تشخیص خودکار گفتار (ASR) یک فناوری به خوبی تثبیت شده است که به طور گسترده برای کاربردهای مختلف مانند تماسهای کنفرانسی، رونویسی ویدیوی جریانی و دستورات صوتی مورد استفاده قرار میگیرد. در حالی که چالش های این فناوری حول محور نویز است سمعی ورودی ها، دیداری جریان در ویدیوهای چندوجهی (مثلاً تلویزیون، ویدیوهای ویرایش شده آنلاین) میتواند نشانههای قوی برای بهبود استحکام سیستمهای ASR ارائه دهد – این ASR سمعی و بصری (AV-ASR) نامیده میشود.
اگرچه حرکت لب میتواند سیگنالهای قوی برای تشخیص گفتار ارائه دهد و رایجترین ناحیه تمرکز برای AV-ASR است، دهان اغلب مستقیماً قابل مشاهده نیست. ویدیوها در طبیعت (به عنوان مثال، به دلیل دیدگاه های خودمحورانه، پوشش صورت، و وضوح کم) و بنابراین، یک حوزه تحقیقاتی جدید در حال ظهور است. بدون محدودیت AV-ASR (به عنوان مثال، AVATAR)، که سهم کل فریم های بصری را بررسی می کند، و نه فقط ناحیه دهان.
با این حال، ساخت مجموعه داده های سمعی و بصری برای آموزش مدل های AV-ASR چالش برانگیز است. مجموعه داده هایی مانند How2 و VisSpeech از ویدیوهای آموزشی آنلاین ایجاد شده اند، اما اندازه کوچکی دارند. در مقابل، خود مدلها معمولاً بزرگ هستند و از رمزگذارهای بصری و صوتی تشکیل شدهاند و بنابراین تمایل دارند روی این مجموعه دادههای کوچک بیش از حد قرار بگیرند. با این وجود، اخیراً تعدادی از مدلهای فقط صوتی در مقیاس بزرگ منتشر شدهاند که به شدت از طریق آموزش در مقیاس بزرگ در مقیاس بزرگ بهینهسازی شدهاند. فقط صدا داده های به دست آمده از کتاب های صوتی، مانند LibriLight و LibriSpeech. این مدل ها حاوی میلیاردها پارامتر هستند، به آسانی در دسترس هستند و تعمیم قوی در سراسر حوزه ها نشان می دهند.
با در نظر گرفتن چالشهای فوق، در «AVFormer: Injecting Vision into Frozen Speech Models for Zero-Shot AV-ASR»، ما یک روش ساده برای تقویت مدلهای صوتی در مقیاس بزرگ با اطلاعات بصری و در عین حال ارائه میکنیم. سازگاری دامنه سبک AVFormer تعبیههای بصری را به یک مدل ASR منجمد تزریق میکند (شبیه به نحوه تزریق اطلاعات بصری به مدلهای زبان بزرگ برای کارهای بینایی-متن) با استفاده از آداپتورهای سبک وزن که میتوانند بر روی مقدار کمی از دادههای ویدیویی با برچسب ضعیف با حداقل زمان آموزشی اضافی آموزش داده شوند. مولفه های. ما همچنین یک طرح برنامه درسی ساده را در طول آموزش معرفی میکنیم، که نشان میدهیم برای فعال کردن مدل برای پردازش مشترک اطلاعات صوتی و بصری به طور موثر بسیار مهم است. مدل AVFormer بهدستآمده در سه بنچمارک مختلف AV-ASR (How2، VisSpeech و Ego4D) به عملکرد پیشرفتهای دست مییابد، در حالی که عملکرد مناسب را در معیارهای سنتی تشخیص گفتار فقط صوتی (یعنی LibriSpeech) حفظ میکند. .
