زیرنویس تصویر وظیفه یادگیری ماشینی است که به طور خودکار یک توصیف زبان طبیعی روان برای یک تصویر مشخص ایجاد می کند. این وظیفه برای بهبود دسترسی برای کاربران کم بینا مهم است و یک وظیفه اصلی در تحقیقات چندوجهی است که شامل مدلسازی بینایی و زبان میشود.
با این حال، مجموعه دادهها برای شرح تصاویر عمدتاً به زبان انگلیسی در دسترس هستند. فراتر از آن، تنها چند مجموعه داده وجود دارد که تعداد محدودی از زبانها را پوشش میدهند که تنها بخش کوچکی از جمعیت جهان را نشان میدهند. علاوه بر این، این مجموعه داده ها دارای تصاویری هستند که به شدت غنا و تنوع فرهنگ ها را از سراسر جهان نشان نمی دهند. این جنبهها مانع از تحقیقات در مورد زیرنویس تصویر برای زبانهای مختلف شده است و مستقیماً مانع استقرار راهحلهای دسترسی برای مخاطبان بالقوه زیادی در سراسر جهان شده است.
امروز مجموعه داده ارزیابی زیرنویس تصویر Crossmodal 3600 (XM3600) را به عنوان معیاری قوی برای شرح تصاویر چندزبانه ارائه کرده و در دسترس عموم قرار می دهیم که محققان را قادر می سازد مشارکت های تحقیقاتی را به طور قابل اعتماد در این زمینه نوظهور مقایسه کنند. XM3600 261375 عنوان مرجع تولید شده توسط انسان را به 36 زبان برای مجموعه ای از 3600 عکس از نظر جغرافیایی متنوع ارائه می دهد. نشان میدهیم که زیرنویسها از کیفیت بالایی برخوردار هستند و سبک آن در زبانها سازگار است.
| مجموعه داده Crossmodal 3600 شامل شرحهای مرجع به 36 زبان برای هر یک از مجموعهای از 3600 عکس از نظر جغرافیایی متنوع است. همه تصاویر با مجوز تحت مجوز CC-BY 2.0 استفاده می شوند. |
مروری بر مجموعه داده Crossmodal 3600
ایجاد مجموعه دادههای آموزشی و ارزیابی بزرگ به زبانهای مختلف، یک تلاش منابع فشرده است. کار اخیر نشان داده است که ساخت مدلهای زیرنویس تصویر چندزبانه آموزشدیده بر روی دادههای ترجمهشده ماشینی با زیرنویس انگلیسی به عنوان نقطه شروع امکانپذیر است. با این حال، برخی از قابل اعتمادترین معیارهای خودکار برای نوشتن شرح تصاویر، زمانی که برای مجموعههای ارزیابی با شرح تصاویر ترجمهشده اعمال میشوند، بسیار کمتر مؤثر هستند، و در نتیجه توافق ضعیفتری با ارزیابیهای انسانی در مقایسه با مورد انگلیسی دارد. به این ترتیب، ارزیابی مدل قابل اعتماد در حال حاضر تنها می تواند بر اساس ارزیابی گسترده انسانی باشد. متأسفانه، چنین ارزیابیهایی معمولاً نمیتوانند در تلاشهای تحقیقاتی مختلف تکرار شوند، و بنابراین مکانیسم سریع و قابل اعتمادی برای ارزیابی خودکار پارامترها و پیکربندیهای مدل (مثلاً مدل تپهنوردی) یا مقایسه چندین خط تحقیق ارائه نمیدهند.
XM3600 261375 عنوان مرجع تولید شده توسط انسان را به 36 زبان برای یک مجموعه جغرافیایی متنوع از 3600 تصویر از مجموعه داده های Open Images ارائه می دهد. ما کیفیت زیرنویسهای تولید شده را با مقایسه آنها با زیرنویسهای ارائهشده دستی با استفاده از معیار CIDEr اندازهگیری میکنیم، که از 0 (مرتبط با زیرنویسهای مرجع) تا 10 (کاملاً مطابق با زیرنویسهای مرجع) است. هنگام مقایسه جفت مدلها، همبستگی قوی بین تفاوتهای نمرات CIDEr خروجیهای مدل و ارزیابیهای انسانی در کنار هم در مقایسه خروجیهای مدل مشاهده کردیم. ساخت XM3600 ابزاری قابل اعتماد برای مقایسه خودکار با کیفیت بالا بین مدلهای زیرنویس تصویر در زبانهای مختلف فراتر از انگلیسی است.
