
زبان بصری شکل ارتباطی است که برای انتقال اطلاعات به نمادهای تصویری خارج از متن متکی است. در زندگی دیجیتالی ما به شکل شمایلنگاری، اینفوگرافیک، جداول، طرحها و نمودارها همهجا وجود دارد و به دنیای واقعی در تابلوهای خیابانی، کتابهای مصور، برچسبهای مواد غذایی و غیره گسترش مییابد. به همین دلیل، داشتن رایانهها این نوع رسانه ها می توانند به ارتباطات علمی و کشف، دسترسی و شفافیت داده ها کمک کنند.
در حالی که مدلهای بینایی کامپیوتری از زمان ظهور ImageNet با استفاده از راهحلهای مبتنی بر یادگیری پیشرفتهای شگرفی داشتهاند، تمرکز بر تصاویر طبیعی بوده است، جایی که انواع وظایف مانند طبقهبندی، پاسخگویی بصری به سؤال (VQA)، شرحنویسی، تشخیص و تقسیمبندی، برای رسیدن به عملکرد انسانی تعریف، مطالعه و در برخی موارد پیشرفته شده است. با این حال، زبان بصری سطح مشابهی از توجه را به خود جلب نکرده است، احتمالاً به دلیل عدم وجود مجموعه های آموزشی در مقیاس بزرگ در این فضا. اما در چند سال گذشته، مجموعه دادههای دانشگاهی جدیدی با هدف ارزیابی سیستمهای پاسخگویی به سؤالات روی تصاویر زبان بصری، مانند PlotQA، InfographicsVQA و ChartQA ایجاد شدهاند.
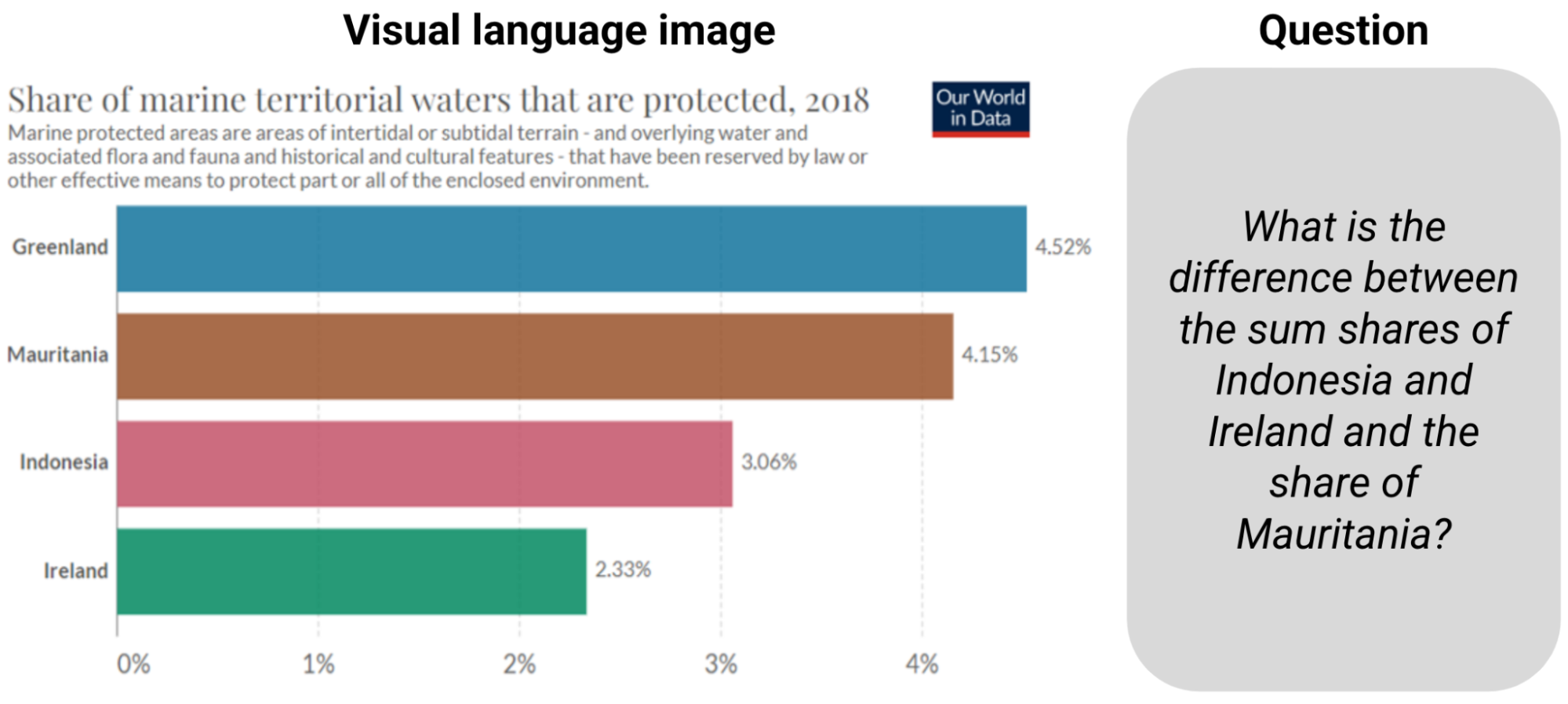 |
| مثال از ChartQA. پاسخ به سوال مستلزم خواندن اطلاعات و محاسبه مجموع و تفاوت است. |
مدلهای موجود که برای این کارها ساخته شدهاند بر ادغام اطلاعات تشخیص کاراکتر نوری (OCR) و مختصات آنها در خطوط لوله بزرگتر تکیه میکنند، اما این فرآیند مستعد خطا، کند، و تعمیم ضعیف است. شیوع این روشها به این دلیل بود که مدلهای بینایی رایانهای انتها به انتها مبتنی بر شبکههای عصبی کانولوشن (CNN) یا ترانسفورماتورهای از قبل آموزشدیده شده بر روی تصاویر طبیعی به راحتی با زبان بصری سازگار نیستند. اما مدلهای موجود برای چالشهای پاسخگویی به سؤالات روی نمودارها، از جمله خواندن ارتفاع نسبی میلهها یا زاویه برشها در نمودارهای دایرهای، درک مقیاسهای محوری، نگاشت صحیح پیکتوگرامها با مقادیر افسانهای با رنگها، اندازهها و بافتها، آماده نیستند. و در نهایت انجام عملیات عددی با اعداد استخراج شده.
