مدل های زبان بزرگ (LLM) مانند PalM یا GPT-3 نشان دادند که مقیاس ترانسفورماتورها به صدها میلیارد پارامتر عملکرد را بهبود می بخشد و توانایی های نوظهور را باز می کند. با این حال، بزرگترین مدلهای متراکم برای درک تصویر، تنها به 4 میلیارد پارامتر رسیدهاند، علیرغم تحقیقاتی که نشان میدهد مدلهای چندوجهی امیدوارکننده مانند PaLI همچنان از مدلهای بینایی مقیاسبندی در کنار همتایان زبانی خود بهره میبرند. با انگیزه این موضوع و نتایج حاصل از مقیاسبندی LLM، تصمیم گرفتیم گام بعدی را در سفر مقیاسپذیری Vision Transformer انجام دهیم.
در “مقیاس سازی ترانسفورماتورهای بینایی به 22 میلیارد پارامتر”، ما بزرگترین مدل دید متراکم، ViT-22B را معرفی می کنیم. این 5.5 برابر بزرگتر از بزرگترین ستون بینایی قبلی، ViT-e است که دارای 4 میلیارد پارامتر است. برای فعال کردن این مقیاسبندی، ViT-22B ایدههایی را از مدلهای متنی مقیاسبندی مانند