 |
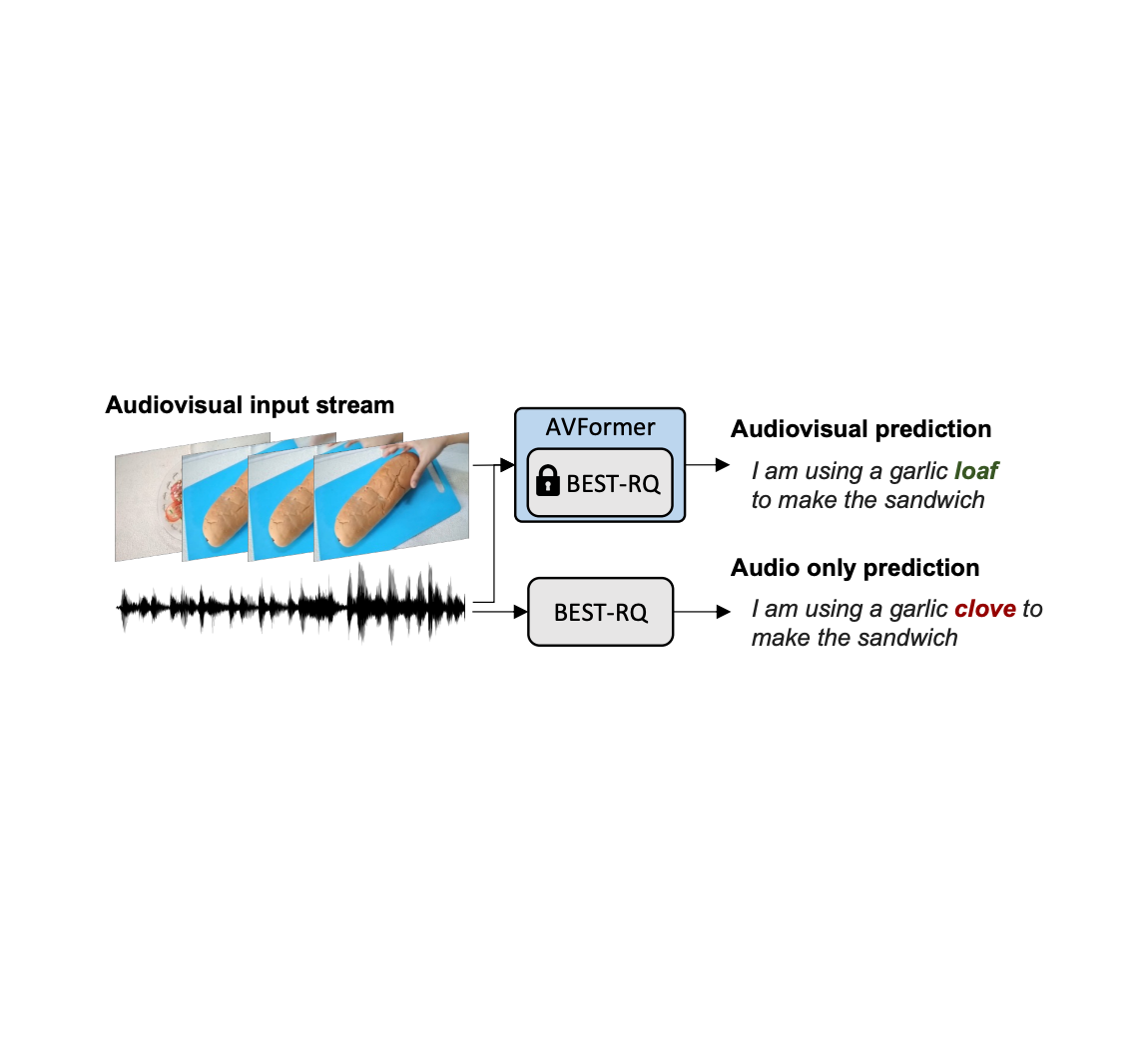
| تشخیص گفتار سمعی و بصری بدون محدودیت ما بینایی را به یک مدل گفتار منجمد (BEST-RQ، به رنگ خاکستری) برای ASR سمعی و بصری صفر شات از طریق ماژولهای سبک تزریق میکنیم تا مدلی با پارامتر و داده کارآمد به نام AVFormer (آبی) ایجاد کنیم. بافت بصری میتواند سرنخهای مفیدی برای تشخیص قوی گفتار ارائه دهد، بهویژه زمانی که سیگنال صوتی پر سر و صدا باشد (نان بصری به تصحیح اشتباه صوتی «میخک» به «نان» در رونوشت تولید شده کمک میکند). |
تزریق بینایی با استفاده از ماژول های سبک وزن
هدف ما افزودن قابلیتهای درک بصری به یک مدل ASR فقط صوتی و در عین حال حفظ عملکرد تعمیم آن به حوزههای مختلف (هم حوزههای AV و هم حوزههای فقط صوتی) است.