در پرتو این چالشها، ما «MatCha: تقویت پیشآموزش زبان بصری با استدلال ریاضی و نمودارسازی» را پیشنهاد میکنیم. MatCha که مخفف ریاضیات و نمودارها است، یک مدل پایه پیکسل به متن است (مدلی از قبل آموزشدیده با تعصبات استقرایی داخلی که میتواند برای چندین برنامه بهخوبی تنظیم شود) که روی دو کار مکمل آموزش داده شده است: (الف) نمودار de rendering و (ب) استدلال ریاضی. در رندر کردن نمودار، با توجه به نمودار یا نمودار، مدل تصویر به متن برای ایجاد جدول داده های زیرین یا کد مورد استفاده برای رندر آن مورد نیاز است. برای پیشآموزش استدلال ریاضی، مجموعه دادههای استدلال عددی متنی را انتخاب میکنیم و ورودی را به تصاویر ارائه میکنیم، که مدل تصویر به متن برای پاسخها نیاز به رمزگشایی دارد. ما همچنین “DePlot: استدلال زبان بصری تک شات با ترجمه طرح به جدول” را پیشنهاد می کنیم، مدلی که در بالای MatCha برای استدلال تک شات روی نمودارها از طریق ترجمه به جداول ساخته شده است. با این روشها، ما بیش از 20 درصد از وضعیت قبلی در ChartQA پیشی میگیریم و بهترین سیستمهای خلاصهسازی را که 1000 برابر پارامترهای بیشتری دارند، مطابقت میدهیم. هر دو مقاله در ACL2023 ارائه خواهند شد.
رندر کردن نمودار
نمودارها و نمودارها معمولاً توسط یک جدول داده های زیرین و یک قطعه کد ایجاد می شوند. کد طرح کلی شکل را تعریف می کند (به عنوان مثال، نوع، جهت، طرح رنگ/شکل) و جدول داده های زیرین اعداد واقعی و گروه بندی آنها را تعیین می کند. هم داده ها و هم کد به یک موتور کامپایلر/رندر فرستاده می شوند تا تصویر نهایی ایجاد شود. برای درک یک نمودار، باید الگوهای بصری در تصویر را کشف کرد و به طور موثر آنها را تجزیه و گروه بندی کرد تا اطلاعات کلیدی را استخراج کند. معکوس کردن روند رندر طرح مستلزم همه چنین قابلیت هایی است و بنابراین می تواند به عنوان یک کار ایده آل قبل از آموزش عمل کند.
