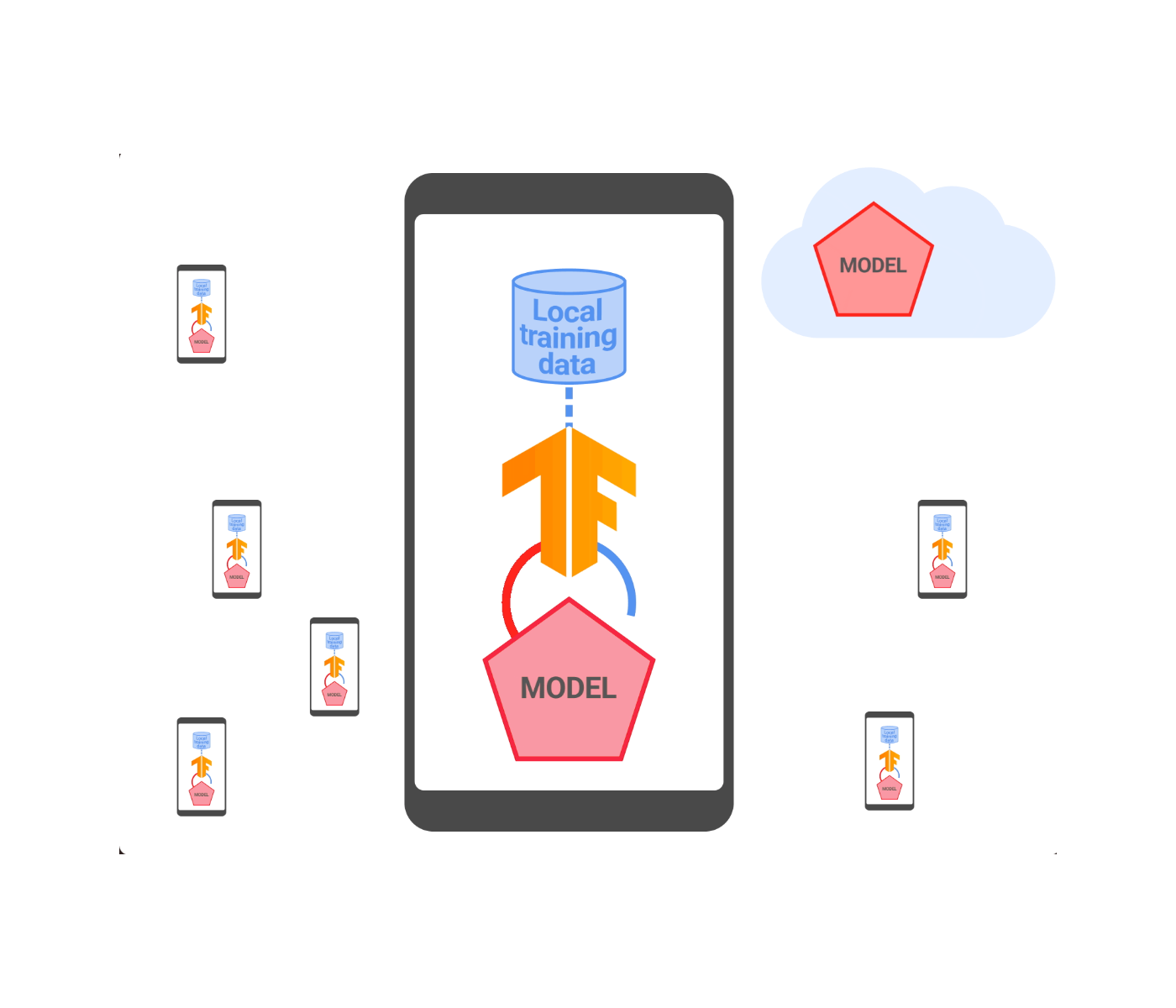
یادگیری فدرال روشی توزیع شده برای آموزش مدلهای یادگیری ماشینی (ML) است که در آن دادهها به صورت محلی پردازش میشوند و تنها بهروزرسانیهای متمرکز مدل و معیارهایی که برای تجمیع فوری در نظر گرفته شدهاند با سروری که آموزش را هماهنگ میکند به اشتراک گذاشته میشود. این اجازه می دهد تا مدل ها را بر روی سیگنال های موجود محلی بدون قرار دادن داده های خام در معرض سرورها آموزش دهید و حریم خصوصی کاربر را افزایش دهید. در سال 2021، ما اعلام کردیم که از یادگیری فدرال برای آموزش مدلهای Smart Text Selection استفاده میکنیم، ویژگی اندرویدی که به کاربران کمک میکند با پیشبینی متنی که میخواهند انتخاب کنند، متن را به راحتی انتخاب و کپی کنند و سپس به طور خودکار انتخاب را برای آنها گسترش میدهند.