انتخاب زبان
ما 30 زبان را فراتر از انگلیسی، تقریباً بر اساس درصد محتوای وب انتخاب کردیم. علاوه بر این، ما پنج زبان دیگر را انتخاب کردیم که شامل زبانهایی است که منابع کمتری دارند و دارای گویشوران بومی زیادی هستند یا زبانهای اصلی اصلی از قارههایی که در غیر این صورت پوشش داده نمیشوند. در نهایت، ما انگلیسی را نیز به عنوان خط پایه در نظر گرفتیم، بنابراین در مجموع 36 زبان، همانطور که در جدول زیر فهرست شده است، به دست آمد.
| عربی | بنگالی* | چینی ها | کروات | کوسکو کچوا* |
کشور چک | |||||
| دانمارکی | هلندی | انگلیسی | فیلیپینی | فنلاندی | فرانسوی | |||||
| آلمانی | یونانی | عبری | هندی | مجارستانی | اندونزیایی | |||||
| ایتالیایی | ژاپنی | کره ای | مائوری* | نروژی | فارسی | |||||
| لهستانی | پرتغالی | رومانیایی | روسی | اسپانیایی | سواحیلی* | |||||
| سوئدی | تلوگو* | تایلندی | ترکی | اوکراینی | ویتنامی |
| لیست زبان های استفاده شده در XM3600. *زبانهایی با منابع کم با بسیاری از گویشوران بومی، یا زبانهای اصلی اصلی از قارههایی که در غیر این صورت پوشش داده نمیشوند. |
انتخاب تصویر
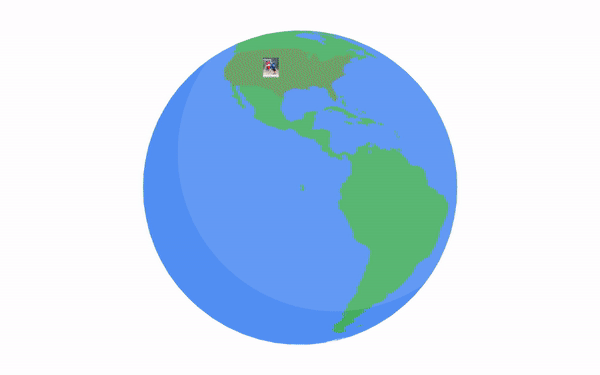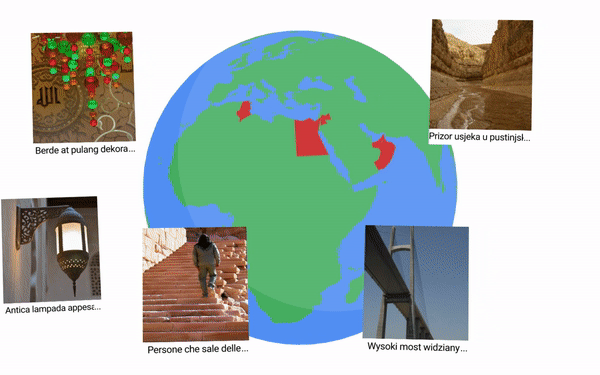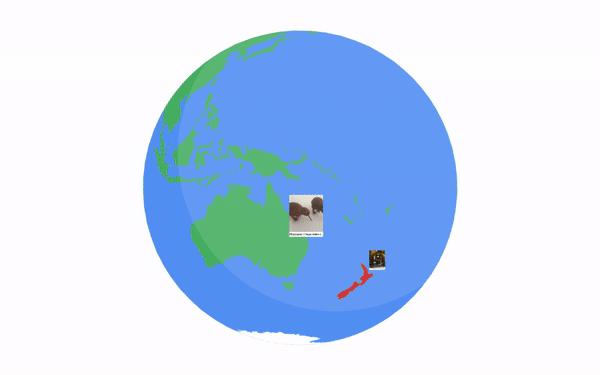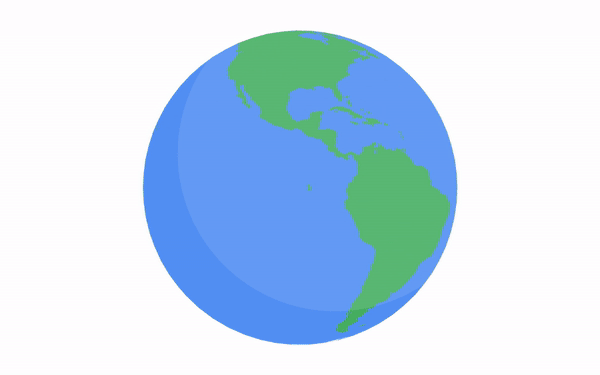
تصاویر از میان تصاویر موجود در مجموعه داده Open Images که دارای فراداده مکان هستند، انتخاب شدند. از آنجایی که مناطق زیادی وجود دارد که در آنها بیش از یک زبان صحبت می شود و برخی از مناطق به خوبی توسط این تصاویر پوشش داده نمی شوند، ما الگوریتمی را طراحی کردیم تا مطابقت بین تصاویر انتخاب شده و مناطقی که زبان های مورد نظر در آن صحبت می شوند را به حداکثر برسانیم. الگوریتم با انتخاب تصاویر با دادههای جغرافیایی مربوط به زبانهایی که کوچکترین استخر را