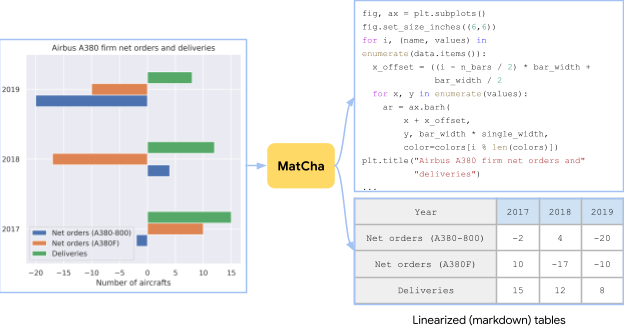 |
| نموداری که از جدولی در صفحه ایرباس A380 ویکیپدیا با استفاده از گزینههای ترسیم تصادفی ایجاد شده است. وظیفه پیشآموزشی برای MatCha شامل بازیابی جدول منبع یا کد منبع از تصویر است. |
در عمل، به دست آوردن همزمان نمودارها، جداول داده های زیربنایی و کد رندر آنها چالش برانگیز است. برای جمع آوری داده های کافی قبل از آموزش، ما به طور مستقل جمع آوری می کنیم [chart, code] و [chart, table] جفت برای [chart, code]، تمام نوتبوکهای GitHub IPython را با مجوزهای مناسب میخزیم و بلوکها را با شکلها استخراج میکنیم. یک شکل و بلوک کد درست قبل از ذخیره شدن به عنوان یک [chart, code] جفت برای [chart, table] جفت، ما دو منبع را بررسی کردیم. برای منبع اول، داده های مصنوعی، ما به صورت دستی کد می نویسیم تا جداول ویکی پدیا خزیده شده در وب را از پایگاه کد TaPas به نمودار تبدیل کنیم. بسته به نوع ستون، از چندین گزینه رسم نمونه برداری و ترکیب کردیم. علاوه بر این، ما نیز اضافه می کنیم [chart, table] جفت های تولید شده در PlotQA برای تنوع بخشیدن به مجموعه قبل از آموزش. منبع دوم خزیده شده در وب است [chart, table] جفت ما مستقیماً از [chart, table] جفتها در مجموعه آموزشی ChartQA، شامل حدود 20 هزار جفت از چهار وبسایت: Statista، Pew، Our World in Data، و OECD خزیده شدند.
استدلال ریاضی
ما دانش استدلال عددی را با یادگیری مهارتهای استدلال ریاضی از مجموعه دادههای ریاضی متنی در MatCha وارد میکنیم. ما از دو مجموعه داده استدلال ریاضی متنی، MATH و DROP برای پیشآموزش استفاده میکنیم. ریاضیات به صورت مصنوعی ایجاد شده است و شامل دو میلیون مثال آموزشی در هر ماژول (نوع) سؤال است. DROP یک مجموعه داده QA به سبک خواندن و درک مطلب است که در آن ورودی یک زمینه پاراگراف و یک سوال است.
برای حل سوالات در DROP، مدل نیاز به خواندن پاراگراف، استخراج اعداد مربوطه و انجام محاسبات عددی دارد. ما دریافتیم که هر دو مجموعه داده مکمل یکدیگر هستند. ریاضی شامل تعداد زیادی سؤال در دستههای مختلف است که به ما کمک میکند عملیات ریاضی مورد نیاز برای تزریق صریح به مدل را شناسایی کنیم. قالب خواندن و درک DROP شبیه فرمت QA معمولی است که در آن مدل ها به طور همزمان استخراج اطلاعات و استدلال را انجام می دهند. در عمل، ورودی های هر دو مجموعه داده را در تصاویر ارائه می کنیم. مدل برای رمزگشایی پاسخ آموزش داده شده است.
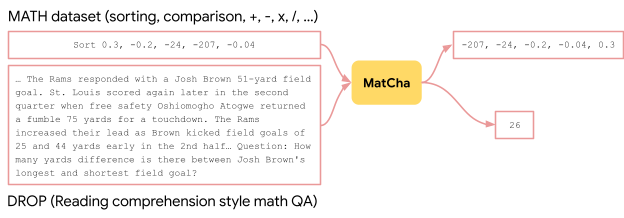 |
| برای بهبود مهارتهای استدلال ریاضی MatCha، نمونههایی از MATH و DROP را با ارائه متن ورودی بهعنوان تصویر در هدف پیشآموزشی قرار میدهیم. |
نتایج نهایی
ما از یک ستون فقرات مدل Pix2Struct استفاده میکنیم، که یک تبدیل تصویر به متن است که برای درک وبسایت طراحی شده است، و آن را با دو وظیفه که در بالا توضیح داده شد، از قبل آموزش میدهیم. ما نقاط قوت MatCha را با تنظیم دقیق آن در چندین کار زبان بصری نشان میدهیم – وظایفی که شامل نمودارها و نمودارهایی برای پاسخگویی به سؤال و خلاصهسازی میشوند، جایی که دسترسی به جدول اصلی امکانپذیر نیست. MatCha با اختلاف زیادی از عملکرد مدلهای قبلی پیشی میگیرد و همچنین از وضعیت قبلی هنر که دسترسی به جداول زیرین را فرض میکند، بهتر عمل میکند.
