ترکیبی از محیطی که یک فرد تجربه می کند و استعدادهای ژنتیکی آنها بیشتر خطر ابتلا به بیماری های مختلف را تعیین می کند. تلاشهای بزرگ ملی، مانند Biobank بریتانیا، منابع عمومی و بزرگی را برای درک بهتر پیوندهای بین محیط، ژنتیک و بیماری ایجاد کرده است. این پتانسیل کمک به افراد برای درک بهتر نحوه حفظ سلامت، پزشکان برای درمان بیماری ها و دانشمندان برای توسعه داروهای جدید است.
یکی از چالشهای این فرآیند این است که چگونه ما حجم وسیع اندازهگیریهای بالینی را درک میکنیم – بیوبانک بریتانیا دارای پتابایتهای بسیاری از تصویربرداری، آزمایشهای متابولیک و سوابق پزشکی است که شامل 500000 فرد میشود. برای استفاده بهینه از این دادهها، باید بتوانیم اطلاعات موجود را بهعنوان برچسبهای مختصر و آموزنده در مورد بیماریها و صفات معنیدار نمایش دهیم، فرآیندی که فنوتیپسازی نامیده میشود. اینجاست که ما میتوانیم از توانایی مدلهای ML برای دریافت الگوهای پیچیده ظریف در مقادیر زیاد داده استفاده کنیم.
ما قبلاً توانایی استفاده از مدلهای ML را برای فنوتیپ سریع در مقیاس بیماریهای شبکیه نشان دادهایم. با این وجود، این مدلها با استفاده از برچسبهای قضاوت بالینی آموزش داده شدند و دسترسی به برچسبهای درجه بالینی به دلیل زمان و هزینهای که برای ایجاد آنها نیاز است، یک عامل محدودکننده است.
در “استنتاج بیماری انسدادی مزمن ریه با یادگیری عمیق بر روی اسپیروگرام های خام، جایگاه های ژنتیکی جدید را شناسایی می کند و مدل های خطر را بهبود می بخشد” منتشر شده در ژنتیک طبیعت، ما هیجان زده هستیم که روشی را برای آموزش مدل های دقیق ML برای کشف ژنتیکی بیماری ها، حتی در هنگام استفاده از برچسب های پر سر و صدا و غیر قابل اعتماد، برجسته کنیم. ما توانایی آموزش مدلهای ML را نشان میدهیم که میتوانند مستقیماً از اندازهگیری بالینی خام و اطلاعات سوابق پزشکی غیرقابل اعتماد فنوتیپ کنند. این کاهش اتکا به متخصصان حوزه پزشکی برای برچسبگذاری، دامنه کاربردهای تکنیک ما را به طیف وسیعی از بیماریها گسترش میدهد و پتانسیل بهبود پیشگیری، تشخیص و درمان آنها را دارد. ما این روش را با مدلهای ML نشان میدهیم که میتواند عملکرد ریه و بیماری مزمن انسدادی ریه (COPD) را بهتر مشخص کند. علاوه بر این، ما سودمندی این مدلها را با نشان دادن توانایی بهتر برای شناسایی انواع ژنتیکی مرتبط با COPD، درک بهتر زیستشناسی پشت این بیماری و پیشبینی موفقیتآمیز پیامدهای مرتبط با COPD نشان میدهیم.
ML برای درک عمیق تر بازدم
برای این نمایش، ما بر COPD، سومین علت اصلی مرگ و میر در سراسر جهان در سال 2019 تمرکز کردیم، که در آن التهاب راههای هوایی و اختلال در جریان هوا میتواند به تدریج عملکرد ریه را کاهش دهد. عملکرد ریه برای COPD و سایر بیماریها با ثبت حجم بازدم فرد در طول زمان اندازهگیری میشود (این رکورد اسپیروگرام نامیده میشود؛ مثال زیر را ببینید). اگرچه دستورالعمل هایی (به نام GOLD) برای تعیین وضعیت COPD از بازدم وجود دارد، اما این دستورالعمل ها فقط از چند نقطه داده خاص در منحنی استفاده می کنند و آستانه های ثابتی را برای آن مقادیر اعمال می کنند. بسیاری از داده های غنی از این اسپیروگرام ها در این تجزیه و تحلیل عملکرد ریه کنار گذاشته شده است.
