ظرفیت یک شبکه عصبی برای جذب اطلاعات به تعداد پارامترهای آن محدود میشود و در نتیجه، یافتن راههای موثرتر برای افزایش پارامترهای مدل به یک روند در تحقیقات یادگیری عمیق تبدیل شده است. ترکیبی از کارشناسان (MoE)، نوعی از محاسبات مشروط که در آن بخشهایی از شبکه بر اساس هر مثال فعال میشوند، به عنوان راهی برای افزایش چشمگیر ظرفیت مدل بدون افزایش متناسب در محاسبات پیشنهاد شدهاست. در انواع پراکنده مدلهای MoE (مثلاً Switch Transformer، GLaM، V-MoE)، زیرمجموعهای از متخصصان بر اساس هر توکن یا هر نمونه انتخاب میشوند، بنابراین پراکندگی در شبکه ایجاد میشود. چنین مدلهایی مقیاسبندی بهتری را در حوزههای متعدد و قابلیت نگهداری بهتر در یک محیط یادگیری مداوم (مثلاً Expert Gate) نشان دادهاند. با این حال، یک استراتژی مسیریابی متخصص ضعیف میتواند باعث شود که برخی از کارشناسان تحت آموزش قرار نگیرند، که منجر به تخصص کمتر یا بیش از حد متخصص میشود.
در “مخلوط از متخصصان با مسیریابی انتخاب خبره”، ارائه شده در NeurIPS 2022، ما یک الگوریتم مسیریابی MoE جدید به نام Expert Choice (EC) را معرفی می کنیم. ما بحث میکنیم که چگونه این رویکرد جدید میتواند به تعادل بار بهینه در یک سیستم MoE دست یابد و در عین حال امکان ناهمگونی در نقشهبرداری توکن به متخصص را فراهم میکند. در مقایسه با مسیریابی مبتنی بر توکن و سایر روشهای مسیریابی در شبکههای سنتی MoE، EC کارایی آموزشی بسیار قوی و نمرات وظایف پاییندستی را نشان میدهد. روش ما با یکی از دیدگاههای Pathways همخوانی دارد، که عبارت است از فعال کردن ترکیبی از متخصصان ناهمگن از طریق پشتیبانی Pathways MPMD (چند برنامه، چند داده).
مروری بر مسیریابی وزارت دفاع
MoE با پذیرش تعدادی متخصص، هر یک به عنوان یک شبکه فرعی، و فعال کردن تنها یک یا چند متخصص برای هر کد ورودی عمل می کند. یک شبکه دروازه باید انتخاب و بهینه شود تا هر توکن به مناسب ترین متخصص (ها) هدایت شود. بسته به نحوه نگاشت توکن ها به متخصصان، MOE می تواند پراکنده یا متراکم باشد. Sparse MoE تنها زیرمجموعه ای از متخصصان را هنگام مسیریابی هر نشانه انتخاب می کند و هزینه محاسباتی را در مقایسه با یک MoE متراکم کاهش می دهد. به عنوان مثال، کار اخیر مسیریابی پراکنده از طریق را پیاده سازی کرده است k-به معنای خوشه بندی است، تخصیص خطی برای به حداکثر رساندن قرابت توکن-کارشناس یا هش کردن. گوگل همچنین اخیراً GLaM و V-MoE را معرفی کرد که هر دوی آنها از طریق MoE با دروازههای پراکنده با سطح بالا، پیشرفتهترین فناوری را در پردازش زبان طبیعی و بینایی کامپیوتری ارتقا میدهند.ک مسیریابی نشانه، نشان دادن مقیاس بندی عملکرد بهتر با لایه های MoE به طور پراکنده. بسیاری از این آثار قبلی از الف انتخاب رمزی استراتژی مسیریابی که در آن الگوریتم مسیریابی بهترین یک یا دو متخصص را برای هر توکن انتخاب می کند.