PaLM، با بهبود هم در پایداری تمرین (با استفاده از نرمالسازی QK) و هم در کارایی تمرین (با رویکرد جدیدی به نام عملیات خطی موازی ناهمزمان) ترکیب میکند. به عنوان یک نتیجه از معماری اصلاح شده، دستور اشتراک گذاری کارآمد و اجرای سفارشی، توانست بر روی Cloud TPU با استفاده از سخت افزار بالا آموزش ببیند.1. ViT-22B در بسیاری از وظایف بینایی با استفاده از نمایشهای منجمد یا با تنظیم دقیق کامل، وضعیت هنر را ارتقا میدهد. علاوه بر این، این مدل همچنین با موفقیت در PaLM-e مورد استفاده قرار گرفته است، که نشان داد یک مدل بزرگ ترکیبی از ViT-22B با یک مدل زبانی میتواند به طور قابل توجهی وضعیت هنر را در کارهای رباتیک ارتقا دهد.
معماری
کار ما بر اساس پیشرفت های بسیاری از LLM ها، مانند PalM و GPT-3 است. در مقایسه با معماری استاندارد Vision Transformer، ما از لایههای موازی استفاده میکنیم، رویکردی که در آن بلوکهای توجه و MLP بهجای متوالی مانند ترانسفورماتور استاندارد، به صورت موازی اجرا میشوند. این رویکرد در PalM استفاده شد و زمان تمرین را تا 15 درصد کاهش داد.
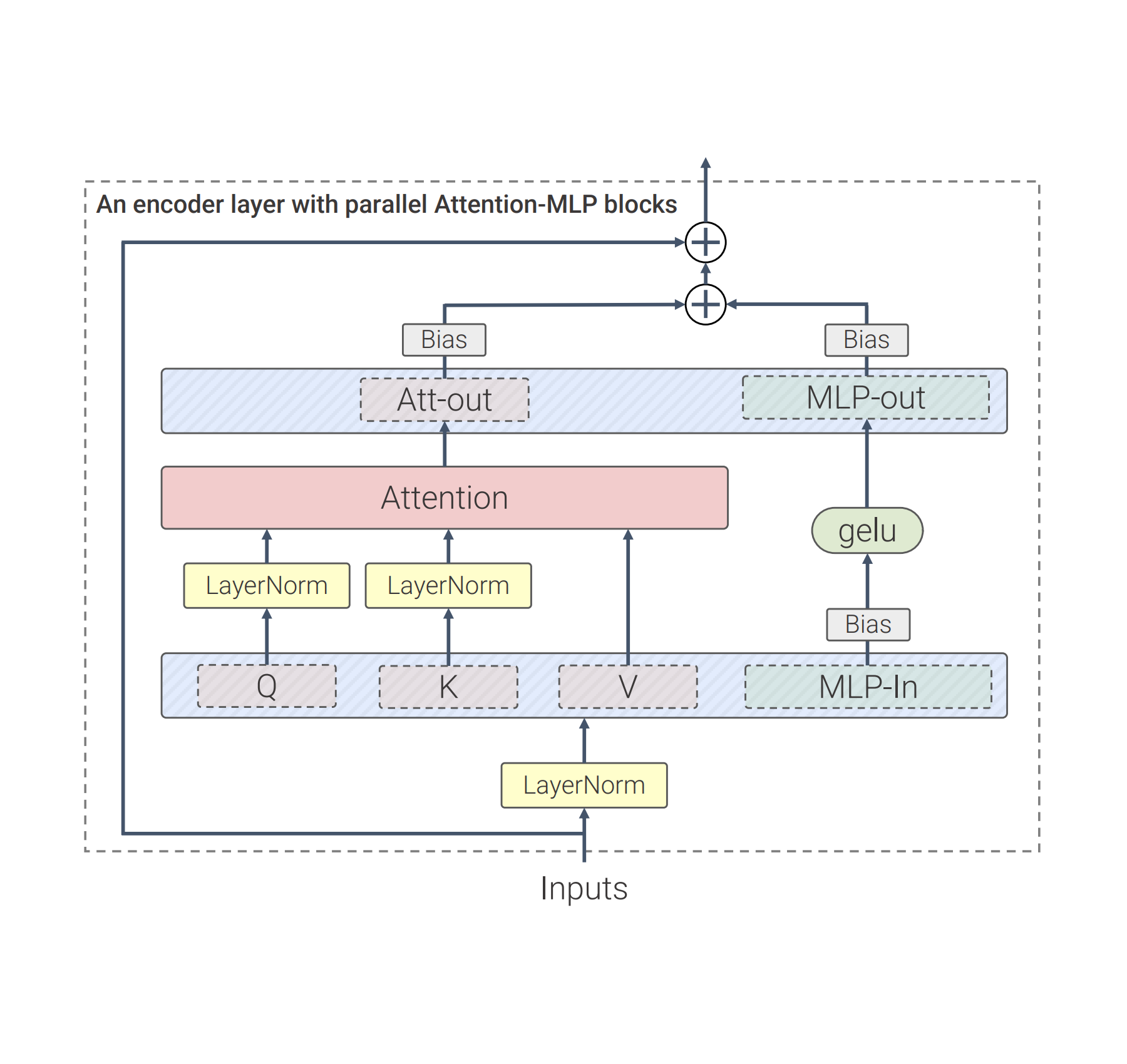
ثانیاً، ViT-22B سوگیریها را در پیشبینیهای QKV، بخشی از مکانیسم توجه به خود، و در LayerNorms حذف میکند، که استفاده را تا 3 درصد افزایش میدهد. نمودار زیر معماری ترانسفورماتور اصلاح شده مورد استفاده در ViT-22B را نشان می دهد:
 |
| معماری رمزگذار ترانسفورماتور ViT-22B از لایههای پیشخور موازی استفاده میکند، بایاسها را در لایههای QKV و LayerNorm حذف میکند و پیشبینیهای Query و Key را عادی میکند. |
مدلهای در این مقیاس به «شاردهسازی» نیاز دارند – توزیع پارامترهای مدل در دستگاههای محاسباتی مختلف. در کنار این، ما را نیز خرد می کنیم فعال سازی ها (نمایش های میانی یک ورودی). حتی چیزی به سادگی ضرب ماتریس نیاز به مراقبت بیشتری دارد، زیرا