM-62B، و Flan-PaLM-540B. ما همچنین Flan-cont-PaLM-62B (Flan-PaLM-62B در توکن های 1.3T به جای توکن های 780B) را آزمایش کردیم که به اختصار آن را 62B-c می نویسیم.
 |
| ما از مجموعه ای از حدود 300 هزار نماد دلخواه از سه دسته (اعداد صحیح، ترکیب کاراکترها و کلمات) استفاده می کنیم. 30K نماد در طول تنظیم استفاده می شود و بقیه برای ارزیابی نگه داشته می شوند. |
راه اندازی آزمایشی
ما میخواهیم توانایی یک مدل را برای انجام کارهای دیده نشده ارزیابی کنیم، بنابراین نمیتوانیم کارهایی را که در تنظیم نمادها (22 مجموعه داده) استفاده میشوند یا در طول تنظیم دستورالعمل (1.8K وظایف) استفاده میشوند، ارزیابی کنیم. از این رو، ما 11 مجموعه داده NLP را انتخاب می کنیم که در طول تنظیم دقیق مورد استفاده قرار نگرفتند.
یادگیری درون متنی
در روش تنظیم نماد، مدلها باید یاد بگیرند که با مثالهای درون متنی استدلال کنند تا بتوانند وظایف را با موفقیت انجام دهند، زیرا درخواستها به گونهای اصلاح میشوند که اطمینان حاصل شود که وظایف نمیتوانند به سادگی از برچسبها یا دستورالعملهای مربوطه یاد بگیرند. مدلهای تنظیمشده با نماد باید در تنظیماتی که وظایف نامشخص هستند و نیاز به استدلال بین مثالهای درون متنی و برچسبهای آنها دارند، بهتر عمل کنند. برای بررسی این تنظیمات، ما چهار تنظیمات یادگیری درون متنی را تعریف میکنیم که میزان استدلال مورد نیاز بین ورودیها و برچسبها را برای یادگیری کار تغییر میدهد (بر اساس در دسترس بودن دستورالعملها/برچسبهای مربوطه)
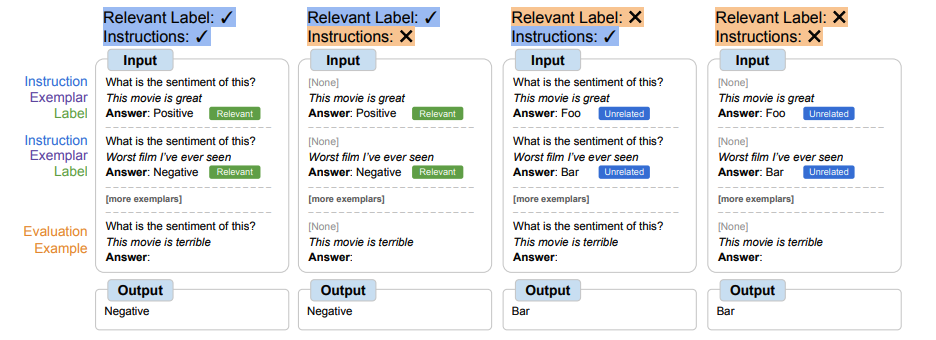 |
| بسته به در دسترس بودن دستورالعملها و برچسبهای زبان طبیعی مرتبط، مدلها ممکن است نیاز داشته باشند مقادیر مختلفی از استدلال را با مثالهای درون متنی انجام دهند. وقتی این ویژگیها در دسترس نیستند، مدلها باید با مثالهای درون زمینهای استدلال کنند تا کار را با موفقیت انجام دهند. |
تنظیم نمادها عملکرد را در تمام تنظیمات برای مدلهای 62B و بزرگتر، با بهبودهای جزئی در تنظیمات با برچسبهای زبان طبیعی مرتبط (+0.8% تا +4.2%) و بهبود قابل توجهی در تنظیمات بدون برچسبهای زبان طبیعی مرتبط (+5.5% تا +15.5%) بهبود میبخشد. ). به طور قابل توجهی، هنگامی که برچسب های مربوطه در دسترس نیستند، Flan-PaLM-8B تنظیم شده با نماد بهتر از FlanPaLM-62B عمل می کند، و Flan-PaLM-62B تنظیم شده با نماد عملکرد بهتری از Flan-PaLM-540B دارد. این تفاوت عملکرد نشان میدهد که تنظیم نماد میتواند به مدلهای بسیار کوچکتر و همچنین مدلهای بزرگ اجازه دهد تا در این وظایف عمل کنند (به طور مؤثر در محاسبه استنتاج 10X صرفهجویی میشود).