از آن زمان راهاندازی، ما برای بهبود ضمانتهای حفظ حریم خصوصی این فناوری با ترکیب دقیق تجمیع امن (SecAgg) و نسخه توزیعشده حریم خصوصی دیفرانسیل تلاش کردهایم. در این پست، نحوه ساخت و استقرار اولین سیستم یادگیری فدرال را توضیح می دهیم که تضمین های رسمی حفظ حریم خصوصی را برای همه داده های کاربر فراهم می کند، قبل از اینکه برای یک سرور صادق اما کنجکاو قابل مشاهده باشد، یعنی سروری که از پروتکل پیروی می کند اما می تواند تلاش کند به دست آورد. بینش در مورد کاربران از داده هایی که دریافت می کند. مدلهای انتخاب متن هوشمند آموزشدیده شده با این سیستم، حفظ را بیش از دو برابر کاهش دادهاند، همانطور که با روشهای تست تجربی استاندارد اندازهگیری میشود.
مقیاس بندی تجمع ایمن
به حداقل رساندن داده ها یک اصل مهم حفظ حریم خصوصی در پشت یادگیری فدرال است. این به جمعآوری دادههای متمرکز، تجمیع اولیه و حداقل حفظ دادههای مورد نیاز در طول آموزش اشاره دارد. در حالی که هر دستگاهی که در یک دوره آموزشی فدرال شرکت می کند یک به روز رسانی مدل را محاسبه می کند، سرور هماهنگ کننده فقط به میانگین آنها علاقه دارد. بنابراین، در دنیایی که برای بهینهسازی دادهها بهینه میشود، سرور چیزی در مورد بهروزرسانیهای فردی نمیآموزد و فقط یک بهروزرسانی مدل انبوه را دریافت میکند. این دقیقاً همان چیزی است که پروتکل SecAgg تحت ضمانت های رمزنگاری دقیق به دست می آورد.
برای این کار مهم است، دو پیشرفت اخیر، کارایی و مقیاسپذیری SecAgg را در Google بهبود بخشیده است:
- یک پروتکل رمزنگاری بهبود یافته: تا همین اواخر، یک گلوگاه قابل توجه در SecAgg محاسبه مشتری بود، زیرا کار مورد نیاز در هر دستگاه به صورت خطی با تعداد کل مشتریان مقیاس می شد (ن) شرکت در دور. در پروتکل جدید، محاسبات مشتری اکنون به صورت لگاریتمی مقیاس می شود ن. این، همراه با دستاوردهای مشابه در هزینه های سرور، منجر به پروتکلی می شود که می تواند دورهای بزرگتر را مدیریت کند. مشارکت بیشتر کاربران در هر دور باعث بهبود حریم خصوصی می شود، چه به صورت تجربی و چه رسمی.
- ارکستراسیون مشتری بهینه شده: SecAgg یک پروتکل تعاملی است که در آن دستگاه های شرکت کننده با هم پیشرفت می کنند. یکی از ویژگیهای مهم پروتکل این است که برای برخی از دستگاههایی که خارج میشوند، قوی است. اگر یک کلاینت پاسخی را در یک پنجره زمانی از پیش تعریف شده ارسال نکند، پروتکل می تواند بدون مشارکت آن مشتری ادامه یابد. ما روشهای آماری را برای تنظیم خودکار چنین پنجره زمانی به روشی تطبیقی به کار گرفتهایم که منجر به بهبود توان عملیاتی پروتکل میشود.
پیشرفتهای فوق آموزش انتخاب متن هوشمند را با تضمینهای قویتر به حداقل رساندن دادهها آسانتر و سریعتر کرد.
جمع آوری همه چیز از طریق تجمیع امن
یک سیستم آموزشی فدرال معمولی نه تنها شامل بهروزرسانیهای مدل، بلکه معیارهایی است که عملکرد آموزش محلی را توصیف میکند. اینها برای درک رفتار مدل و اشکال زدایی مسائل آموزشی بالقوه مهم هستند. در آموزش فدرال برای انتخاب متن هوشمند، تمام بهروزرسانیها و معیارهای مدل از طریق SecAgg جمعآوری میشوند. این رفتار به صورت ایستا با استفاده از TensorFlow Federated و به صورت محلی در محیط امن Private Compute Core Android اعمال میشود. در نتیجه، این امر حریم خصوصی را برای کاربرانی که «انتخاب متن هوشمند» را آموزش میدهند، بیشتر میکند، زیرا بهروزرسانیها و معیارهای مدل تجمیعنشده برای هیچ بخشی از زیرساخت سرور قابل مشاهده نیستند.