ما استدلال کردیم که مدلهای ML که برای طبقهبندی اسپیروگرامها آموزش دیدهاند، میتوانند از دادههای غنی موجود بهطور کاملتر استفاده کنند و به اندازهگیریهای دقیقتر و جامعتری از عملکرد و بیماری ریه منجر شوند، مشابه آنچه در سایر کارهای طبقهبندی مانند ماموگرافی یا بافتشناسی دیدهایم. ما مدلهای ML را آموزش دادیم تا با استفاده از اسپیروگرامهای کامل به عنوان ورودی، پیشبینی کنیم که آیا یک فرد مبتلا به COPD است یا خیر.
 |
| بررسی اجمالی وضعیت اسپیرومتری و COPD اسپیروگرام از تست عملکرد ریه که اسپیروگرام حجم-زمان بازدم اجباری را نشان می دهد (ترک کرد، یک اسپیروگرام جریان بازدم اجباری (وسطو یک اسپیروگرام جریان-حجم بازدمی درون یابی شده (درست). مشخصات افراد بدون COPD متفاوت است. |
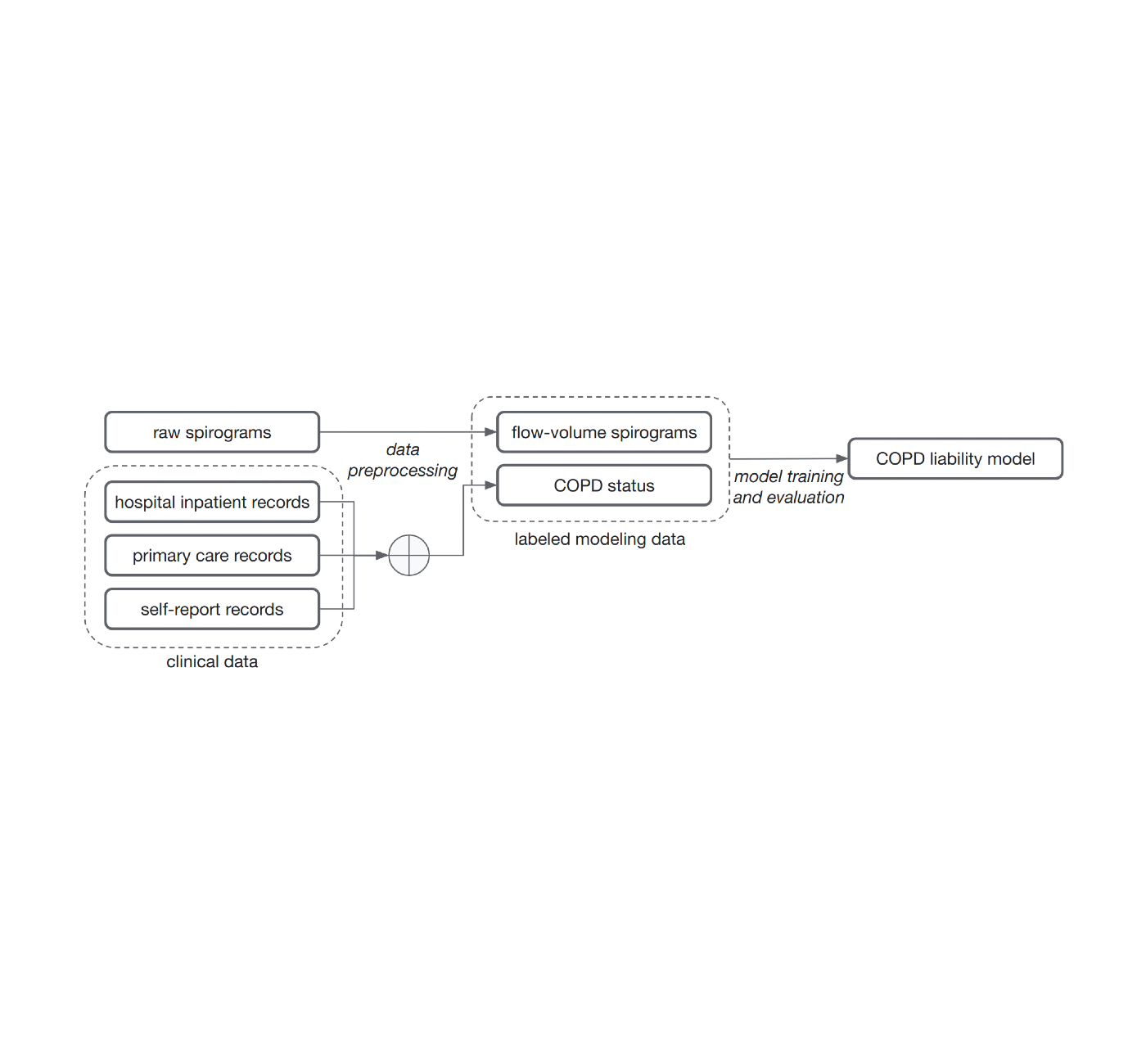
روش متداول مدلهای آموزشی برای این مشکل، یادگیری تحت نظارت، نیاز به نمونهها با برچسبها دارد. تعیین آن برچسب ها می تواند به تلاش متخصصان بسیار محدود نیاز داشته باشد. برای این کار، برای اینکه نشان دهیم لزوماً نیازی به برچسبهای درجهبندی شده پزشکی نداریم، تصمیم گرفتیم از منابع متنوعی از اطلاعات پرونده پزشکی در دسترس برای ایجاد آن برچسبها بدون بررسی متخصص پزشکی استفاده کنیم. این برچسب ها به دو دلیل کمتر قابل اعتماد و نویز هستند. اولاً، شکاف هایی در پرونده