داریم (مثلاً فارسی) شروع میکند و آنها را به ترتیب افزایش اندازه مخزن تصویر کاندیدشان پردازش میکند. اگر در منطقه ای که به یک زبان صحبت می شود تصاویر کافی وجود نداشته باشد، به تدریج شعاع انتخاب جغرافیایی را به موارد زیر گسترش می دهیم: (i) کشوری که در آن زبان صحبت می شود. (2) قاره ای که در آن زبان صحبت می شود. و به عنوان آخرین راه حل، (iii) از هر کجای دنیا. این استراتژی موفق شد تعداد تصویر هدف ما 100 تصویر را از یک منطقه مناسب برای اکثر 36 زبان، به جز فارسی (که در آن از 14 تصویر در سطح قاره استفاده می شود) و هندی (که در آن همه 100 تصویر در سطح جهانی هستند، ارائه دهد، زیرا تصاویر درون منطقه به بنگالی و تلوگو اختصاص داده شد).
| نمونه تصاویری که تنوع جغرافیایی تصاویر مشروح را نشان می دهد. تصاویر مورد استفاده تحت مجوز CC BY 2.0. |
نسل زیرنویس
در مجموع، تمام 3600 تصویر (100 تصویر در هر زبان) در تمام 36 زبان حاشیه نویسی شده اند، که هر کدام به طور متوسط دو حاشیه نویسی در هر زبان دارند و در مجموع 261375 عنوان را به دست می آورند.
حاشیه نویس ها در دسته های 15 تصویری کار می کنند. صفحه اول همه 15 تصویر را با شرحهای آنها به زبان انگلیسی نشان میدهد که توسط یک مدل شرحنویسی آموزش داده شده برای خروجی یک سبک ثابت از فرم “
اندازه دسته ای تصویر 15 انتخاب شد تا حاشیه نویسان سبک را بدون به خاطر سپردن توضیحات دقیق درونی کنند. بنابراین، ما از ارزیابها انتظار داریم که شرحها را فقط بر اساس محتوای تصویر و فاقد آثار ترجمه تولید کنند. به عنوان مثال در مثال زیر، عنوان اسپانیایی به “شماره 42” و عنوان تایلندی به “تبدیلها” اشاره میکند، که هیچ کدام در زیرنویس انگلیسی ذکر نشده است. حاشیهنویسها همچنین پروتکلی برای استفاده در هنگام ایجاد زیرنویسها ارائه کردند، بنابراین به یکنواختی سبک در بین زبانها دست یافتند.
