ویدئو منبعی فراگیر از محتوای رسانهای است که بسیاری از جنبههای زندگی روزمره مردم را تحت تأثیر قرار میدهد. به طور فزایندهای، برنامههای ویدیویی دنیای واقعی، مانند زیرنویسگذاری ویدیو، تجزیه و تحلیل محتوای ویدیویی، و پاسخگویی به سؤالات ویدیویی (VideoQA)، به مدلهایی متکی هستند که میتوانند محتوای ویدیویی را با متن یا زبان طبیعی مرتبط کنند. با این حال، VideoQA به ویژه چالش برانگیز است، زیرا نیاز به درک اطلاعات معنایی، مانند اشیاء در یک صحنه، و همچنین اطلاعات زمانی دارد، به عنوان مثال، نحوه حرکت و تعامل اشیا، که هر دو باید در زمینه یک زبان طبیعی در نظر گرفته شوند. سوالی که قصد خاصی دارد علاوه بر این، از آنجایی که ویدیوها فریم های زیادی دارند، پردازش همه آنها برای یادگیری اطلاعات مکانی-زمانی می تواند از نظر محاسباتی گران باشد. با این وجود، درک همه این اطلاعات مدلها را قادر میسازد تا به سؤالات پیچیده پاسخ دهند – به عنوان مثال، در ویدیوی زیر، سؤالی درباره ماده دوم ریختهشده در کاسه نیاز به شناسایی اشیا (مواد تشکیل دهنده)، اقدامات (ریختن) و ترتیب زمانی (دوم) دارد. .
 |
| یک نمونه سوال ورودی برای وظیفه VideoQA “دومین ماده ای که در کاسه ریخته می شود چیست؟” که نیاز به درک عمیق تری از ورودی های بصری و متنی دارد. این ویدیو نمونه ای از مجموعه داده 50 سالاد است که تحت مجوز Creative Commons استفاده می شود. |
برای پرداختن به این موضوع، در «پاسخگویی به سؤالات ویدیویی با توکنسازی تکراری ویدیو-متن»، رویکرد جدیدی را برای یادگیری متن ویدیویی معرفی میکنیم که به آن میگویند. توکن سازی تکراری، که قادر است اطلاعات مکانی، زمانی و زبانی را به طور موثر برای VideoQA ترکیب کند. این رویکرد چند جریانی است و فیلمها در مقیاسهای مختلف را با مدلهای ستون فقرات مستقل برای هر کدام پردازش میکند تا نمایشهای ویدیویی تولید کند که ویژگیهای متفاوتی را به تصویر بکشد، به عنوان مثال، آنهایی که وضوح فضایی بالا یا مدت زمانی طولانی دارند. سپس این مدل ماژول co-tokenization را برای یادگیری بازنمایی های کارآمد از ترکیب جریان های ویدئویی با متن اعمال می کند. این مدل بسیار کارآمد است و تنها از 67 گیگا فلاپ (GFLOP) استفاده میکند که حداقل 50 درصد کمتر از روشهای قبلی است، در حالی که عملکرد بهتری نسبت به مدلهای پیشرفته دارد.
توکنسازی تکراری ویدئو-متن
هدف اصلی این مدل تولید ویژگیهایی از هر دو ویدیو و متن (یعنی سؤال کاربر) است که به طور مشترک اجازه میدهد ورودیهای مربوطه آنها با هم تعامل داشته باشند. هدف دوم انجام این کار به شیوه ای کارآمد است که برای ویدیوها بسیار مهم است زیرا حاوی ده ها تا صدها فریم به عنوان ورودی است.
این مدل یاد میگیرد که ورودیهای زبان ویدیویی مشترک را در مجموعه کوچکتری از نشانهها که به طور مشترک و کارآمد هر دو روش را نشان میدهند، نشانهگذاری کند. هنگام توکن کردن، ما از هر دو روش برای تولید یک نمایش فشرده مشترک استفاده می کنیم که برای تولید نمایش سطح بعدی به یک لایه ترانسفورماتور تغذیه می شود. یک چالش در اینجا، که در یادگیری چند وجهی نیز معمول است، این است که اغلب فریم ویدیو مستقیماً با متن مرتبط مطابقت ندارد. ما با افزودن دو لایه خطی قابل یادگیری که ابعاد تصویری و متنی را قبل از توکنسازی یکی میکنند، به این موضوع میپردازیم. به این ترتیب هم ویدیو و هم متن را فعال می کنیم تا نحوه یادگیری توکن های ویدیویی را شرط کنیم.
