یادگیری عمیق اخیراً باعث پیشرفت فوق العاده ای در طیف گسترده ای از برنامه ها شده است، از تولید تصاویر واقعی و سیستم های بازیابی چشمگیر گرفته تا مدل های زبانی که می توانند مکالمات شبیه انسان را انجام دهند. در حالی که این پیشرفت بسیار هیجان انگیز است، استفاده گسترده از مدل های شبکه عصبی عمیق نیاز به احتیاط دارد: طبق اصول هوش مصنوعی گوگل، ما به دنبال توسعه فناوری های هوش مصنوعی مسئولانه با درک و کاهش خطرات احتمالی، مانند انتشار و تقویت تعصبات ناعادلانه و محافظت هستیم. حریم خصوصی کاربر
پاک کردن کامل تأثیر دادههای درخواستی برای حذف چالش برانگیز است، زیرا به غیر از حذف ساده آنها از پایگاههای دادهای که در آن ذخیره میشوند، همچنین نیاز به پاک کردن تأثیر آن دادهها بر مصنوعات دیگر مانند مدلهای یادگیری ماشین آموزشدیده دارد. علاوه بر این، تحقیقات اخیر [1, 2] نشان داده است که در برخی موارد ممکن است بتوان با دقت بالا استنباط کرد که آیا از یک مثال برای آموزش مدل یادگیری ماشینی با استفاده از حملات استنتاج عضویت (MIA) استفاده شده است یا خیر. این میتواند نگرانیهایی را در مورد حفظ حریم خصوصی ایجاد کند، زیرا به این معنی است که حتی اگر دادههای یک فرد از پایگاه داده حذف شود، هنوز ممکن است بتوان استنباط کرد که آیا از دادههای آن فرد برای آموزش یک مدل استفاده شده است یا خیر.
با توجه به موارد فوق، یادگیری ماشینی یک زیرشاخه نوظهور از یادگیری ماشین است که هدف آن حذف تأثیر زیرمجموعه خاصی از نمونه های آموزشی – “مجموعه فراموش کردن” – از یک مدل آموزش دیده است. علاوه بر این، یک الگوریتم بیآموزشی ایدهآل تأثیر نمونههای خاص را حذف میکند در حین نگهداری سایر ویژگی های مفید، مانند دقت در بقیه مجموعه قطار و تعمیم به نمونه های نگه داشته شده. یک راه ساده برای تولید این مدل ناآموخته، آموزش مجدد مدل بر روی یک مجموعه آموزشی تنظیم شده است که نمونه ها را از مجموعه فراموشی حذف می کند. با این حال، این همیشه گزینه مناسبی نیست، زیرا بازآموزی مدل های عمیق می تواند از نظر محاسباتی گران باشد. یک الگوریتم بیآموزشی ایدهآل در عوض از مدل آموزشدیدهشده بهعنوان نقطه شروع استفاده میکند و بهطور مؤثر تنظیماتی را برای حذف تأثیر دادههای درخواستی انجام میدهد.
امروز با خوشحالی اعلام می کنیم که با گروه وسیعی از محققان دانشگاهی و صنعتی برای سازماندهی اولین چالش یادگیری ماشینی همکاری کرده ایم. این مسابقه یک سناریوی واقعی را در نظر می گیرد که در آن پس از آموزش، زیر مجموعه خاصی از تصاویر آموزشی باید فراموش شود تا از حریم خصوصی یا حقوق افراد مربوطه محافظت شود. مسابقه در Kaggle برگزار میشود و آثار ارسالی بهطور خودکار از نظر کیفیت فراموشی و کاربرد مدل امتیازدهی میشوند. ما امیدواریم که این مسابقه به پیشرفت هنر در یادگیری غیر یادگیری ماشینی کمک کند و توسعه الگوریتمهای یادگیری کارآمد، مؤثر و اخلاقی را تشویق کند.