پزشکی افراد وجود دارد، زیرا آنها از خدمات بهداشتی متعدد استفاده می کنند. دوم، COPD اغلب تشخیص داده نمی شود، به این معنی که بسیاری از مبتلایان به این بیماری حتی اگر سوابق پزشکی کامل را جمع آوری کنیم، برچسب مبتلا به آن نخواهند داشت. با این وجود، ما مدلی را آموزش دادیم تا این برچسبهای پر سر و صدا را از روی منحنیهای اسپیروگرام پیشبینی کند و با پیشبینیهای مدل بهعنوان یک بدهی کمی COPD یا امتیاز ریسک رفتار کنیم.
 |
| برچسب های وضعیت COPD پر سر و صدا با استفاده از منابع مختلف پرونده پزشکی (داده های بالینی) به دست آمد. سپس یک مدل مسئولیت COPD برای پیشبینی وضعیت COPD از اسپیروگرامهای حجم جریان خام آموزش داده میشود. |
پیش بینی نتایج COPD
سپس بررسی کردیم که آیا نمرات خطر تولید شده توسط مدل ما میتواند انواع پیامدهای COPD دوتایی را بهتر پیشبینی کند (به عنوان مثال، وضعیت COPD یک فرد، اینکه آیا به دلیل COPD در بیمارستان بستری شدهاند یا بر اثر آن فوت کردهاند). برای مقایسه، ما مدل را نسبت به اندازهگیریهای تعریف شده توسط متخصص مورد نیاز برای تشخیص COPD، بهویژه FEV1/FVC، که نقاط خاص روی منحنی اسپیروگرام را با یک نسبت ریاضی ساده مقایسه میکند، محک زدیم. ما بهبودی را در توانایی پیشبینی این نتایج مشاهده کردیم، همانطور که در منحنیهای فراخوان دقیق زیر مشاهده میشود.