حریم خصوصی متفاوت
SecAgg کمک می کند به حداقل رساندن قرار گرفتن در معرض دادهها، اما لزوماً مجموعههایی را ایجاد نمیکند که در برابر افشای هر چیزی منحصر به فرد برای یک فرد تضمین کند. این جایی است که حریم خصوصی تفاضلی (DP) وارد می شود. DP یک چارچوب ریاضی است که محدودیتی را بر تأثیر یک فرد بر نتیجه محاسبات، مانند پارامترهای یک مدل ML، تعیین می کند. این با محدود کردن سهم هر کاربر و اضافه کردن نویز در طول فرآیند آموزش برای تولید یک توزیع احتمال بر روی مدلهای خروجی انجام میشود. DP همراه با یک پارامتر (ه) که میزان تغییر توزیع را در هنگام افزودن یا حذف نمونه های آموزشی هر کاربر مشخص می کند (هرچه کوچکتر، بهتر).
اخیراً، روش جدیدی از آموزش فدرال را اعلام کردیم که ضمانتهای رسمی و معنادار قوی DP را به صورت متمرکز اعمال میکند، جایی که یک سرور قابل اعتماد فرآیند آموزش را کنترل میکند. این امر در برابر مهاجمان خارجی که ممکن است سعی کنند مدل را تجزیه و تحلیل کنند، محافظت می کند. با این حال، این رویکرد همچنان بر اعتماد به سرور مرکزی متکی است. برای ارائه حفاظت از حریم خصوصی حتی بیشتر، ما سیستمی ایجاد کردهایم که از حریم خصوصی دیفرانسیل توزیع شده (DDP) برای اعمال DP به شیوهای توزیعشده، یکپارچه در پروتکل SecAgg استفاده میکند.
حریم خصوصی دیفرانسیل توزیع شده
DDP یک فناوری است که تضمین های DP را با توجه به آموزش هماهنگی سرور صادقانه اما کنجکاو ارائه می دهد. با داشتن کلیپ هر دستگاه شرکتکننده و نویز بهروزرسانی آن به صورت محلی، و سپس جمعآوری این بهروزرسانیهای بریدهشده پر سر و صدا از طریق پروتکل جدید SecAgg که در بالا توضیح داده شد، کار میکند. در نتیجه سرور فقط مجموع نویز به روز رسانی های بریده شده را می بیند.
با این حال، ترکیبی از اضافه کردن نویز محلی و استفاده از SecAgg چالش های مهمی را در عمل ارائه می دهد:
- یک روش گسسته سازی بهبود یافته: یکی از چالشها، نمایش صحیح پارامترهای مدل بهعنوان اعداد صحیح در گروه محدود SecAgg با محاسبات مدولار عدد صحیح است، که میتواند هنجار مدل گسستهشده را افزایش دهد و به نویز بیشتری برای همان سطح حریم خصوصی نیاز دارد. به عنوان مثال، گرد کردن تصادفی به نزدیکترین اعداد صحیح می تواند سهم کاربر را با ضریبی برابر با تعداد پارامترهای مدل افزایش دهد. ما این را با مقیاس بندی پارامترهای مدل، اعمال یک چرخش تصادفی و گرد کردن به نزدیکترین اعداد صحیح حل کردیم. ما همچنین رویکردی را برای تنظیم خودکار مقیاس گسسته سازی در طول آموزش ایجاد کردیم. این منجر به یکپارچگی حتی کارآمدتر و دقیق تر بین DP و SecAgg شد.
- اضافه کردن نویز گسسته بهینه شده: چالش دیگر ابداع طرحی برای انتخاب تعداد دلخواه بیت در هر پارامتر مدل بدون به خطر انداختن ضمانتهای حفظ حریم خصوصی است که به نحوه برش و نویز کردن بهروزرسانیهای مدل بستگی دارد. برای پرداختن به این موضوع، نویز عدد صحیح را در حوزه گسسته اضافه کردیم و ویژگیهای DP مجموع بردارهای نویز اعداد صحیح را با استفاده از مکانیسمهای گاوسی گسسته و توزیعشده Skellam تجزیه و تحلیل کردیم.
 |
| مروری بر یادگیری فدرال با حریم خصوصی متفاوت توزیع شده |
ما راهحل DDP خود را بر روی انواع مجموعههای داده معیار و در حال تولید آزمایش کردیم و تأیید کردیم که میتوانیم دقت را با DP مرکزی با یک گروه محدود SecAgg با اندازه 12 بیت در هر پارامتر مدل مطابقت دهیم. این بدان معناست که ما توانستیم به مزایای حفظ حریم خصوصی بیشتری دست یابیم و در عین حال پهنای باند حافظه و ارتباط را نیز کاهش دهیم. برای نشان دادن این موضوع، ما از این فناوری برای آموزش و راهاندازی مدلهای Smart Text Selection استفاده کردیم. این کار با مقدار مناسبی از نویز انتخاب شده برای حفظ کیفیت مدل انجام شد. همه مدلهای Smart Text Selection که با یادگیری فدرال آموزش دیدهاند، اکنون با ضمانتهای DDP ارائه میشوند که هم برای بهروزرسانیهای مدل و هم معیارهایی که سرور در طول آموزش مشاهده میکند، اعمال میشود. ما همچنین پیاده سازی را در TensorFlow Federated منبع باز کرده ایم.