در شکل زیر، ابتدا دو مدل پایه را ارزیابی میکنیم که اطلاعات یک خط لوله OCR را در بر میگیرد، که تا همین اواخر رویکرد استاندارد برای کار با نمودارها بود. اولی مبتنی بر T5 است، دومی بر اساس VisionTaPas. ما همچنین با PaLI-17B مقایسه میکنیم، که یک تصویر بزرگ (تقریبا 1000 برابر بزرگتر از مدلهای دیگر) بهعلاوه تبدیلکننده متن به متن است که در مجموعهای از وظایف آموزش دیده است، اما با قابلیتهای محدود برای خواندن متن و سایر اشکال زبان بصری. . در نهایت، نتایج مدل Pix2Struct و MatCha را گزارش میکنیم.
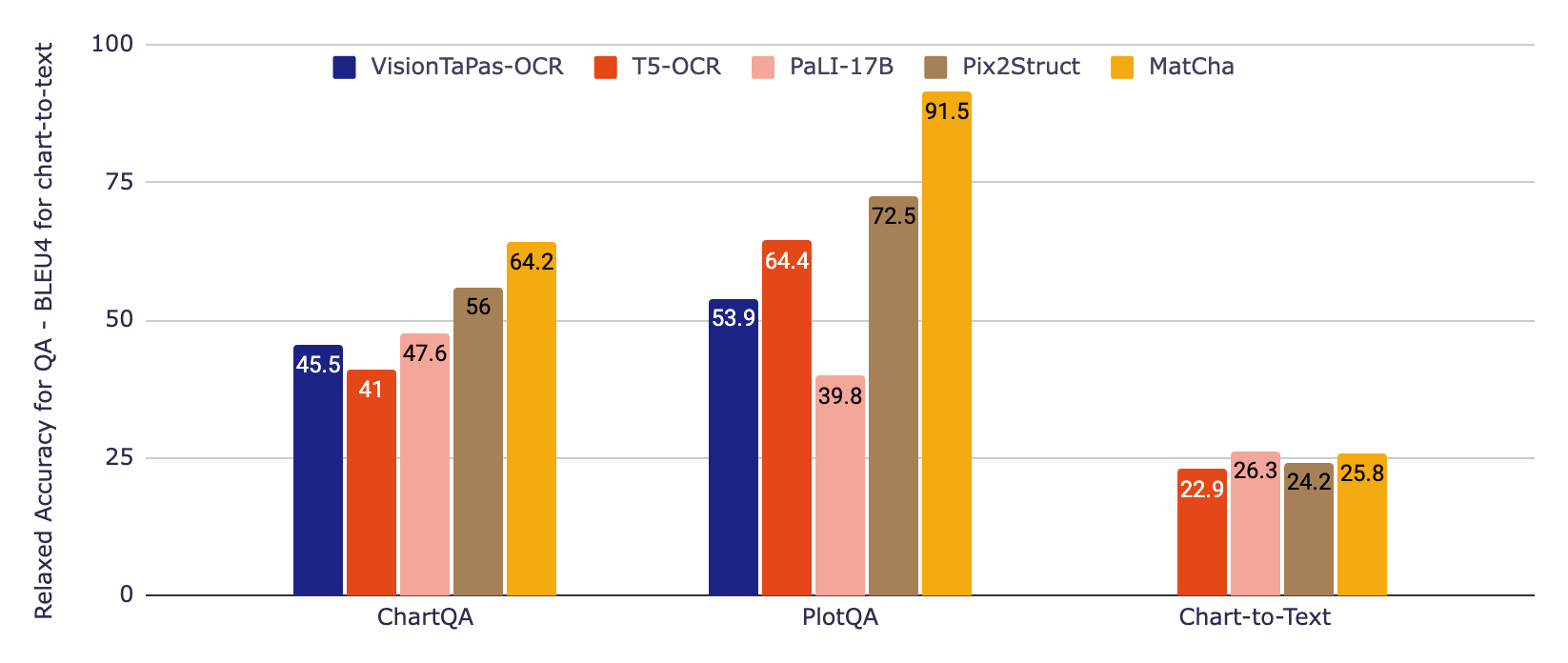 |
| نتایج تجربی روی دو معیار QA نمودار ChartQA و PlotQA (با استفاده از دقت آرام) و یک نمودار معیار خلاصهسازی نمودار نمودار به متن (با استفاده از BLEU4). Matcha در مقایسه با مدلهای بزرگتر، با اختلاف زیادی در QA از وضعیت هنر پیشی میگیرد و در خلاصهسازی با این مدلهای بزرگتر مطابقت دارد. |
برای مجموعه دادههای QA، ما از معیار رسمی دقت آرام استفاده میکنیم که اجازه خطاهای نسبی کوچک در خروجیهای عددی را میدهد. برای خلاصهسازی نمودار به متن، نمرات BLEU را گزارش میکنیم. MatCha در مقایسه با خطوط پایه برای پاسخگویی به سؤال، به نتایج بهبود قابلتوجهی دست مییابد، و به طور خلاصه نتایج قابل مقایسه با PaLI را به دست میآورد، که در آن اندازه بزرگ و پیشآموزش تولید متن طولانی / زیرنویس برای این نوع تولید متن طولانی سودمند است.