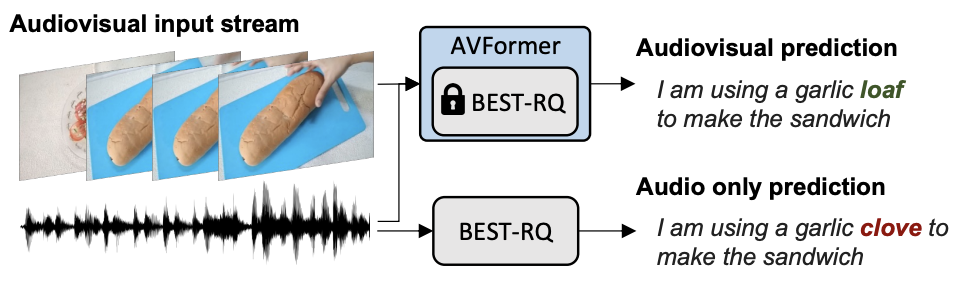
برای دستیابی به این هدف، ما یک مدل پیشرفته ASR موجود (Best-RQ) را با دو جزء زیر تقویت می کنیم: (i) پروژکتور بصری خطی و (ii) آداپتورهای سبک وزن. اولی ویژگی های بصری را در فضای تعبیه نشانه های صوتی پروژه می دهد. این فرآیند به مدل اجازه میدهد تا بهطور مناسب ویژگیهای بصری از قبل آموزشدیدهشده و نمایشهای نشانه ورودی صوتی را به درستی متصل کند. سپس مدل دوم حداقل مدل را تغییر می دهد تا درک ورودی های چندوجهی از ویدیوها را اضافه کند. سپس این ماژولهای اضافی را بر روی ویدیوهای وب بدون برچسب از مجموعه داده HowTo100M، همراه با خروجیهای یک مدل ASR بهعنوان شبه حقیقت پایه، آموزش میدهیم، در حالی که بقیه مدل Best-RQ را ثابت نگه میداریم. چنین ماژول های سبک وزن، کارایی داده و تعمیم قوی عملکرد را ممکن می کند.
ما مدل توسعه یافته خود را بر روی معیارهای AV-ASR در یک تنظیمات صفر شات ارزیابی کردیم، جایی که مدل هرگز بر روی مجموعه داده AV-ASR مشروح دستی آموزش داده نمی شود.
یادگیری برنامه درسی برای تزریق بینایی
پس از ارزیابی اولیه، ما به طور تجربی دریافتیم که با یک دور ساده و ساده از آموزش مشترک، مدل برای یادگیری آداپتورها و پروژکتورهای بصری در یک حرکت تلاش می کند. برای کاهش این مشکل، ما یک استراتژی یادگیری برنامه درسی دو مرحله ای را معرفی کردیم که این دو عامل – انطباق دامنه و ادغام ویژگی های بصری – را از هم جدا می کند و شبکه را به روشی متوالی آموزش می دهد. در مرحله اول، پارامترهای آداپتور بدون تغذیه توکن های بصری بهینه می شوند. هنگامی که آداپتورها آموزش داده شدند، نشانههای بصری را اضافه میکنیم و لایههای نمایش تصویری را به تنهایی در مرحله دوم آموزش میدهیم در حالی که آداپتورهای آموزشدیده منجمد نگه داشته میشوند.
مرحله اول بر روی تطبیق دامنه صوتی تمرکز دارد. در مرحله دوم، آداپتورها کاملاً منجمد شدهاند و پروژکتور بصری باید به سادگی یاد بگیرد که اعلانهای بصری ایجاد کند که نشانههای بصری را در فضای صوتی پخش میکند. به این ترتیب، استراتژی یادگیری برنامه درسی ما به مدل اجازه می دهد تا ورودی های بصری را ترکیب کند و همچنین با حوزه های صوتی جدید در معیارهای AV-ASR سازگار شود. ما هر فاز را فقط یک بار اعمال می کنیم، زیرا استفاده تکراری از فازهای متناوب منجر به کاهش عملکرد می شود.
