پاسخگویی به سوال بصری (VQA) یک کار یادگیری ماشینی است که نیاز به یک مدل برای پاسخ به یک سوال در مورد یک تصویر یا مجموعه ای از تصاویر دارد. رویکردهای مرسوم VQA به مقدار زیادی از دادههای آموزشی برچسبگذاریشده شامل هزاران جفت پرسش-پاسخ مشروح انسانی مرتبط با تصاویر نیاز دارند. در سالهای اخیر، پیشرفتهای پیشآموزشی در مقیاس بزرگ منجر به توسعه روشهای VQA شده است که با کمتر از پنجاه نمونه آموزشی (چند شات) و بدون هیچ گونه داده آموزشی VQA مشروح شده توسط انسان (شات صفر) به خوبی عمل میکنند. با این حال، هنوز شکاف عملکرد قابل توجهی بین این روش ها و روش های پیشرفته VQA تحت نظارت کامل، مانند MaMMUT و VinVL وجود دارد. به طور خاص، روش های چند شات با استدلال فضایی، شمارش و استدلال چند هاپ مبارزه می کنند. علاوه بر این، روشهای چند شات به طور کلی به پاسخ دادن به سؤالات مربوط به تصاویر منفرد محدود شدهاند.
برای بهبود دقت در نمونههای VQA که مستلزم استدلال پیچیده هستند، در «پاسخگویی به سؤالات بصری مدولار از طریق تولید کد» که در ACL 2023 ظاهر میشود، ما CodeVQA را معرفی میکنیم، چارچوبی که به سؤالات بصری با استفاده از ترکیب برنامه پاسخ میدهد. به طور خاص، هنگامی که سؤالی در مورد یک تصویر یا مجموعه ای از تصاویر داده می شود، CodeVQA یک برنامه (کد) پایتون با توابع بصری ساده ایجاد می کند که به آن امکان پردازش تصاویر را می دهد و این برنامه را برای تعیین پاسخ اجرا می کند. ما نشان میدهیم که در تنظیمات چند عکس، CodeVQA تقریباً 3٪ در مجموعه داده COVR و 2٪ در مجموعه داده GQA از کارهای قبلی بهتر است.
CodeVQA
رویکرد CodeVQA از یک مدل زبان بزرگ کدنویسی (LLM)، مانند PALM، برای تولید برنامههای پایتون (کد) استفاده میکند. ما LLM را برای استفاده صحیح از توابع بصری با ایجاد یک اعلان متشکل از شرح این توابع و کمتر از پانزده مثال “در متن” از سوالات بصری همراه با کد پایتون مرتبط برای آنها راهنمایی می کنیم. برای انتخاب این مثالها، جاسازیها را برای سؤال ورودی و همه سؤالهایی که برای آنها برنامههای حاشیهنویسی کردهایم محاسبه میکنیم (مجموعه پنجاهی که بهطور تصادفی انتخاب شدهاند). سپس سوالاتی را که بیشترین شباهت را به ورودی دارند انتخاب می کنیم و از آنها به عنوان مثال های درون متنی استفاده می کنیم. با توجه به درخواست و سوالی که می خواهیم به آن پاسخ دهیم، LLM یک برنامه پایتون تولید می کند که آن سوال را نشان می دهد.
ما چارچوب CodeVQA را با استفاده از سه عملکرد بصری نمونه سازی می کنیم: (1) query، (2) get_pos، و (3) find_matching_image.