برنامه های یادگیری ماشینی
لغو یادگیری ماشینی کاربردهایی فراتر از محافظت از حریم خصوصی کاربر دارد. برای مثال، میتوان از یادگیری نادرست برای پاک کردن اطلاعات نادرست یا قدیمی از مدلهای آموزشدیده (مثلاً به دلیل اشتباهات در برچسبگذاری یا تغییرات در محیط) استفاده کرد یا دادههای مضر، دستکاری شده یا پرت را حذف کرد.
زمینه یادگیری ماشینی با سایر زمینه های یادگیری ماشینی مانند حریم خصوصی متفاوت، یادگیری مادام العمر و عدالت مرتبط است. هدف حریم خصوصی متفاوت تضمین این است که هیچ نمونه آموزشی خاصی تأثیر زیادی بر مدل آموزش دیده نداشته باشد. هدفی قویتر در مقایسه با بیآموزی، که فقط نیازمند پاک کردن تأثیر مجموعه فراموشی تعیینشده است. هدف تحقیق یادگیری مادامالعمر طراحی مدلهایی است که میتوانند به طور مداوم یاد بگیرند و در عین حال مهارتهای قبلی را حفظ کنند. همانطور که کار بر روی عدم یادگیری پیشرفت میکند، ممکن است راههای بیشتری برای تقویت عدالت در مدلها، با اصلاح تعصبات ناعادلانه یا رفتار نامتجانس با اعضای متعلق به گروههای مختلف (مانند جمعیتشناسی، گروههای سنی و غیره) باز کند.
 |
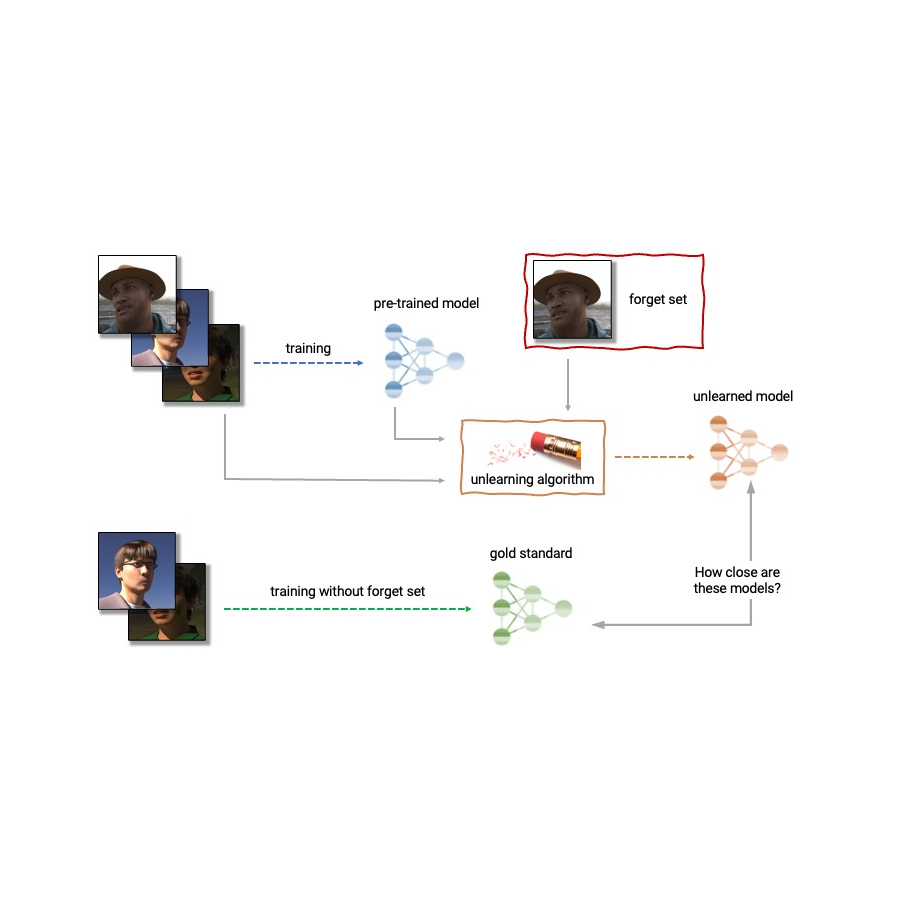
| آناتومی عدم یادگیری یک الگوریتم unlearning یک مدل از پیش آموزش دیده و یک یا چند نمونه از مجموعه قطار را به عنوان ورودی می گیرد تا آن را حذف کند (“مجموعه فراموشی”). از مدل، مجموعه فراموشی، و مجموعه حفظ، الگوریتم unlearning یک مدل به روز تولید می کند. یک الگوریتم بیآموزشی ایدهآل مدلی را تولید میکند که از مدل آموزشدیده بدون مجموعه فراموشی قابل تشخیص نیست. |
چالشهای یادگیری ماشینی
مشکل عدم یادگیری پیچیده و چند وجهی است زیرا شامل چندین هدف متناقض است: فراموش کردن دادههای درخواستی، حفظ مطلوبیت مدل (به عنوان مثال، دقت در دادههای حفظ شده و نگهداری شده)، و کارایی. به همین دلیل، الگوریتمهای unlearning موجود، مبادلات متفاوتی ایجاد میکنند. به عنوان مثال، بازآموزی کامل به فراموشی موفقیت آمیز بدون آسیب رساندن به کاربرد مدل، اما با کارایی ضعیف منجر می شود، در حالی که افزودن نویز به وزنه ها، فراموشی را به قیمت سودمندی به دست می آورد.