تست تجربی حریم خصوصی
در حالی که DDP ضمانتهای رسمی حریم خصوصی را به Smart Text Selection اضافه میکند، این تضمینهای رسمی نسبتا ضعیف هستند (محدود اما بزرگ ه، در صدها). با این حال، هر محدود ه بهبودی نسبت به مدلی است که تضمینی برای حفظ حریم خصوصی رسمی ندارد به چند دلیل: 1) محدود ه مدل را به رژیمی منتقل می کند که در آن بهبودهای بیشتر حریم خصوصی می تواند کمیت شود. و 2) حتی بزرگ ه‘s می تواند نشان دهنده کاهش قابل توجهی در توانایی بازسازی داده های آموزشی از مدل آموزش دیده باشد. برای به دست آوردن درک دقیق تر از مزایای تجربی حریم خصوصی، ما تجزیه و تحلیل های کاملی را با استفاده از چارچوب Secret Sharer در مدل های Smart Text Selection انجام دادیم. Secret Sharer یک تکنیک حسابرسی مدل است که می تواند برای اندازه گیری میزان به خاطر سپردن ناخواسته داده های آموزشی توسط مدل ها استفاده شود.
برای انجام تجزیه و تحلیلهای به اشتراکگذار مخفی برای انتخاب متن هوشمند، آزمایشهای کنترلی را تنظیم میکنیم که شیبها را با استفاده از SecAgg جمعآوری میکنند. آزمایشهای درمانی از جمعکنندههای حریم خصوصی دیفرانسیل با مقادیر مختلف نویز استفاده میکنند.
ما دریافتیم که حتی مقادیر کم نویز به طور معنیداری حافظه را کاهش میدهد، که بیش از دو برابر کردن معیار رتبه Secret Sharer برای قناریهای مربوطه در مقایسه با خط پایه است. این بدان معنی است که حتی اگر DP ه بزرگ است، ما به طور تجربی تأیید کردیم که این مقادیر نویز قبلاً به کاهش حافظه برای این مدل کمک می کند. با این حال، برای بهبود بیشتر در این زمینه و دریافت ضمانتهای رسمی قویتر، هدف ما استفاده از ضربکنندههای نویز بزرگتر در آینده است.
مراحل بعدی
ما اولین سیستم یادگیری فدرال و توزیع حریم خصوصی متمایز را که با ضمانتهای رسمی DP در رابطه با سرور صادق اما کنجکاو ارائه میشود، توسعه دادیم و مستقر کردیم. در حالی که محافظت های اضافی قابل توجهی ارائه می دهد، یک سرور کاملاً مخرب ممکن است همچنان بتواند تضمین های DDP را با دستکاری تبادل کلید عمومی SecAgg یا با تزریق تعداد کافی کلاینت های مخرب “جعلی” که نویز تجویز شده را به آن اضافه نمی کنند، دور بزند. استخر تجمع ما هیجان زده هستیم که با ادامه تقویت ضمانت DP و دامنه آن به این چالش ها رسیدگی کنیم.
سپاسگزاریها
نویسندگان مایلند از آدریا گاسکون برای تأثیر قابل توجه بر روی پست وبلاگ و همچنین از افرادی که به توسعه این ایده ها و اجرای آنها کمک کردند: کن لیو، جاکوب کونچینی، برندان مک ماهان، نامن آگاروال، توماس استینکه، کریستوفر شوکت تشکر کنند. آدریا گاسکن، جیمز بل، ژنگ زو، آسلا گوناواردانا، کالیستا بوناویتز، ماریانا رایکوا، استانیسلاو چیکنواریان، تانکرید لپوینت، شانشان وو، یو شیائو، زاخاری چارلز، چونشیانگ ژنگ، دانیل راماژ، گالن اندرو، هوگو سونگ، چانگ لی Neata، Ananda Theertha Suresh، Timon Van Overveldt، Zachary Garrett، Wennan Zhu و Lukas Zilka. ما همچنین میخواهیم از تام اسمال برای خلق این فیگور متحرک تشکر کنیم.