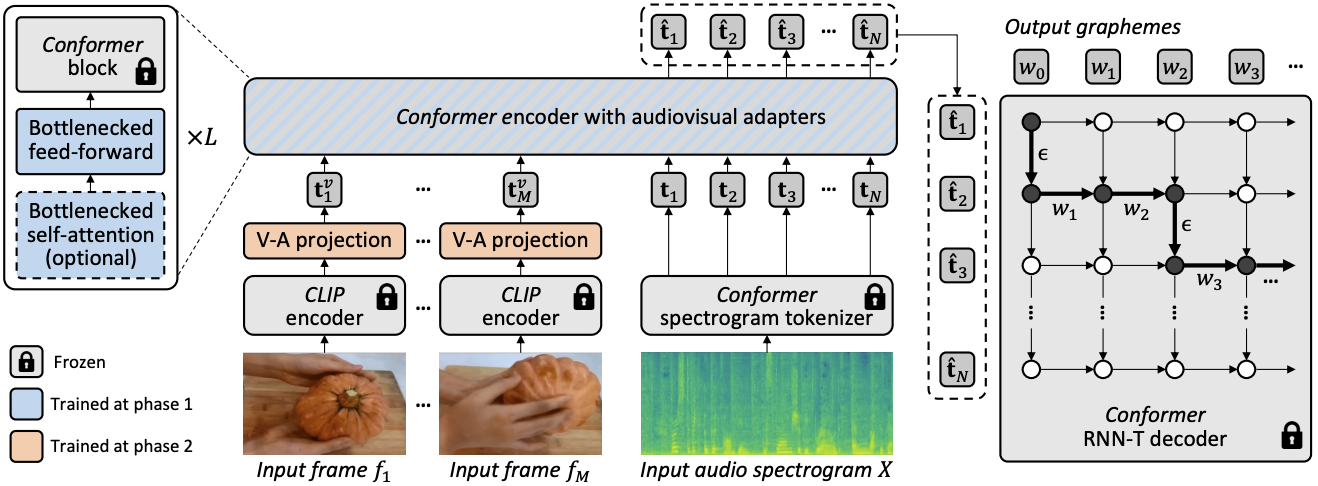 |
| روش کلی معماری و آموزش برای AVFormer. این معماری از یک مدل رمزگذار-رمزگشای منجمد Conformer و یک رمزگذار CLIP منجمد (لایههای منجمد شده به رنگ خاکستری با نماد قفل نشان داده شدهاند)، در ارتباط با دو ماژول سبک وزن قابل آموزش – (i) لایه نمایش تصویری (نارنجی) و آداپتورهای تنگنا ( آبی) برای فعال کردن تطبیق دامنه چندوجهی. ما یک استراتژی یادگیری برنامه درسی دو مرحلهای را پیشنهاد میکنیم: آداپتورها (آبی) ابتدا بدون هیچ نشانه بصری آموزش داده میشوند، پس از آن لایه نمایش تصویری (نارنجی) تنظیم میشود در حالی که تمام قسمتهای دیگر منجمد میشوند. |
نمودارهای زیر نشان میدهند که بدون یادگیری برنامه درسی، مدل AV-ASR ما بدتر از خط پایه فقط صوتی در تمام مجموعههای داده است، و با اضافه شدن نشانههای بصری بیشتر، شکاف افزایش مییابد. در مقابل، هنگامی که برنامه درسی دو مرحله ای پیشنهادی اعمال می شود، مدل AV-ASR ما به طور قابل توجهی بهتر از مدل پایه فقط صوتی عمل می کند.
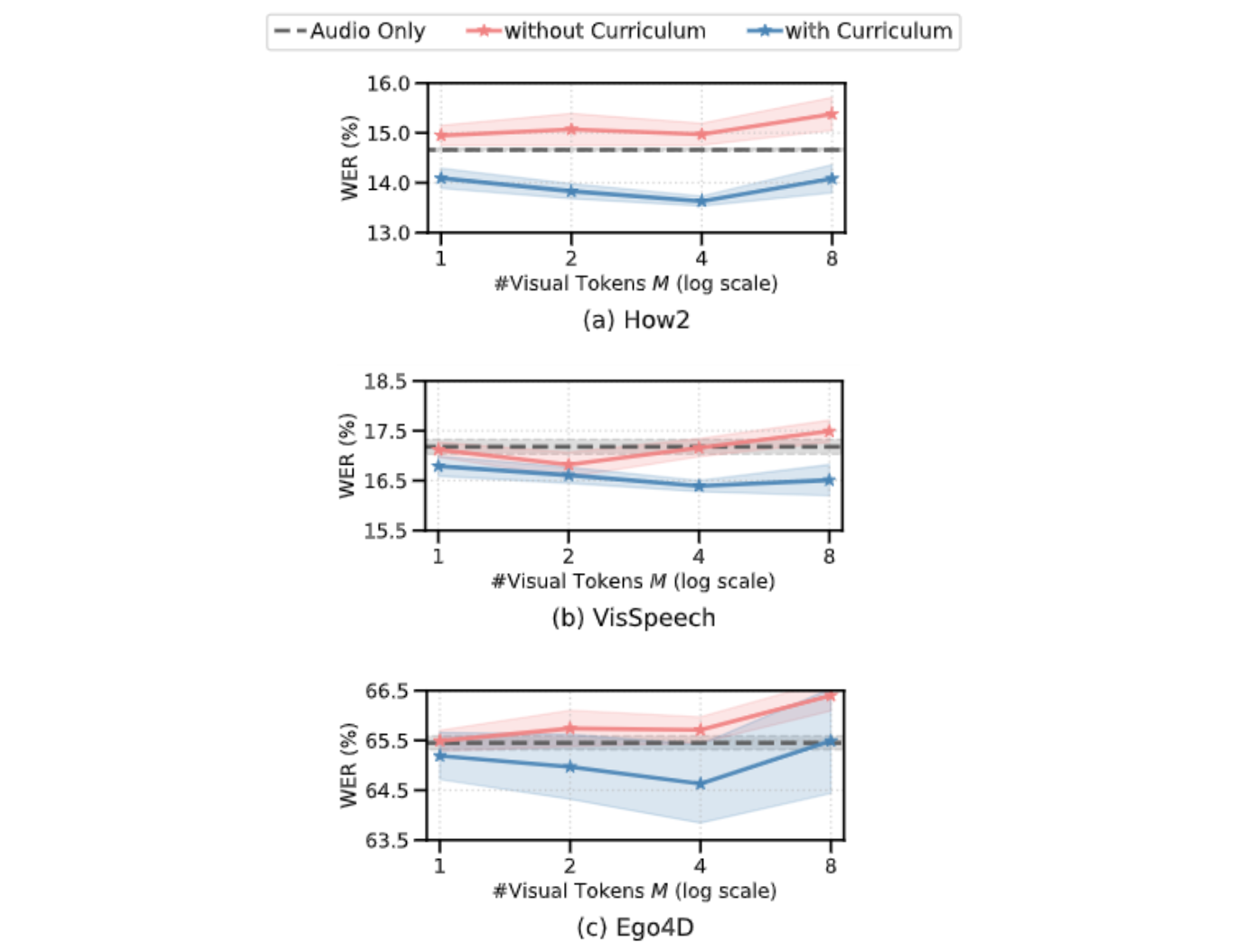 |
| اثرات یادگیری برنامه درسی. خطوط قرمز و آبی برای مدل های سمعی و بصری هستند و در 3 مجموعه داده در تنظیمات صفر شات نشان داده شده اند (% WER کمتر بهتر است). استفاده از برنامه درسی به هر 3 مجموعه داده کمک می کند (برای How2 (a) و Ego4D (c) برای عملکرد بهتر از عملکرد صوتی بسیار مهم است). عملکرد تا 4 نشانه بصری بهبود مییابد که در آن مرحله اشباع میشود. |
نتایج در صفر شات AV-ASR