 عکس برایان سولیس |
انگلیسی | • یک ماشین اسپرت قدیمی در یک نمایشگاه با بسیاری دیگر از ماشین های اسپورت قدیمی | ||
| • خودروهای کلاسیک مارک دار در یک ردیف در نمایشگاه | ||||
| اسپانیایی | • ماشین اسپرت کلاسیک در نمایشگاه ماشین گالری – (ماشین اسپرت کلاسیک در نمایشگاه ماشین گالری) | |||
| • ماشین مسابقه ای نقره ای کوچک با شماره 42 در یک نمایشگاه اتومبیل – (ماشین مسابقه ای کوچک نقره ای با شماره 42 در نمایشگاه اتومبیل) | ||||
| تایلندی | • کانورتیبل های چند رنگی که در کنار هم در نمایشگاه پارک شده اند – (تبدیل های چند رنگ در نمایشگاه ردیف شده اند) | |||
| • چندین ماشین مسابقه ای قدیمی در نمایشگاه صف می کشند – (چند ماشین مسابقه ای قدیمی در نمایشگاه صف می کشند.) |
| نمونه زیرنویسها به سه زبان مختلف (از 36 – فهرست کامل شرحها را در ضمیمه A مقاله Crossmodal-3600 مشاهده کنید)، ایجاد حاشیهنویسیهایی را نشان میدهد که از نظر سبک در همه زبانها سازگار هستند، در حالی که عاری از مصنوعات ترجمه مستقیم هستند (مثلاً ، اسپانیایی “شماره 42” یا تایلندی “تبدیل” در هنگام ترجمه مستقیم از نسخه های انگلیسی امکان پذیر نخواهد بود). تصویر مورد استفاده تحت مجوز CC BY 2.0. |
عنوان کیفیت و آمار
ما دو تا پنج مطالعه آزمایشی در هر زبان برای عیبیابی فرآیند تولید شرح و اطمینان از کیفیت بالا انجام دادیم. سپس به صورت دستی زیرمجموعه ای تصادفی از زیرنویس ها را ارزیابی کردیم. ابتدا نمونه ای متشکل از 600 تصویر را به صورت تصادفی انتخاب کردیم. سپس برای اندازهگیری کیفیت زیرنویسها در یک زبان خاص، برای هر تصویر، یکی از زیرنویسهای ایجاد شده بهصورت دستی را برای ارزیابی انتخاب کردیم. دریافتیم که:
- برای 25 زبان از 36 زبان، درصد زیرنویسهایی که بهعنوان «خوب» یا «عالی» رتبهبندی شدهاند، بالای 90 درصد است و بقیه همه بالای 70 درصد هستند.
- برای ۲۶ زبان از ۳۶ زبان، درصد زیرنویسهایی که بهعنوان «بد» رتبهبندی شدهاند، زیر ۲ درصد است و بقیه همه زیر ۵ درصد هستند.
برای زبانهایی که از فاصله برای جدا کردن کلمات استفاده میکنند، تعداد کلمات در هر عنوان میتواند برای برخی از زبانهای چسبنده مانند کوسکو کچوا و چک به 5 یا 6 کلمه و برای یک زبان تحلیلی مانند ویتنامی تا 18 کلمه باشد. تعداد کاراکترها در هر عنوان نیز به شدت متفاوت است – از اواسط دهه 20 برای کره ای تا اواسط دهه 90 برای اندونزیایی – بسته به الفبا و خط زبان.
ارزیابی تجربی و نتایج
ما به طور تجربی توانایی حاشیهنویسی XM3600 را برای رتبهبندی تغییرات مدل زیرنویس تصویر با آموزش چهار نوع مدل زیرنویس تصویر چندزبانه و مقایسه تفاوتهای CIDEr خروجی مدلها نسبت به مجموعه داده XM3600 برای بیش از 30 زبان، در کنار هم اندازهگیری کردیم. ارزیابی های انسانی ما همبستگی قوی بین تفاوت های CIDEr و ارزیابی های انسانی مشاهده کردیم. این نتایج از استفاده از مراجع XM3600 به عنوان ابزاری برای دستیابی به مقایسه خودکار با کیفیت بالا بین مدلهای زیرنویس تصویر در زبانهای مختلف فراتر از انگلیسی پشتیبانی میکند.
استفاده های اخیر
اخیراً PaLI از XM3600 برای ارزیابی عملکرد مدل فراتر از انگلیسی برای نوشتن شرح تصویر، بازیابی تصویر به متن و بازیابی متن به تصویر استفاده کرد. نکات کلیدی که آنها هنگام ارزیابی در XM3600 یافتند این بود که زیرنویس چند زبانه از مقیاسبندی مدلهای PaLI، بهویژه برای زبانهای کم منبع، بسیار سود میبرد.
سپاسگزاریها
مایلیم از نویسندگان همکار این اثر قدردانی کنیم: شی چن و رادو سوریکوت.