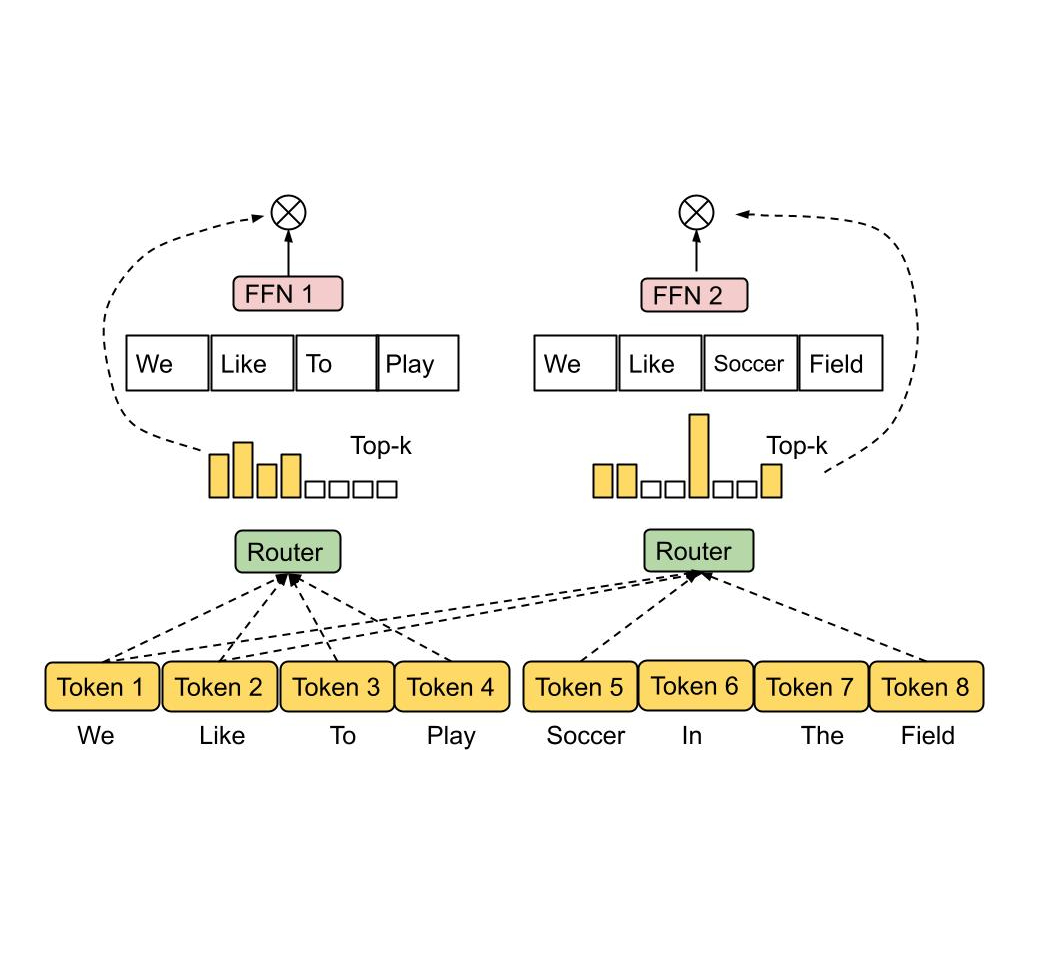
 |
| مسیریابی انتخاب رمز. الگوریتم مسیریابی، متخصصان برتر ۱ یا ۲ متخصص را با بالاترین امتیاز قرابت برای هر توکن انتخاب میکند. نمرات وابستگی را می توان همراه با پارامترهای مدل آموزش داد. |
رویکرد انتخاب توکن مستقل اغلب منجر به بار نامتعادل متخصصان و عدم استفاده می شود. به منظور کاهش این موضوع، شبکههای با دروازههای پراکنده قبلی، تلفات کمکی اضافی را به عنوان منظمسازی معرفی کردند تا از ارسال توکنهای بیش از حد به یک متخصص جلوگیری کنند، اما اثربخشی محدود بود. در نتیجه، مسیریابی های انتخاب توکن باید ظرفیت متخصص را با حاشیه قابل توجهی (2x-8x از ظرفیت محاسبه شده) بیش از حد تأمین کنند تا هنگام سرریز بافر از رها شدن توکن ها جلوگیری شود.
علاوه بر عدم تعادل بار، اکثر کارهای قبلی تعداد ثابتی از متخصصان را به هر توکن با استفاده از یک تاپ اختصاص میدهند.ک عملکرد، صرف نظر از اهمیت نسبی توکن های مختلف. ما استدلال میکنیم که توکنهای مختلف باید توسط تعداد متغیری از متخصصان، مشروط به اهمیت یا دشواری توکن، دریافت شوند.