هم ورودی و هم خود ماتریس در بین دستگاهها توزیع میشوند. ما رویکردی به نام ایجاد می کنیم عملیات خطی موازی ناهمزمانبه موجب آن ارتباطات فعالسازیها و وزنها بین دستگاهها همزمان با محاسبات در واحد ضرب ماتریس (بخشی از TPU که اکثریت عظیمی از ظرفیت محاسباتی را در اختیار دارد) رخ میدهد. این رویکرد ناهمزمان زمان انتظار در ارتباطات ورودی را به حداقل میرساند و در نتیجه کارایی دستگاه را افزایش میدهد. انیمیشن زیر نمونه ای از محاسبات و الگوی ارتباطی برای ضرب ماتریس را نشان می دهد.
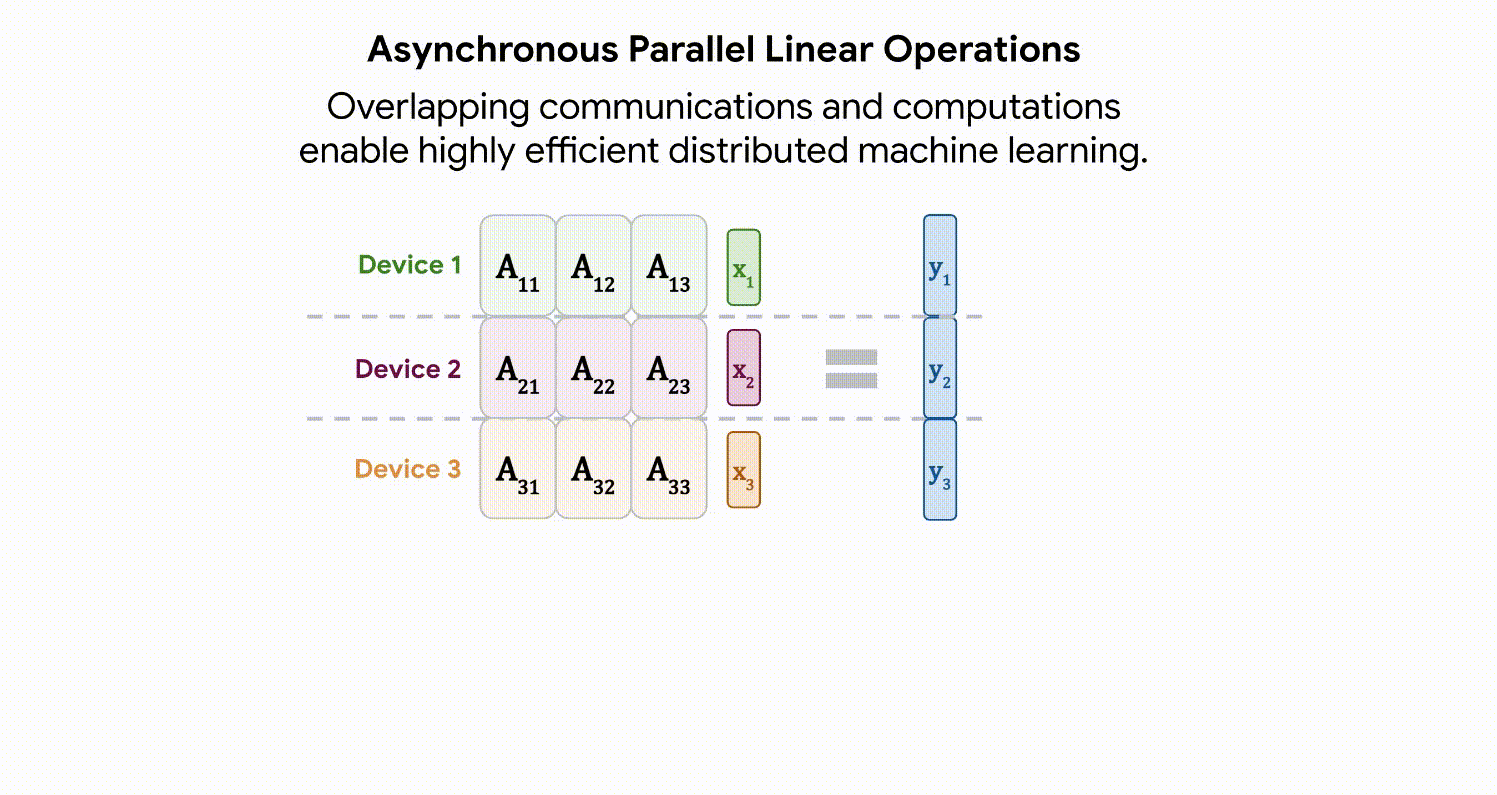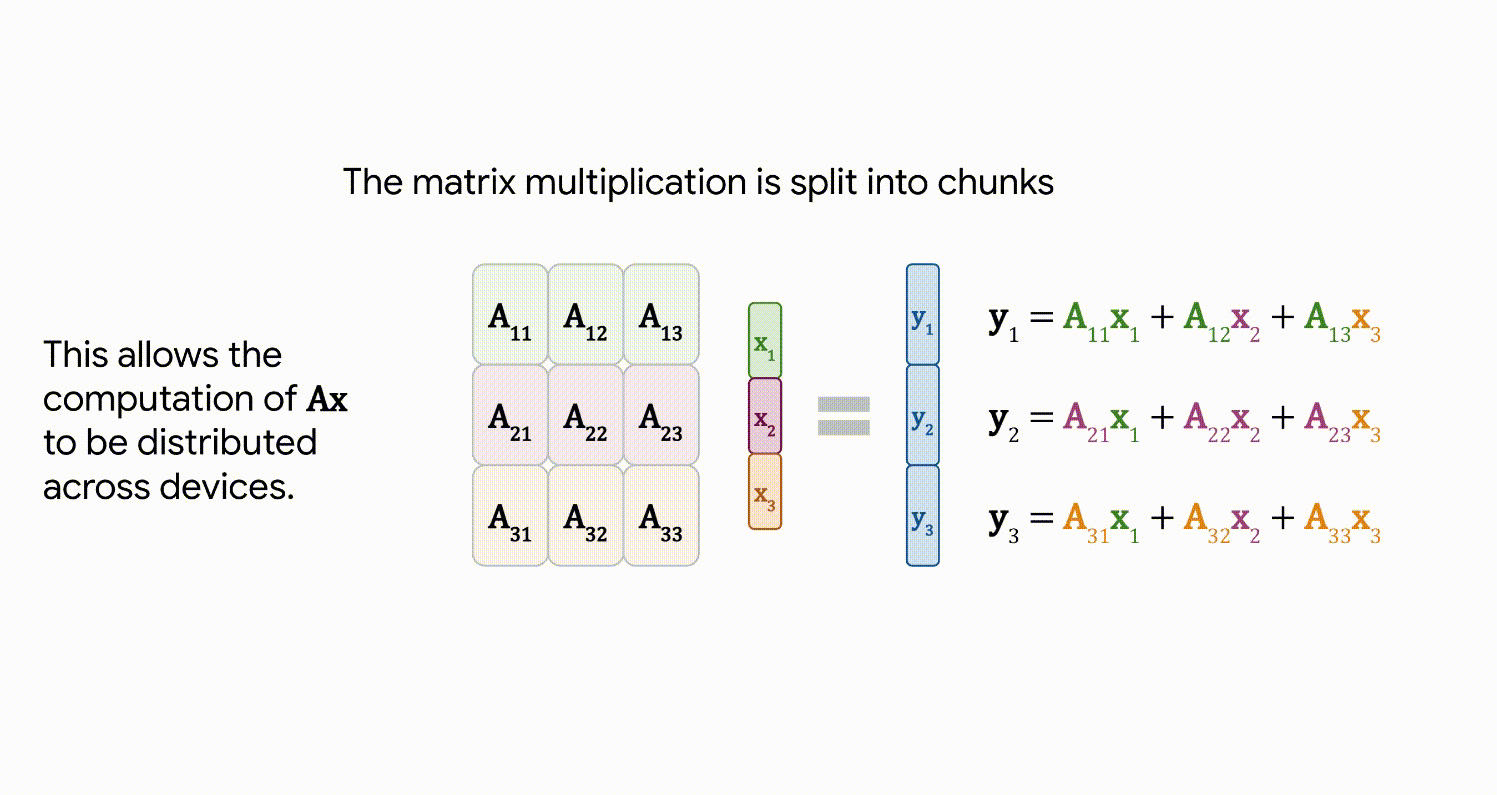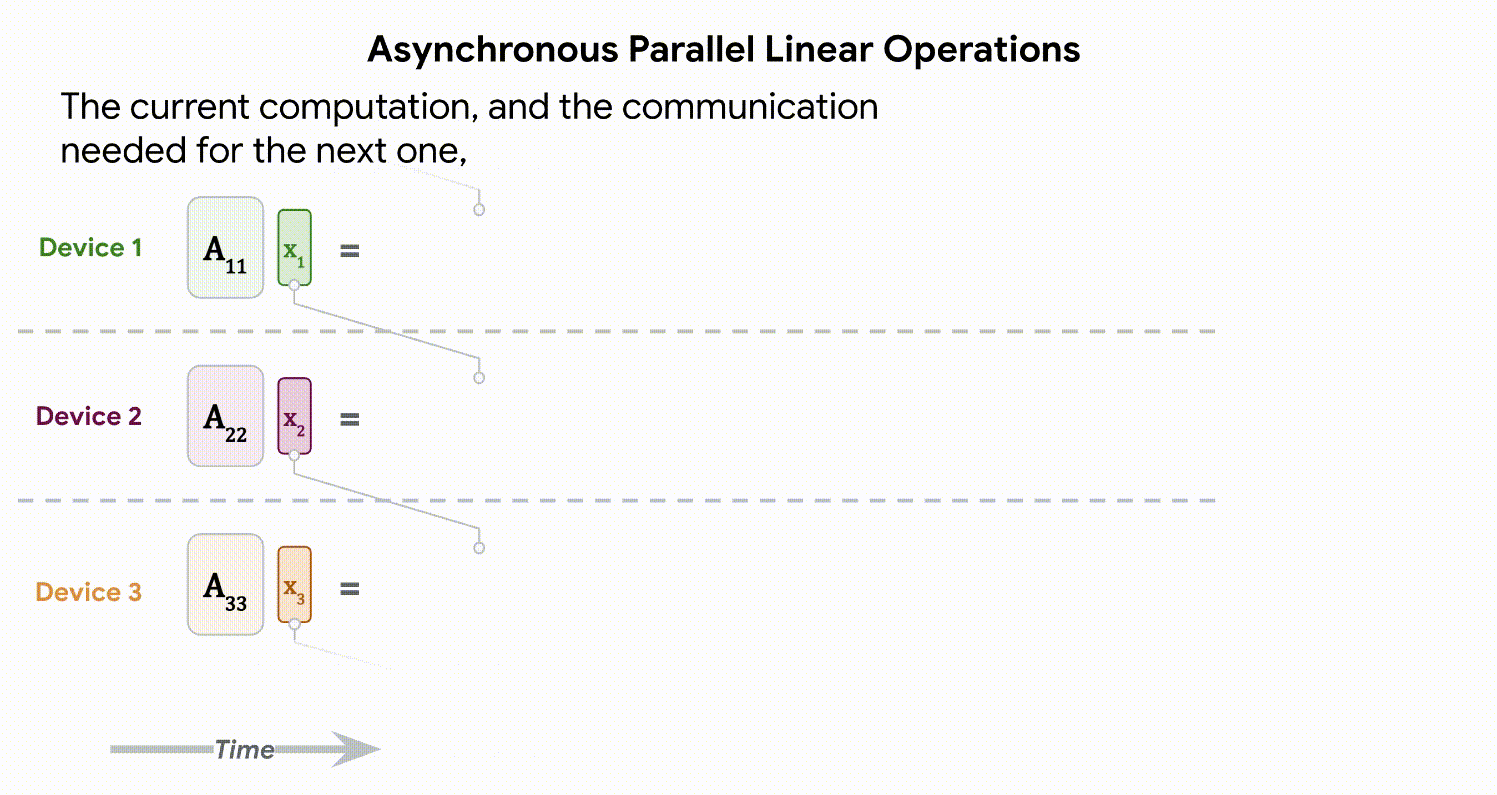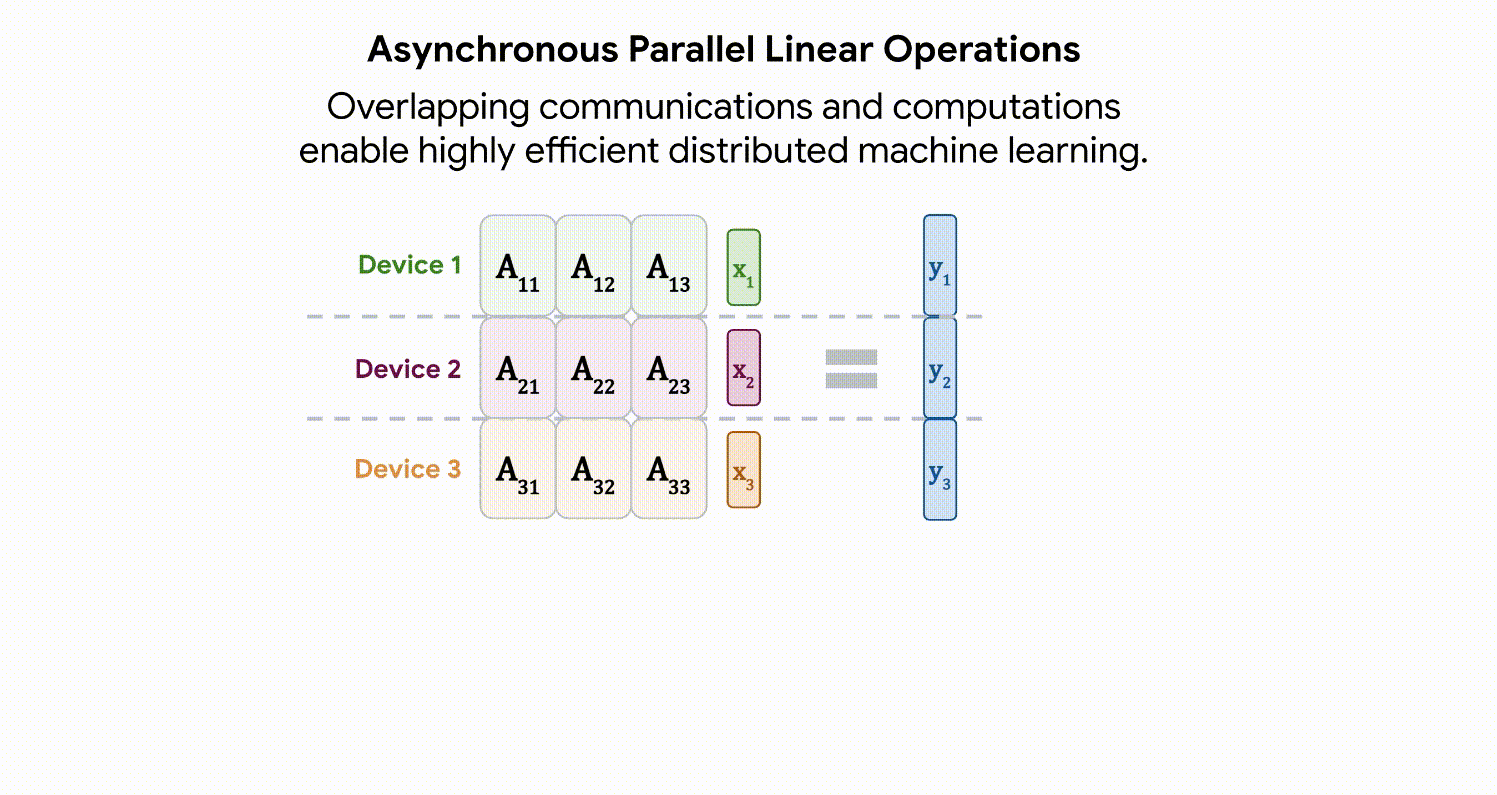 |
| عملیات خطی موازی ناهمگام هدف محاسبه ضرب ماتریس y = Ax است، اما هر دو ماتریس A و فعال سازی x در دستگاه های مختلف توزیع شده اند. در اینجا نشان میدهیم که چگونه میتوان آن را با ارتباطات و محاسبات همپوشانی بین دستگاهها انجام داد. ماتریس A در سراسر دستگاه ها به صورت ستونی تقسیم شده است، هر کدام یک برش پیوسته را در خود جای داده است، هر بلوک به صورت A نشان داده شده است.ij. جزئیات بیشتر در مقاله موجود است. |
در ابتدا، مقیاس مدل جدید منجر به بی ثباتی شدید آموزشی شد. رویکرد عادی سازی گیلمر و همکاران. (2023، آینده) این مسائل را حل کرد و امکان آموزش مدل صاف و پایدار را فراهم کرد. این با نمونه پیشرفت های آموزشی در زیر نشان داده شده است.
 |
| تأثیر عادی سازی پرس و جوها و کلیدها (نرمال سازی QK) در لایه خودتوجهی بر پویایی آموزش. بدون نرمالسازی QK (قرمز) گرادیانها ناپایدار میشوند و افت تمرینی واگرا میشوند. |
نتایج
در اینجا برخی از نتایج ViT-22B را برجسته می کنیم. توجه داشته باشید که در این مقاله چندین حوزه مشکل دیگر مانند طبقه بندی ویدئو، تخمین عمق و تقسیم بندی معنایی را نیز بررسی می کنیم.