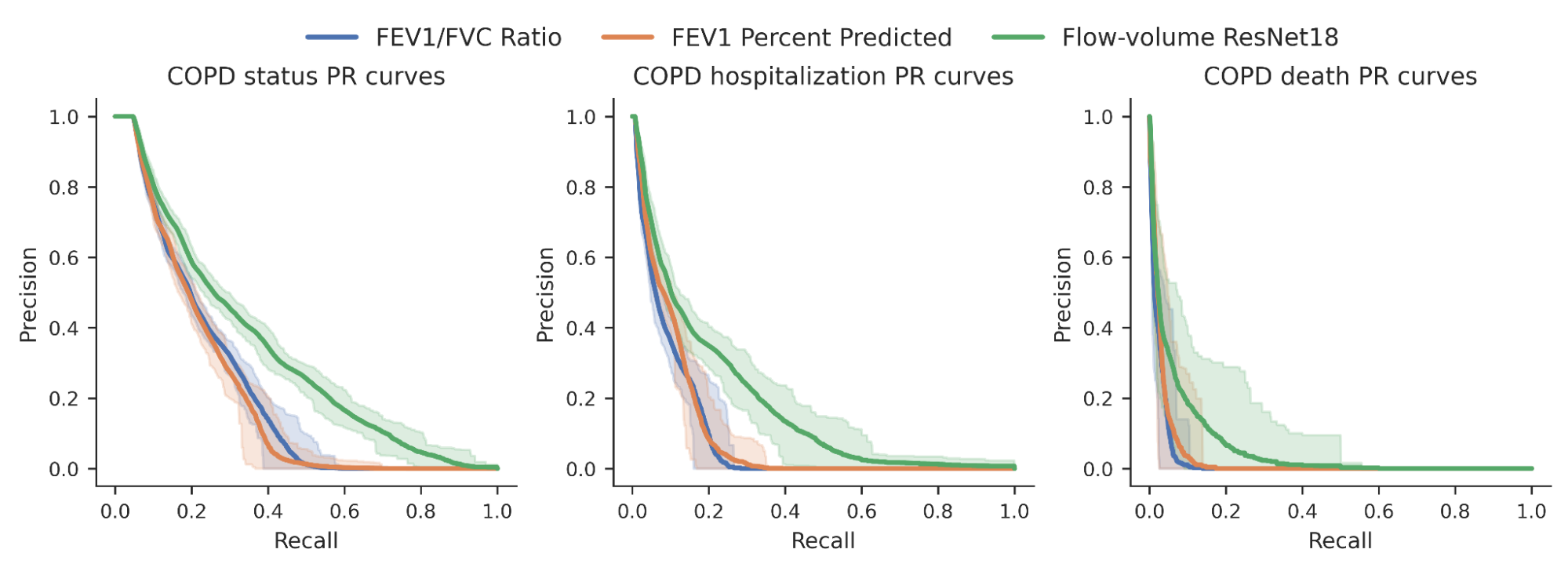 |
| منحنیهای فراخوان دقیق برای وضعیت COPD و نتایج برای مدل ML ما (سبز) در مقایسه با معیارهای سنتی. فواصل اطمینان با سایه روشن تر نشان داده می شود. |
ما همچنین مشاهده کردیم که جداسازی جمعیتها با امتیاز مدل COPD آنها، مرگ و میر ناشی از همه علل را پیشبینی میکند. این طرح نشان می دهد که افراد با خطر COPD بالاتر احتمال دارد به هر علتی زودتر بمیرند و این خطر احتمالاً پیامدهایی فراتر از COPD دارد.