زنجیره های مدل زبان بزرگ Derendering به اضافه
در حالی که برای تعداد پارامترهایشان، به ویژه در کارهای استخراجی، بسیار کارآمد هستند، اما مشاهده کردیم که مدلهای MatCha با تنظیم دقیق هنوز هم میتوانند با استدلال پیچیده سرتاسر (به عنوان مثال، عملیات ریاضی شامل اعداد زیاد یا چند مرحله) مبارزه کنند. بنابراین، ما همچنین یک روش دو مرحلهای را برای مقابله با این موضوع پیشنهاد میکنیم: 1) یک مدل یک نمودار را میخواند، سپس جدول زیربنایی را خروجی میدهد، 2) یک مدل زبان بزرگ (LLM) این خروجی را میخواند و سپس سعی میکند به سؤال تنها بر اساس پاسخ دهد. ورودی متنی
برای مدل اول، ما MatCha را صرفاً در کار نمودار به جدول تنظیم کردیم و طول توالی خروجی را افزایش دادیم تا تضمین کنیم که میتواند تمام یا بیشتر اطلاعات نمودار را بازیابی کند. DePlot مدل به دست آمده است. در مرحله دوم، هر LLM (مانند FlanPaLM یا Codex) را می توان برای کار مورد استفاده قرار داد و ما می توانیم به روش های استاندارد برای افزایش عملکرد در LLM ها، به عنوان مثال زنجیره تفکر و سازگاری با خود، تکیه کنیم. ما همچنین با برنامه افکار آزمایش کردیم که در آن مدل کدهای اجرایی پایتون را برای تخلیه محاسبات پیچیده تولید می کند.
 |
| تصویری از روش DePlot+LLM. این یک مثال واقعی با استفاده از FlanPaLM و Codex است. کادرهای آبی ورودی به LLM و کادرهای قرمز حاوی پاسخ تولید شده توسط LLMها هستند. ما برخی از مراحل اصلی استدلال را در هر پاسخ برجسته می کنیم. |
همانطور که در مثال بالا نشان داده شده است، مدل DePlot در ترکیب با LLM ها با اختلاف قابل توجهی از مدل های تنظیم شده بهتر عمل می کند، به خصوص در بخش منابع انسانی ChartQA، که در آن سوالات طبیعی تر هستند اما استدلال دشوارتری را می طلبند. علاوه بر این، DePlot+LLM می تواند این کار را بدون دسترسی به داده های آموزشی انجام دهد.
ما مدلها و کدهای جدید را در مخزن GitHub خود منتشر کردهایم، جایی که میتوانید خودتان آن را در colab امتحان کنید. برای جزئیات بیشتر در مورد نتایج آزمایشی، مقالات MatCha و DePlot را بررسی کنید. امیدواریم که نتایج ما بتواند به نفع جامعه پژوهشی باشد و اطلاعات موجود در نمودارها و نمودارها را در دسترس همگان قرار دهد.
سپاسگزاریها
این کار توسط Fangyu Liu، Julian Martin Eisenschlos، Francesco Piccinno، Syrine Krichene، Chenxi Pang، Kenton Lee، Mandar Joshi، Wenhu Chen و Yasemin Altun از تیم زبان ما به عنوان بخشی از پروژه کارآموزی Fangyu انجام شد. نایجل کولیر از کمبریج نیز یک همکار بود. مایلیم از جاشوا هاولند، الکس پولوزوف، شرستا باسو مالیک، ماسیمو نیکوزیا و ویلیام کوهن برای نظرات و پیشنهادات ارزشمندشان تشکر کنیم.