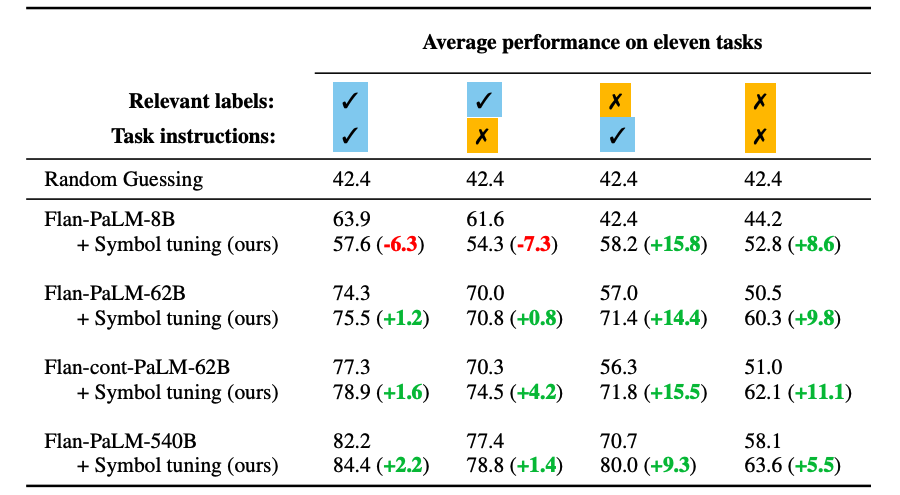 |
| مدلهای تنظیمشده به اندازه کافی بزرگ در یادگیری درون متنی بهتر از خطوط پایه هستند، بهویژه در تنظیماتی که برچسبهای مربوطه در دسترس نیستند. عملکرد به صورت میانگین دقت مدل (٪) در یازده کار نشان داده می شود. |
استدلال الگوریتمی
ما همچنین روی وظایف استدلال الگوریتمی از BIG-Bench آزمایش می کنیم. دو گروه اصلی از وظایف وجود دارد: 1) لیست توابع – شناسایی یک تابع تبدیل (به عنوان مثال، حذف آخرین عنصر در یک لیست) بین لیست های ورودی و خروجی حاوی اعداد صحیح غیر منفی. و 2) مفاهیم تورینگ ساده – با رشته های باینری استدلال کنید تا مفهومی را بیاموزید که یک ورودی را به یک خروجی نگاشت می کند (مثلاً تعویض 0 و 1 در یک رشته).
در تابع فهرست و وظایف مفهومی تورینگ ساده، تنظیم نماد به ترتیب به بهبود عملکرد متوسط 18.2% و 15.3% منجر میشود. علاوه بر این، Flan-cont-PaLM-62B با تنظیم نمادها به طور متوسط در وظایف لیست عملکرد بهتری از Flan-PaLM-540B دارد، که معادل کاهش 10 برابری در محاسبه استنتاج است. این پیشرفتها نشان میدهد که تنظیم نمادها توانایی مدل را برای یادگیری درون متنی برای انواع کارهای نادیده تقویت میکند، زیرا تنظیم نماد شامل هیچ داده الگوریتمی نمیشود.
 |
| مدلهای تنظیمشده با نماد، عملکرد بالاتری را در وظایف لیستی و وظایف مفهومی تورینگ ساده به دست میآورند. (A-E): دسته بندی وظایف توابع لیست. (F): کار مفاهیم تورینگ ساده. |
برچسب های برگردانده شده
در آزمایش برچسبهای برگردان، برچسبهای نمونههای درون بافتی و ارزیابی برگردانده میشوند، به این معنی که دانش قبلی و نگاشتهای برچسب ورودی با هم موافق نیستند (مثلا جملات حاوی احساسات مثبت با برچسب “احساس منفی”)، در نتیجه به ما امکان میدهد بررسی کنیم که آیا مدلها می تواند دانش قبلی را نادیده بگیرد. کار قبلی نشان داده است که در حالی که مدلهای از پیش آموزشدیده (بدون تنظیم دستورالعمل) تا حدی میتوانند از برچسبهای برگرداندهشده ارائه شده در متن پیروی کنند، تنظیم دستورالعمل این توانایی را کاهش داد.