علاوه بر این، ارزیابی الگوریتم های فراموشی در ادبیات تاکنون بسیار ناسازگار بوده است. در حالی که برخی از کارها دقت طبقهبندی نمونهها را گزارش میکنند تا یاد نگیرند، برخی دیگر فاصله را تا مدل کاملاً بازآموزی شده گزارش میکنند و برخی دیگر از نرخ خطای حملات استنتاج عضویت به عنوان معیاری برای فراموش کردن کیفیت استفاده میکنند. [4, 5, 6].
ما معتقدیم که ناهماهنگی معیارهای ارزیابی و فقدان یک پروتکل استاندارد مانعی جدی برای پیشرفت در این زمینه است – ما قادر به مقایسه مستقیم بین روشهای مختلف بیآموزی در ادبیات نیستیم. این امر ما را با دیدی نزدیکبین از مزیتها و معایب نسبی رویکردهای مختلف، و همچنین چالشها و فرصتهای باز برای توسعه الگوریتمهای بهبودیافته، باز میکند. برای پرداختن به موضوع ارزیابی ناسازگار و برای پیشبرد وضعیت هنر در زمینه یادگیری غیرقابل یادگیری ماشینی، ما با گروه وسیعی از محققان دانشگاهی و صنعتی برای سازماندهی اولین چالش بیآموزشی همکاری کردهایم.
اعلام اولین چالش یادگیری ماشینی
ما خوشحالیم که اولین چالش Unlearning Machine را اعلام کنیم که به عنوان بخشی از مسیر مسابقه NeurIPS 2023 برگزار می شود. هدف این مسابقه دو چیز است. ابتدا، با یکسان سازی و استانداردسازی معیارهای ارزیابی برای یادگیری نادرست، امیدواریم بتوانیم نقاط قوت و ضعف الگوریتم های مختلف را از طریق مقایسه سیب به سیب شناسایی کنیم. دوم، با گشودن این رقابت برای همه، امیدواریم راهحلهای جدید را پرورش دهیم و چالشها و فرصتهای باز را روشن کنیم.
این مسابقه در Kaggle میزبانی خواهد شد و بین اواسط جولای 2023 تا اواسط سپتامبر 2023 برگزار خواهد شد. به عنوان بخشی از مسابقه، امروز در دسترس بودن کیت شروع را اعلام می کنیم. این کیت شروع پایهای را برای شرکتکنندگان فراهم میکند تا مدلهای ناآموخته خود را روی مجموعه دادههای اسباببازی بسازند و آزمایش کنند.