انتخاب مسیریابی خبره
برای پرداختن به مسائل فوق، ما یک MoE ناهمگن پیشنهاد می کنیم که از روش مسیریابی انتخاب خبره که در زیر نشان داده شده است، استفاده می کند. به جای داشتن توکن، بالا را انتخاب کنیدک کارشناسان، کارشناسان با ظرفیت بافر از پیش تعیین شده به بالاترینک توکن ها این روش تعادل بار را تضمین میکند، تعداد متغیری از متخصصان را برای هر توکن اجازه میدهد، و به دستاوردهای قابلتوجهی در کارایی آموزش و عملکرد پایین دستی دست مییابد. مسیریابی EC سرعت همگرایی آموزشی را بیش از 2 برابر در مدل 8B/64E (8 میلیارد پارامتر فعال، 64 متخصص) در مقایسه با همتایان گیتینگ برتر 1 و 2 در Switch Transformer، GShard و GLaM افزایش می دهد.
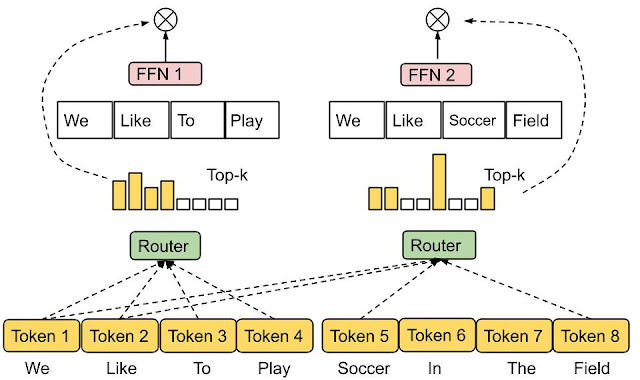 |
| انتخاب مسیریابی خبره کارشناسان با ظرفیت بافر از پیش تعیین شده به بهترین وجه اختصاص داده می شوند.ک توکن ها، بنابراین تعادل بار را تضمین می کند. هر نشانه می تواند توسط تعداد متغیری از متخصصان دریافت شود. |
در مسیریابی EC ما ظرفیت کارشناسی را تعیین می کنیم ک به عنوان میانگین توکنهای هر متخصص در دستهای از توالیهای ورودی ضرب در a فاکتور ظرفیت، که میانگین تعداد متخصصان قابل دریافت توسط هر توکن را تعیین می کند. برای یادگیری قرابت نشانه به متخصص، روش ما یک ماتریس امتیاز نشانه به متخصص تولید می کند که برای تصمیم گیری مسیریابی استفاده می شود. ماتریس امتیاز نشان می دهد که یک توکن داده شده در دسته ای از توالی های ورودی به یک متخصص معین هدایت می شود.
مشابه Switch Transformer و GShard، ما یک تابع MoE و gating را در لایه پیشخور متراکم (FFN) اعمال میکنیم، زیرا از نظر محاسباتی گرانترین بخش شبکه مبتنی بر ترانسفورماتور است. پس از تولید ماتریس امتیاز نشانه به خبره، یکک تابع در امتداد بعد نشانه برای هر متخصص اعمال می شود تا مرتبط ترین نشانه ها را انتخاب کند. سپس یک تابع جایگشت بر اساس شاخص های تولید شده توکن اعمال می شود تا یک مقدار پنهان با یک بعد متخصص اضافی ایجاد شود. داده ها بین چندین متخصص تقسیم می شوند به طوری که همه کارشناسان می توانند هسته محاسباتی یکسانی را به طور همزمان بر روی زیر مجموعه ای از توکن ها اجرا کنند. از آنجایی که می توان یک ظرفیت کارشناسی ثابت را تعیین کرد، ما دیگر ظرفیت کارشناسی را به دلیل عدم تعادل بار تامین نمی کنیم، بنابراین زمان آموزش و استنتاج را به میزان قابل توجهی در مقایسه با GLaM حدود 20٪ کاهش می دهیم.
ارزیابی
برای نشان دادن اثربخشی مسیریابی Expert Choice، ابتدا به کارایی آموزش و همگرایی نگاه می کنیم. ما از EC با ضریب ظرفیت 2 (EC-CF2) برای تطبیق اندازه پارامتر فعال و هزینه محاسباتی بر اساس هر توکن با دروازه GShard top-2 استفاده میکنیم و هر دو را برای تعداد ثابتی از مراحل اجرا میکنیم. EC-CF2 در کمتر از نیمی از مراحل به همان پیچیدگی GShard top-2 می رسد و علاوه بر این، متوجه می شویم که هر مرحله GShard top-2 20٪ کندتر از روش ما است.