ما می بینیم که روند مشابهی در همه اندازه های مدل وجود دارد – مدل های تنظیم شده با نماد بسیار بیشتر از مدل های تنظیم شده توسط دستورالعمل، از برچسب های برگردانده شده پیروی می کنند. ما متوجه شدیم که پس از تنظیم نماد، Flan-PaLM-8B بهبود متوسطی را در تمام مجموعه دادهها به میزان 26.5٪، Flan-PaLM-62B بهبود 33.7٪، و Flan-PaLM-540B بهبود 34.0٪ را مشاهده میکند. علاوه بر این، مدلهای تنظیمشده با نماد، عملکردی مشابه یا بهتر از میانگین را به عنوان مدلهای فقط قبل از آموزش به دست میآورند.
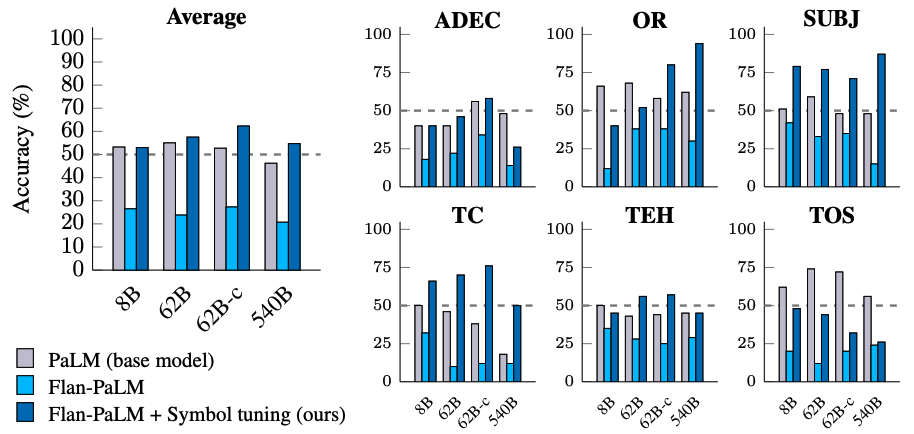 |
| مدلهای تنظیمشده با نماد در دنبال کردن برچسبهای برگرداندهشده ارائه شده در متن بسیار بهتر از مدلهای تنظیمشده با دستورالعمل هستند. |
نتیجه
ما تنظیم نماد را ارائه کردیم، روش جدیدی برای تنظیم مدلها در وظایفی که در آن برچسبهای زبان طبیعی به نمادهای دلخواه تغییر داده میشوند. تنظیم نماد بر اساس این شهود است که وقتی مدلها نمیتوانند از دستورالعملها یا برچسبهای مرتبط برای تعیین یک کار ارائهشده استفاده کنند، باید این کار را با یادگیری از مثالهای درون متنی انجام دهند. ما چهار مدل زبان را با استفاده از روش تنظیم نماد خود تنظیم کردیم، با استفاده از ترکیب تنظیمی از 22 مجموعه داده و تقریباً 30 هزار نماد دلخواه به عنوان برچسب.
ما ابتدا نشان دادیم که تنظیم نمادها عملکرد را در وظایف یادگیری درون متنی مشاهده نشده بهبود می بخشد، به خصوص زمانی که درخواست ها حاوی دستورالعمل ها یا برچسب های مرتبط نیستند. ما همچنین دریافتیم که مدلهای تنظیمشده با نماد در وظایف استدلال الگوریتمی بسیار بهتر بودند، علیرغم فقدان دادههای عددی یا الگوریتمی در روش تنظیم نماد. در نهایت، در یک تنظیمات یادگیری درون متنی که در آن ورودیها برچسبها را برگرداندهاند، تنظیم نماد (برای برخی از مجموعههای داده) توانایی دنبال کردن برچسبهای برگرداندهشده را که در طول تنظیم دستورالعمل از بین رفته بودند، بازیابی میکند.
کار آینده
از طریق تنظیم نماد، هدف ما افزایش درجه ای است که مدل ها می توانند در طول یادگیری درون متنی، نگاشتهای برچسب ورودی را بررسی کرده و از آنها یاد بگیرند. ما امیدواریم که نتایج ما تشویق به کار بیشتر در جهت بهبود توانایی مدلهای زبانی برای استدلال بر روی نمادهای ارائهشده در متن باشد.
سپاسگزاریها
نویسندگان این پست اکنون بخشی از Google DeepMind هستند. این کار توسط جری وی، لی هو، اندرو لامپینن، شیانگینگ چن، دا هوانگ، یی تای، شینیون چن، ییفنگ لو، دنی ژو، تنگیو ما و کوک وی. مایلیم از همکاران خود در Google Research و Google DeepMind برای مشاوره و بحث های مفیدشان تشکر کنیم.