Queryکه به سوالی در مورد یک تصویر پاسخ می دهد، با استفاده از روش چند شات Plug-and-Play VQA (PnP-VQA) پیاده سازی شده است. PnP-VQA زیرنویسها را با استفاده از BLIP ایجاد میکند – یک ترانسفورماتور زیرنویس تصویر که از قبل روی میلیونها جفت تصویر-کپشن آموزش داده شده است – و آنها را به یک LLM تغذیه میکند که پاسخهای سؤال را به بیرون میدهد.Get_pos، که محلی ساز شی است که توضیحاتی از یک شی را به عنوان ورودی می گیرد و موقعیت آن را در تصویر برمی گرداند، با استفاده از GradCAM پیاده سازی می شود. به طور خاص، توضیحات و تصویر از طریق رمزگذار متن-تصویر مشترک BLIP، که امتیاز تطبیق تصویر و متن را پیشبینی میکند، منتقل میشود. GradCAM شیب این امتیاز را با توجه به ویژگی های تصویر می گیرد تا منطقه ای را که بیشترین ارتباط را با متن دارد پیدا کند.Find_matching_image، که در سوالات چند تصویری برای یافتن تصویری که به بهترین وجه با یک عبارت ورودی داده شده مطابقت دارد استفاده می شود، با استفاده از رمزگذارهای متن و تصویر BLIP برای محاسبه تعبیه متن برای عبارت و جاسازی تصویر برای هر تصویر پیاده سازی می شود. سپس محصولات نقطه ای متن جاسازی شده با هر جاسازی تصویر نشان دهنده ارتباط هر تصویر با عبارت است و ما تصویری را انتخاب می کنیم که این ارتباط را به حداکثر می رساند.
این سه تابع را می توان با استفاده از مدل هایی که نیاز به حاشیه نویسی بسیار کمی دارند (مثلاً جفت های متن و تصویر-متن جمع آوری شده از وب و تعداد کمی از نمونه های VQA) پیاده سازی کرد. علاوه بر این، چارچوب CodeVQA را می توان به راحتی فراتر از این توابع به سایر توابع که کاربر ممکن است اجرا کند تعمیم داد (به عنوان مثال، تشخیص شی، تقسیم بندی تصویر، یا بازیابی پایگاه دانش).
 |
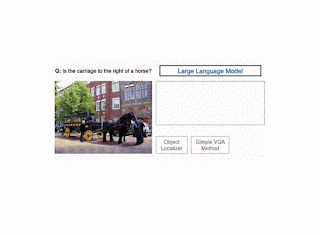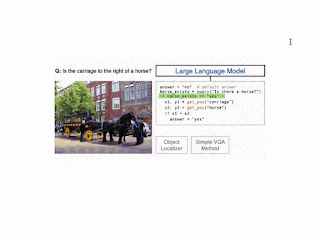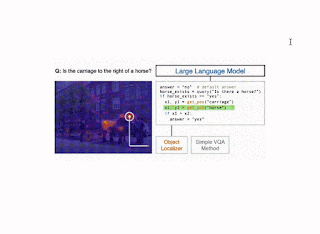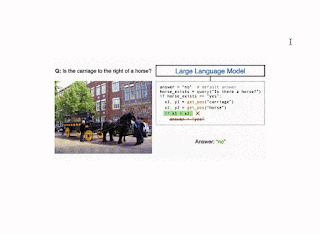
تصویری از روش CodeVQA. ابتدا، یک مدل زبان بزرگ، یک برنامه (کد) پایتون تولید میکند که توابع بصری را فراخوانی میکند که سؤال را نشان میدهد. در این مثال، یک روش ساده VQA (query(get_pos) برای یافتن موقعیت اشیاء ذکر شده استفاده می شود. سپس برنامه با ترکیب خروجی های این توابع پاسخی برای سوال اصلی تولید می کند. |
نتایج
چارچوب CodeVQA برنامه های پایتون را نه تنها برای سوالات تک تصویری، بلکه برای سوالات چند تصویری نیز به درستی تولید و اجرا می کند. برای مثال، اگر دو تصویر به شما داده شود که هر کدام دو پاندا را نشان میدهند، سؤالی که ممکن است بپرسد این است: “آیا درست است که چهار پاندا وجود دارد؟” در این حالت، LLM سؤال شمارش جفت تصویر را به برنامهای تبدیل میکند که در آن برای هر تصویر تعداد شیء به دست میآید (با استفاده از پرس و جو تابع). سپس تعداد هر دو تصویر برای محاسبه تعداد کل اضافه می شود، که سپس با عدد موجود در سوال اصلی مقایسه می شود تا پاسخ بله یا خیر به دست آید.