ما همچنین تعداد متخصصان را در حالی که اندازه متخصص را به پارامترهای 100M برای هر دو روش EC و GShard top-2 تثبیت می کنیم، مقیاس می کنیم. ما متوجه شدیم که هر دو از نظر گیجی روی مجموعه داده ارزیابی در طول پیشآموزش به خوبی کار میکنند – داشتن کارشناسان بیشتر به طور مداوم گیجی آموزش را بهبود میبخشد.
 |
| نتایج ارزیابی در مورد همگرایی آموزشی: مسیریابی EC 2 برابر سریعتر همگرایی را در مقیاس 8B/64E در مقایسه با گیتینگ top-2 مورد استفاده در GShard و GLaM ایجاد می کند.بالا). گیجی آموزش EC با مقیاس بندی تعداد متخصصان بهتر مقیاس می شود (پایین). |
برای تأیید اینکه آیا بهبود گیجی مستقیماً به عملکرد بهتر در کارهای پایین دستی ترجمه می شود یا خیر، ما 11 کار انتخاب شده از GLUE و SuperGLUE را تنظیم دقیق انجام می دهیم. ما سه روش MoE شامل سوئیچ ترانسفورماتور بالای 1 گیتینگ (ST Top-1)، دروازه GShard top-2 (GS Top-2) و نسخه ای از روش خود (EC-CF2) را که با پارامترهای فعال شده و هزینه محاسباتی مطابقت دارد، مقایسه می کنیم. GS Top-2. روش EC-CF2 به طور مداوم از روشهای مرتبط بهتر عمل میکند و میانگین افزایش دقت بیش از 2% را در یک تنظیم بزرگ 8B/64E ایجاد میکند. با مقایسه مدل 8B/64E ما با همتای متراکم خود، روش ما به نتایج تنظیم دقیق بهتری دست می یابد و میانگین امتیاز را 3.4 امتیاز افزایش می دهد.
نتایج تجربی ما نشان میدهد که محدود کردن تعداد متخصصان برای هر توکن به طور میانگین 1 امتیاز به امتیاز تنظیم دقیق آسیب میزند. این مطالعه تأیید میکند که اجازه دادن به تعداد متغیر متخصص در هر توکن واقعاً مفید است. از سوی دیگر، ما آمار مسیریابی توکن به متخصص را محاسبه میکنیم، بهویژه در مورد نسبت توکنهایی که به تعداد معینی از متخصصان مسیریابی شدهاند. ما متوجه شدیم که اکثر توکن ها به یک یا دو متخصص هدایت شده اند، در حالی که 23٪ به سه یا چهار متخصص و تنها حدود 3٪ توکن ها به بیش از چهار متخصص هدایت شده اند، بنابراین فرضیه ما را تأیید می کند که مسیریابی انتخاب متخصص می آموزد. برای تخصیص تعداد متغیری از متخصصان به توکن ها.
افکار نهایی
ما یک روش مسیریابی جدید برای مدلهای ترکیبی از متخصصان بهصورت پراکنده پیشنهاد میکنیم. این روش به عدم تعادل بار و استفاده کم از متخصصان در روشهای متداول MOE میپردازد و امکان انتخاب تعداد مختلف متخصص برای هر توکن را فراهم میکند. مدل ما در مقایسه با مدلهای پیشرفته GShard و Switch Transformer، بیش از 2 برابر بهبود راندمان آموزشی را نشان میدهد و با تنظیم دقیق 11 مجموعه داده در معیار GLUE و SuperGLUE، به دستاوردهای قوی دست مییابد.
رویکرد ما برای مسیریابی انتخابی متخصص، MoE ناهمگن را با نوآوری های الگوریتمی ساده امکان پذیر می کند. امیدواریم که این امر منجر به پیشرفت های بیشتر در این فضا در هر دو سطح برنامه و سیستم شود.
سپاسگزاریها
بسیاری از همکاران در تحقیقات گوگل از این کار حمایت کردند. ما به ویژه از نان دو، اندرو دای، یانپینگ هوانگ و ژیفنگ چن برای کارهای زمینی اولیه روی زیرساختهای وزارت دفاع و مجموعه دادههای تارزان تشکر میکنیم. ما از Hanxiao Liu و Quoc Le برای مشارکت در ایده ها و بحث های اولیه بسیار قدردانی می کنیم. Tao Lei، Vincent Zhao، Da Huang، Chang Lan، Daiyi Peng و Yifeng Lu سهم قابل توجهی در اجرا و ارزیابی داشتند. Claire Cui، James Laudon، Martin Abadi، و Jeff Dean بازخورد و پشتیبانی منابع ارزشمندی ارائه کردند.