ما AVFormer را با BEST-RQ، نسخه صوتی مدل خود، و AVATAR، وضعیت هنر در AV-ASR، برای عملکرد صفر شات در سه معیار AV-ASR مقایسه میکنیم: How2، VisSpeech و Ego4D. AVFormer از AVATAR و BEST-RQ در همه عملکرد بهتری دارد، حتی زمانی که آنها در LibriSpeech و مجموعه کامل HowTo100M آموزش می بینند، از هر دو AVATAR و BEST-RQ بهتر عمل می کند. این قابل توجه است زیرا برای BEST-RQ، این شامل آموزش 600M پارامتر است، در حالی که AVFormer فقط 4M پارامتر را آموزش می دهد و بنابراین تنها به بخش کوچکی از مجموعه داده آموزشی (5٪ از HowTo100M) نیاز دارد. علاوه بر این، عملکرد LibriSpeech را نیز ارزیابی میکنیم که فقط صوتی است و AVFormer از هر دو خط پایه بهتر عمل میکند.
.png) |
| مقایسه با روش های پیشرفته برای عملکرد صفر شات در مجموعه داده های مختلف AV-ASR. ما همچنین اجراهایی را در LibriSpeech که فقط صوتی است نشان میدهیم. نتایج به عنوان % WER گزارش می شود (کمتر بهتر است). AVATAR و BEST-RQ در HowTo100M یکپارچه به انتها (همه پارامترها) تنظیم می شوند، در حالی که AVFormer به لطف مجموعه کوچکی از پارامترهای تنظیم شده حتی با 5٪ از مجموعه داده به طور موثر کار می کند. |
نتیجه
ما AVFormer را معرفی میکنیم، روشی سبک وزن برای تطبیق مدلهای ASR پیشرفته و منجمد برای AV-ASR. رویکرد ما عملی و کارآمد است و به عملکرد چشمگیر ضربه صفر دست می یابد. همانطور که مدلهای ASR بزرگتر و بزرگتر میشوند، تنظیم کل مجموعه پارامترهای مدلهای از پیش آموزشدیده شده غیرعملی میشود (حتی بیشتر برای حوزههای مختلف). روش ما به طور یکپارچه امکان انتقال دامنه و اختلاط ورودی بصری را در یک مدل کارآمد پارامتر می دهد.
سپاسگزاریها
این تحقیق توسط Paul Hongsuck Seo، Arsha Nagrani و Cordelia Schmid انجام شده است.