 |
ما CodeVQA را بر روی سه مجموعه داده استدلال بصری ارزیابی میکنیم: GQA (تک تصویر)، COVR (چند تصویر)، و NLVR2 (چند تصویر). برای GQA، ما 12 مثال درون زمینه ای برای هر روش ارائه می دهیم، و برای COVR و NLVR2، ما شش مثال درون متنی برای هر روش ارائه می دهیم. جدول زیر نشان می دهد که CodeVQA به طور مداوم نسبت به روش VQA چند شات پایه در هر سه مجموعه داده بهبود می یابد.
| روش | تأیید کنید | COVR | NLVR2 | ||||||||
| چند شات PnP-VQA | 46.56 | 49.06 | 63.37 | ||||||||
| CodeVQA | 49.03 | 54.11 | 64.04 |
| نتایج مربوط به مجموعه دادههای GQA، COVR و NLVR2، نشان میدهد که CodeVQA به طور مداوم نسبت به چند عکس PnP-VQA بهبود مییابد. معیار، دقت تطابق دقیق است، یعنی درصد نمونه هایی که در آنها پاسخ پیش بینی شده دقیقاً با پاسخ حقیقت پایه مطابقت دارد. |
ما متوجه شدیم که در GQA، دقت CodeVQA تقریباً 30٪ بیشتر از خط پایه در سؤالات استدلال فضایی، 4٪ بیشتر در سؤالات “و” و 3٪ بیشتر در سوالات “یا” است. دسته سوم شامل سوالات مولتی هاپ مانند “آیا نمکدان یا اسکیت برد در تصویر وجود دارد؟” است که برنامه تولید شده برای آنها در زیر نشان داده شده است.
img = open_image("Image13.jpg")
salt_shakers_exist = query(img, "Are there any salt shakers?")
skateboards_exist = query(img, "Are there any skateboards?")
if salt_shakers_exist == "yes" or skateboards_exist == "yes":
answer = "yes"
else:
answer = "no"
همانطور که در جدول زیر نشان داده شده است، در COVR، متوجه میشویم که سود CodeVQA نسبت به خط پایه زمانی که تعداد تصاویر ورودی بزرگتر باشد، بیشتر است. این روند نشان می دهد که تجزیه مسئله به سوالات تک تصویری سودمند است.
| تعداد تصاویر | |||||||||||
| روش | 1 | 2 | 3 | 4 | 5 | ||||||
| چند شات PnP-VQA | 91.7 | 51.5 | 48.3 | 47.0 | 46.9 | ||||||
| CodeVQA | 75.0 | 53.3 | 48.7 | 53.2 | 53.4 | ||||||
نتیجه
ما CodeVQA را ارائه میکنیم، چارچوبی برای پاسخگویی به سؤالات بصری چند مرحلهای که بر تولید کد برای انجام استدلال بصری چند مرحلهای متکی است. مسیرهای هیجان انگیز برای کارهای آینده شامل گسترش مجموعه ماژول های مورد استفاده و ایجاد یک چارچوب مشابه برای کارهای بصری فراتر از VQA است. ما توجه میکنیم که هنگام بررسی اینکه آیا سیستمی مانند CodeVQA را استقرار کنیم باید مراقب بود، زیرا مدلهای زبان بینایی مانند مدلهایی که در عملکردهای بصری ما استفاده میشوند، سوگیریهای اجتماعی را نشان میدهند. در عین حال، در مقایسه با مدلهای یکپارچه، CodeVQA قابلیت تفسیر اضافی (از طریق برنامه پایتون) و قابلیت کنترل (با اصلاح دستورات یا توابع بصری) را ارائه میدهد که در سیستمهای تولید مفید هستند.
سپاسگزاریها
این تحقیق با همکاری آزمایشگاه تحقیقات هوش مصنوعی دانشگاه کالیفرنیا برکلی (BAIR) و تحقیقات گوگل انجام شد و توسط سانجی سوبرامانیان، مدینی ناراسیمهان، کوشال خانگاونکار، کوین یانگ، آرشا ناگرانی، کوردلیا اشمید، اندی زنگ، تروور دارل و دن کلاین انجام شد. .