برای نشان دادن غنای نمایش آموخته شده، ما یک مدل متن را آموزش می دهیم تا بازنمایی هایی تولید کند که نمایش های متن و تصویر را تراز می کند (با استفاده از تنظیم LiT). در زیر چندین نتیجه را برای تصاویر خارج از توزیع تولید شده توسط Parti و Imagen نشان می دهیم:
 |
| نمونه هایی از درک تصویر + متن برای ViT-22B همراه با یک مدل متنی. نمودار توزیع احتمال نرمال شده را برای هر توصیف یک تصویر نشان می دهد. |
تراز تشخیص اشیاء انسانی
برای اینکه بفهمیم چقدر تصمیمات طبقهبندی ViT-22B با تصمیمات طبقهبندی انسانی همسو هستند، ViT-22B را با دقت تنظیم شده با وضوحهای مختلف در مجموعه دادههای خارج از توزیع (OOD) ارزیابی کردیم که دادههای مقایسه انسانی برای آنها از طریق مدل-در مقابل- در دسترس است. جعبه ابزار انسان این جعبه ابزار سه معیار کلیدی را اندازهگیری میکند: مدلها چقدر با تحریفها (دقت) کنار میآیند؟ دقت انسان و مدل چقدر متفاوت است (تفاوت دقت)؟ در نهایت، الگوهای خطای انسان و مدل (ثبات خطا) چقدر شبیه هستند؟ در حالی که همه رزولوشن های تنظیم دقیق به یک اندازه خوب عمل نمی کنند، انواع ViT-22B برای هر سه معیار پیشرفته هستند. علاوه بر این، مدلهای ViT-22B همچنین دارای بالاترین سوگیری شکل ثبت شده در مدلهای بینایی هستند. این بدان معنی است که آنها بیشتر از شکل شی، به جای بافت شی، برای اطلاع رسانی تصمیمات طبقه بندی استفاده می کنند – یک استراتژی شناخته شده از درک انسان (که دارای سوگیری شکل 96٪ است). مدلهای استاندارد (مثلا ResNet-50، که دارای سوگیری شکل ~ 20-30٪ است) اغلب تصاویری مانند گربه با بافت فیل را بر اساس بافت (فیل) در زیر طبقهبندی میکنند. مدلهای با سوگیری شکل بالا تمایل دارند به جای آن روی شکل تمرکز کنند (گربه). در حالی که هنوز تفاوتهای مهم زیادی بین ادراک انسان و مدل وجود دارد، ViT-22B شباهتهای بیشتری را به تشخیص شی بصری انسان نشان میدهد.
 |
| گربه یا فیل؟ ماشین یا ساعت؟ پرنده یا دوچرخه؟ تصاویر نمونه با شکل یک شی و بافت یک شی متفاوت، که برای اندازه گیری سوگیری شکل/بافت استفاده می شود. |
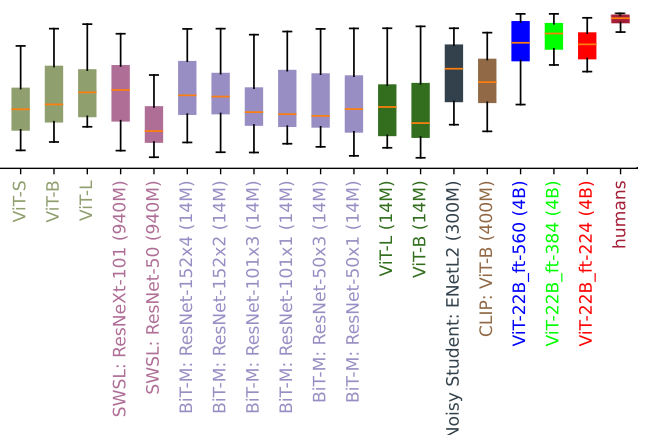 |
| ارزیابی سوگیری شکل (بالاتر = بیشتر با سوگیری شکل). بسیاری از مدلهای بینایی دارای سوگیری شکل کم / بافت بالا هستند، در حالی که ViT-22B تنظیم دقیق در ImageNet (قرمز، سبز، آبی که روی تصاویر 4B آموزش داده میشود، همانطور که با براکتهای بعد از نام مدل نشان داده میشود، مگر اینکه فقط در ImageNet آموزش داده شده باشند) دارای بیشترین تعصب شکل هستند. تا به امروز در یک مدل ML ثبت شده است، و آنها را به یک سوگیری شکل انسان مانند نزدیک می کند. |
عملکرد خارج از توزیع
اندازه گیری عملکرد در مجموعه داده های OOD به ارزیابی تعمیم کمک می کند. در این آزمایش، ما نقشههای برچسب (نگاشت برچسبها بین مجموعههای داده) را از JFT به ImageNet و همچنین از ImageNet به مجموعهدادههای مختلف خارج از توزیع مانند ObjectNet میسازیم (نتایج پس از آموزش قبلی روی این دادهها در منحنی سمت چپ نشان داده شده است). سپس مدل ها به طور کامل در ImageNet تنظیم می شوند.
مشاهده میکنیم که مقیاسبندی Vision Transformers عملکرد OOD را افزایش میدهد: حتی اگر دقت ImageNet اشباع شود، ما شاهد افزایش قابلتوجهی در ObjectNet از ViT-e به ViT-22B هستیم (که با سه نقطه نارنجی در سمت راست بالا نشان داده شده است).