علاوه بر این، یک مرحله توکنیزاسیون تنها اجازه تعامل بیشتر بین دو روش را نمی دهد. برای آن، ما از این نمایش ویژگی جدید برای تعامل با ویژگیهای ورودی ویدیو و تولید مجموعه دیگری از ویژگیهای نشانهگذاری شده استفاده میکنیم، که سپس به لایه ترانسفورماتور بعدی وارد میشوند. این فرآیند تکراری امکان ایجاد ویژگیها یا نشانههای جدید را میدهد که نشاندهنده اصلاح مداوم نمایش مشترک از هر دو روش است. در مرحله آخر، ویژگی ها به یک رمزگشا وارد می شوند که خروجی متن را تولید می کند.
همانطور که معمولاً برای VideoQA انجام میشود، قبل از تنظیم دقیق آن در مجموعه دادههای VideoQA، مدل را از قبل آموزش میدهیم. در این کار ما از ویدیوهایی که به طور خودکار با متن بر اساس تشخیص گفتار حاشیهنویسی میشوند، استفاده میکنیم و از مجموعه داده HowTo100M بهجای پیشآموزش روی یک مجموعه داده بزرگ VideoQA استفاده میکنیم. این دادههای پیشآموزشی ضعیفتر همچنان به مدل ما امکان میدهد ویژگیهای متن ویدئویی را بیاموزد.
 |
| تجسم رویکرد هم نشان سازی تکراری متن ویدئویی. ورودیهای ویدیوی چند جریانی، که نسخههایی از همان ورودی ویدیو هستند (مثلاً یک ویدیو با وضوح بالا، با نرخ فریم پایین و یک ویدیو با وضوح پایین، با نرخ فریم بالا)، به طور موثر با ورودی متن ترکیب میشوند تا یک متن تولید کنند. پاسخ مبتنی بر رمزگشا. به جای پردازش مستقیم ورودیها، مدل توکنسازی تکراری ویدئو-متن تعداد کمتری از نشانههای مفید را از ورودیهای زبان ویدئویی ترکیب شده میآموزد. این فرآیند به صورت تکراری انجام میشود و به توکنسازی ویژگی فعلی اجازه میدهد بر انتخاب نشانهها در تکرار بعدی تأثیر بگذارد، بنابراین انتخاب را اصلاح میکند. |
پرسش و پاسخ ویدئویی کارآمد
ما الگوریتم توکنسازی تکراری زبان ویدیویی را در سه معیار اصلی VideoQA، MSRVTT-QA، MSVD-QA و IVQA اعمال میکنیم و نشان میدهیم که این رویکرد نتایج بهتری را نسبت به سایر مدلهای پیشرفته به دست میآورد، در حالی که دارای یک معیار متوسط است. اندازه. علاوه بر این، یادگیری تکراری توکن سازی مشترک باعث صرفه جویی قابل توجهی در محاسبات برای وظایف یادگیری متنی ویدئویی می شود. این روش تنها از 67 گیگا فلاپ (GFLOPS) استفاده می کند که یک ششم 360 GFLOPS مورد نیاز هنگام استفاده از مدل ویدیویی محبوب 3D-ResNet به همراه متن است و بیش از دو برابر مدل X3D کارآمدتر است. این در حالی است که نتایج بسیار دقیقی را تولید می کند و از روش های پیشرفته پیشی می گیرد.
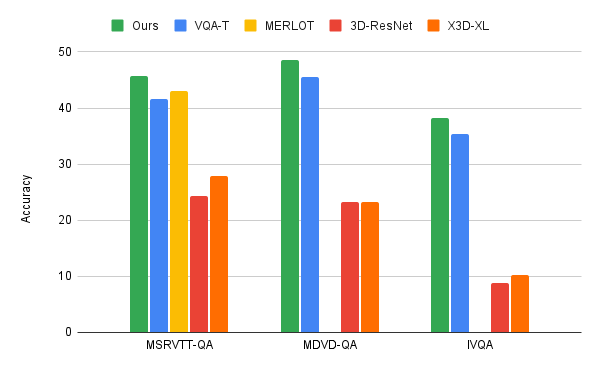 |
| مقایسه رویکرد توکنسازی تکراری ما با روشهای قبلی مانند MERLOT و VQA-T، و همچنین خطوط پایه با استفاده از ResNet-3D یا X3D-XL. |
ورودی های ویدیوی چند جریانی
برای VideoQA، یا هر یک از تعدادی از کارهای دیگر که شامل ورودیهای ویدیویی است، متوجه شدیم که ورودی چند جریانی برای پاسخ دقیقتر به سؤالات مربوط به روابط مکانی و زمانی مهم است. رویکرد ما از سه جریان ویدیویی با رزولوشنها و نرخهای فریم مختلف استفاده میکند: یک جریان ویدیوی ورودی با نرخ فریم بالا با وضوح پایین (با 32 فریم در ثانیه و وضوح فضایی 64×64، که ما آن را به عنوان 32x64x64 نشان میدهیم). یک ویدیو با وضوح بالا و نرخ فریم پایین (8x224x224)؛ و یکی در میان (16x112x112). علیرغم اطلاعات ظاهراً حجیمتر برای پردازش با سه جریان، ما مدلهای بسیار کارآمدی را به دلیل رویکرد همتوکنسازی تکراری بهدست میآوریم. در عین حال، این جریانهای اضافی امکان استخراج مرتبطترین اطلاعات را فراهم میکنند. به عنوان مثال، همانطور که در شکل زیر نشان داده شده است، سؤالات مربوط به یک فعالیت خاص در زمان، فعال سازی های بالاتری را در ورودی ویدیو با وضوح کمتر اما با نرخ فریم بالا ایجاد می کند، در حالی که سؤالات مربوط به فعالیت عمومی را می توان از ورودی با وضوح بالا پاسخ داد. فریم های بسیار کمی یکی دیگر از مزایای این الگوریتم این است که توکنیزاسیون بسته به سوالات پرسیده شده تغییر می کند.