این مسابقه یک سناریوی واقع بینانه را در نظر می گیرد که در آن یک پیش بینی کننده سن بر روی تصاویر چهره آموزش دیده است، و پس از آموزش، زیر مجموعه خاصی از تصاویر آموزشی باید فراموش شود تا از حریم خصوصی یا حقوق افراد مربوطه محافظت شود. برای این کار، مجموعهای از چهرههای مصنوعی را به عنوان بخشی از کیت شروع در دسترس قرار میدهیم (نمونههایی که در زیر نشان داده شدهاند) و همچنین از چندین مجموعه داده واقعی برای ارزیابی ارسالها استفاده میکنیم. از شرکتکنندگان خواسته میشود کدی را ارسال کنند که پیشبینیکننده آموزشدیده، مجموعههای فراموش و حفظ را به عنوان ورودی میگیرد و وزنهای پیشبینیکنندهای را که مجموعه فراموشی تعیینشده را یاد نگرفته است، خروجی میدهد. ما موارد ارسالی را بر اساس قدرت الگوریتم فراموشی و کاربرد مدل ارزیابی خواهیم کرد. ما همچنین یک برش سخت را اعمال خواهیم کرد که الگوریتمهای بیآموزشی را که کندتر از کسری از زمان لازم برای آموزش مجدد اجرا میشوند، رد میکند. یک نتیجه ارزشمند از این رقابت، مشخص کردن مبادلات الگوریتمهای مختلف بیآموزی خواهد بود.
 |
| تصاویری را از مجموعه داده Face Synthetics همراه با حاشیه نویسی مربوط به سن استخراج کنید. این مسابقه سناریویی را در نظر می گیرد که در آن یک پیش بینی کننده سن بر روی تصاویر چهره مانند موارد فوق آموزش دیده است و پس از تمرین، زیر مجموعه خاصی از تصاویر تمرینی باید فراموش شود. |
برای ارزیابی فراموشی، از ابزارهای الهام گرفته از MIA مانند LiRA استفاده خواهیم کرد. MIAها ابتدا در ادبیات حریم خصوصی و امنیت توسعه یافتند و هدف آنها این است که استنباط کنند کدام نمونه بخشی از مجموعه آموزشی است. بطور شهودی، در صورت موفقیتآمیز بودن یادگیری، مدل آموختهنشده هیچ اثری از نمونههای فراموششده را در بر نمیگیرد و باعث شکست MIA میشود: مهاجم ممکن است قادر نیست استنباط کنیم که مجموعه فراموشی در واقع بخشی از مجموعه آموزشی اصلی است. علاوه بر این، ما همچنین از آزمونهای آماری برای تعیین کمیت تفاوت توزیع مدلهای ناآموخته (تولید شده توسط یک الگوریتم بیآموزشی خاص) در مقایسه با توزیع مدلهای بازآموزی شده از ابتدا استفاده خواهیم کرد. برای یک الگوریتم یادگیری ایده آل، این دو قابل تشخیص نیستند.
نتیجه
یادگیری ماشینی یک ابزار قدرتمند است که پتانسیل رفع چندین مشکل باز در یادگیری ماشین را دارد. با ادامه تحقیقات در این زمینه، امیدواریم شاهد روش های جدیدی باشیم که کارآمدتر، موثرتر و مسئولیت پذیرتر باشند. ما خوشحالیم که از طریق این مسابقه فرصتی برای ایجاد علاقه در این زمینه داریم و مشتاقانه منتظر به اشتراک گذاشتن بینش و یافته های خود با جامعه هستیم.
سپاسگزاریها
نویسندگان این پست اکنون بخشی از Google DeepMind هستند. ما این پست وبلاگ را از طرف النی تریانتافیلو*، فابیان پدرگوسا* (* مشارکت برابر)، مقداد کورمانجی، کایران ژائو، گینتار کارولینا دزیوگایت، پیتر تریانتافیلو، یوآنیس میتلیاگاس، وینسنت دومولین، لیشنگ سان هوسویا، پیترلیوس، می نویسیم. جیمز جونیور، جون وان، سرجیو اسکالرا و ایزابل گیون.