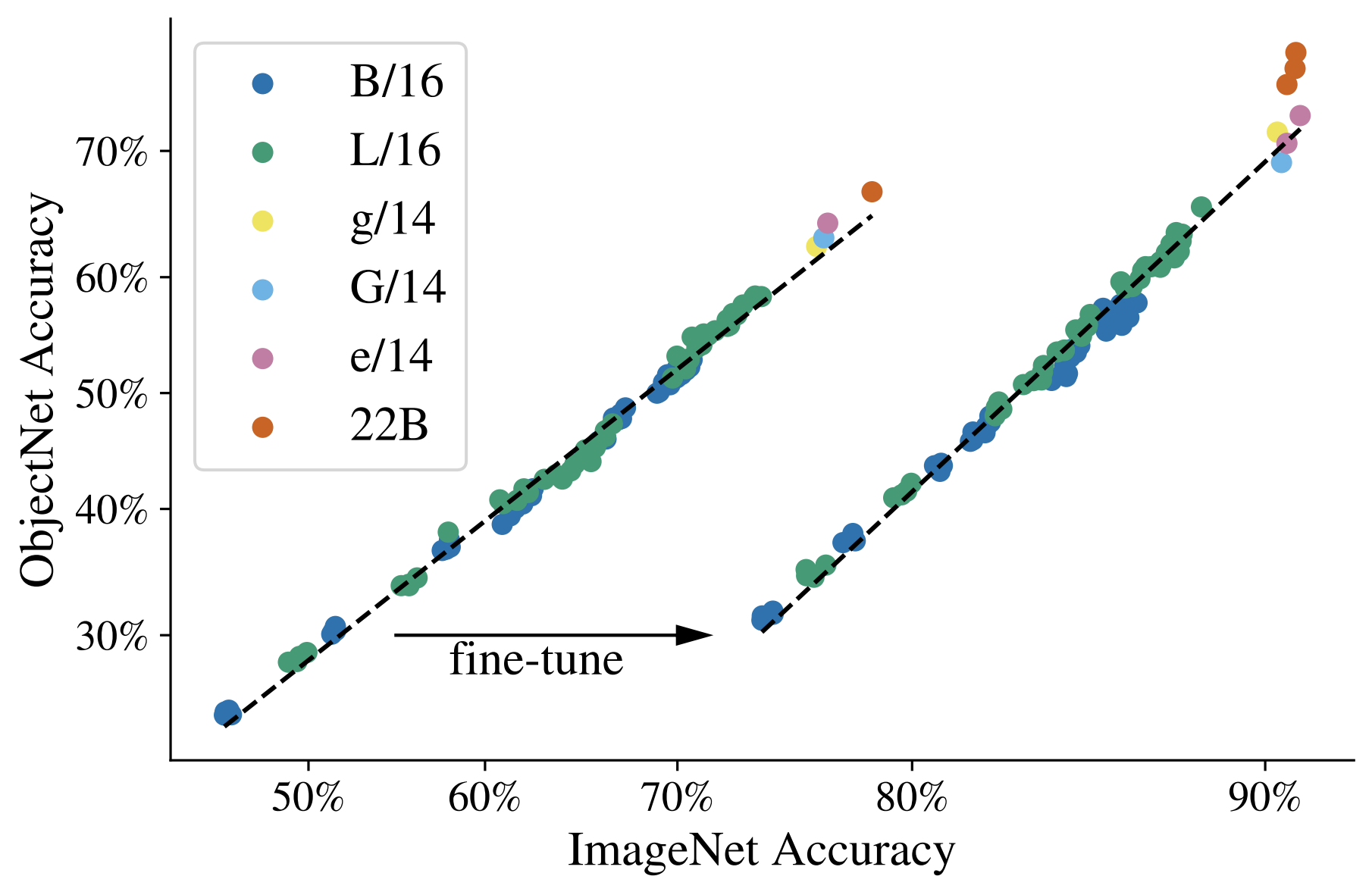 |
| حتی اگر دقت ImageNet اشباع شود، ما شاهد افزایش قابل توجهی در عملکرد در ObjectNet از ViT-e/14 به ViT-22B هستیم. |
کاوشگر خطی
کاوشگر خطی تکنیکی است که در آن یک لایه خطی منفرد در بالای یک مدل منجمد آموزش داده می شود. در مقایسه با تنظیم دقیق کامل، آموزش بسیار ارزانتر و راهاندازی آسانتر است. ما مشاهده کردیم که کاوشگر خطی عملکرد ViT-22B به تنظیمات دقیق مدل های کوچکتر با استفاده از تصاویر با وضوح بالا نزدیک می شود (آموزش با وضوح بالاتر معمولاً بسیار گران تر است، اما برای بسیاری از کارها نتیجه می دهد. نتایج بهتر). در اینجا نتایج یک کاوشگر خطی آموزش داده شده بر روی مجموعه داده ImageNet و ارزیابی شده بر روی مجموعه داده اعتبارسنجی ImageNet و سایر مجموعه داده های OOD ImageNet است.