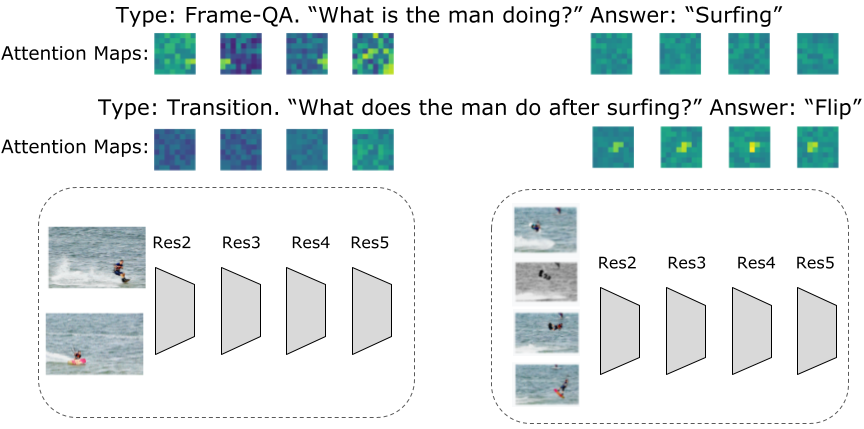 |
| تجسم نقشههای توجهی که در هر لایه در طول توکنسازی مشترک ویدئو-متن آموخته شدهاند. نقشه های توجه بسته به سوال پرسیده شده برای یک ویدیو متفاوت است. به عنوان مثال، اگر سؤال مربوط به فعالیت کلی باشد (مثلاً گشت و گذار در شکل بالا)، نقشه های توجه ورودی های نرخ فریم پایین با وضوح بالاتر فعال تر هستند و به نظر می رسد اطلاعات جهانی بیشتری را در نظر می گیرند. در حالی که اگر سوال مشخصتر باشد، به عنوان مثال، پرسیدن در مورد آنچه پس از یک رویداد اتفاق میافتد، نقشههای ویژگی محلیتر هستند و تمایل دارند در ورودی ویدیویی با نرخ فریم بالا فعال باشند. علاوه بر این، می بینیم که ورودی های ویدیویی با وضوح پایین و نرخ فریم بالا اطلاعات بیشتری در رابطه با فعالیت های ویدیو ارائه می دهند. |
نتیجه
ما یک رویکرد جدید برای یادگیری زبان ویدئویی ارائه میکنیم که بر یادگیری مشترک در روشهای متن ویدئویی تمرکز دارد. ما به وظیفه مهم و چالش برانگیز پرسش و پاسخ ویدیویی می پردازیم. رویکرد ما هم بسیار کارآمد و هم دقیق است و علیرغم کارآمدتر بودن، از مدلهای پیشرفته فعلی بهتر عمل میکند. رویکرد ما به اندازههای مدل متوسطی منجر میشود و میتواند با مدلها و دادههای بزرگتر پیشرفتهای بیشتری کسب کند. ما امیدواریم که این کار تحقیقات بیشتری را در یادگیری زبان بینایی تحریک کند تا تعامل یکپارچهتر با رسانههای مبتنی بر بینایی را فراهم کند.
سپاسگزاریها
این اثر توسط AJ Pierviovanni، Kairo Morton، Weicheng Kuo، Michael Ryoo و Anelia Angelova هدایت می شود. ما از همکاران خود در این تحقیق و Soravit Changpinyo برای نظرات و پیشنهادات ارزشمند و Claire Cui برای پیشنهادات و پشتیبانی تشکر می کنیم. ما همچنین از تام اسمال برای تجسم ها تشکر می کنیم.