تقطیر
دانش مدل بزرگتر را می توان با استفاده از روش تقطیر به مدل کوچکتر منتقل کرد. این مفید است زیرا مدل های بزرگ کندتر و گران تر هستند. ما متوجه شدیم که دانش ViT-22B را می توان به مدل های کوچکتر مانند ViT-B/16 و ViT-L/16 منتقل کرد و به وضعیت جدیدی از هنر در ImageNet برای آن اندازه مدل دست یافت.
انصاف و تعصب
مدلهای ML میتوانند مستعد سوگیریهای ناخواسته ناعادلانه باشند، مانند انتخاب همبستگیهای جعلی (اندازهگیری شده با استفاده از برابری جمعیتی) یا داشتن شکافهای عملکردی در بین زیر گروهها. ما نشان میدهیم که افزایش اندازه به کاهش چنین مسائلی کمک میکند.
اول، مقیاس مرز مبادله مطلوب تری را ارائه می دهد – عملکرد با مقیاس بهبود می یابد، حتی زمانی که مدل پس از آموزش پردازش می شود تا سطح برابری جمعیتی آن زیر یک سطح قابل تحمل و تجویز شده کنترل شود. نکته مهم، این است که نه تنها زمانی که عملکرد از نظر دقت اندازهگیری میشود، بلکه سایر معیارها مانند کالیبراسیون که معیاری آماری از صحت احتمالات تخمین زده شده مدل است نیز صادق است. دوم، طبقهبندی همه زیر گروهها با مقیاس بهبود مییابد که در زیر نشان داده شده است. سوم، ViT-22B شکاف عملکرد را در بین زیر گروه ها کاهش می دهد.
 |
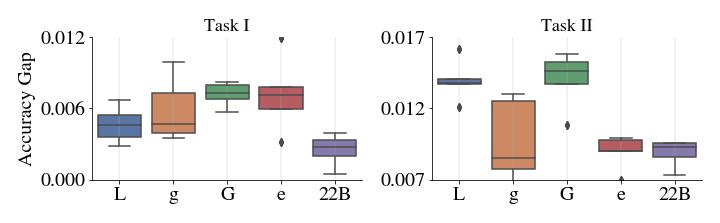 |
| بالا: دقت برای هر زیر گروه در CelebA قبل از انحراف. پایین: محور y تفاوت مطلق عملکرد را در بین دو زیر گروه مشخص شده در این مثال نشان می دهد: زنان و مردان. ViT-22B در مقایسه با معماری های کوچکتر ViT شکاف کمی در عملکرد دارد. |
نتیجه گیری
ما ViT-22B را ارائه کرده ایم که در حال حاضر بزرگترین مدل ترانسفورماتور بینایی با 22 میلیارد پارامتر است. با تغییرات کوچک اما حیاتی در معماری اصلی، ما به استفاده از سختافزار عالی و پایداری آموزشی دست یافتیم و مدلی را ارائه دادیم که وضعیت هنر را در چندین معیار پیشرفت میکند. عملکرد عالی را می توان با استفاده از مدل یخ زده برای تولید جاسازی و سپس آموزش لایه های نازک در بالا به دست آورد. ارزیابیهای ما بیشتر نشان میدهد که ViT-22B در مقایسه با مدلهای موجود، شباهتهای بیشتری را به ادراک بصری انسان نشان میدهد، و در مقایسه با مدلهای موجود، مزایایی را در انصاف و استحکام ارائه میدهد.
سپاسگزاریها
این اثر مشترک مصطفی دهقانی، جوسیپ جولانگا، باسیل مصطفی، پیوتر پادلوسکی، جاناتان هیک، جاستین گیلمر، آندریاس اشتاینر، ماتیلد کارون، رابرت گیرهوس، ابراهیم آلابدالموحسین، رودولف جناتتون، لوکاس بیر، مایکل تشاننن، ژاویراگو آراگو است. کارلوس ریکلمه، ماتیاس میندرر، جوآن پویگسرور، اوتکو اوچی، مانوج کومار، جورد ون استینکیست، گامالالدین فتحی، الساید آراوینده ماهندران، فیشر یو، آویتال الیور، فانتین هوت، جاسمین باستینگز، مارک پاتریک کولیهریستن، الکسی، واسکونسلوس، یی تای، توماس منسینک، الکساندر کولسنیکوف، فیلیپ پاوتیچ، داستین تران، توماس کیپف، ماریو لوچیچ، شیائووا ژای، دنیل کیسرز جرمیا هارمسن و نیل هولزبی
مایلیم از جاسپر اوایلینگ، جرمی کوهن، آروشی گوئل، رادو سوریکوت، زینگی ژو، لوئیس کاستروژون، آدام پاسکه، جوئل بارال، فدریکو لبرون، بلیک هختمن و پیتر هاوکینز تشکر کنیم. تخصص و پشتیبانی بی دریغ آنها نقش مهمی در تکمیل این مقاله ایفا کرد. ما همچنین از همکاری و فداکاری محققان و مهندسان با استعداد در Google Research قدردانی می کنیم.
1توجه: ViT-22B دارای 54.9٪ استفاده از FLOPs مدل (MFU) است در حالی که PalM 46.2٪ MFU را گزارش کرده است و ما 44.0٪ MFU را برای ViT-e روی همان سخت افزار اندازه گیری کردیم. ↩