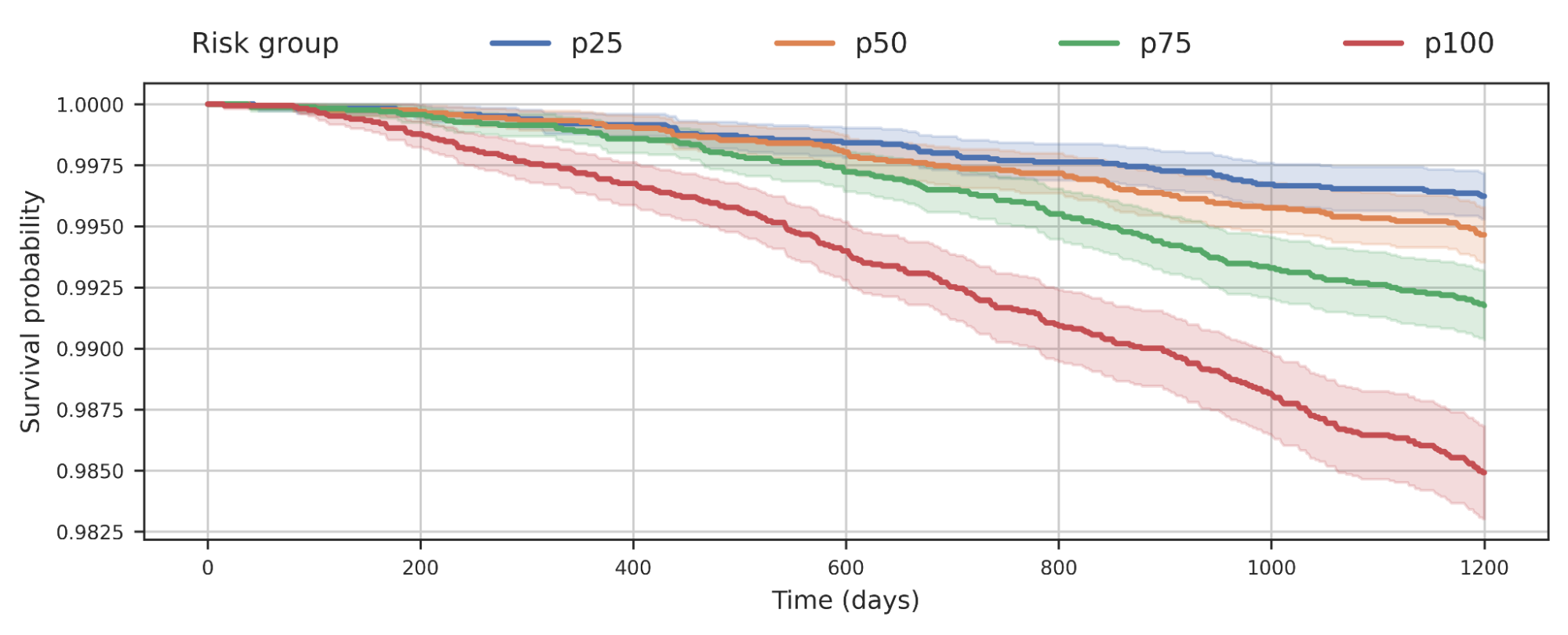 |
| تجزیه و تحلیل بقای گروهی از افراد Biobank بریتانیا که براساس چارک خطر پیشبینیشده مدل COPD طبقهبندی شدهاند. کاهش منحنی نشان می دهد که افراد در گروه در طول زمان می میرند. به عنوان مثال، p100 نشان دهنده 25٪ از گروه با بیشترین خطر پیش بینی شده است، در حالی که p50 نشان دهنده چارک دوم است. |
شناسایی پیوندهای ژنتیکی با COPD
از آنجایی که هدف بانکهای زیستی در مقیاس بزرگ گردآوری مقادیر زیادی از دادههای فنوتیپی و ژنتیکی است، ما همچنین آزمایشی به نام مطالعه انجمن گسترده ژنوم (GWAS) برای شناسایی پیوندهای ژنتیکی با COPD و استعداد ژنتیکی انجام دادیم. یک GWAS قدرت ارتباط آماری بین یک نوع ژنتیکی معین – تغییر در یک موقعیت خاص DNA – و مشاهدات (مثلا COPD) را در میان گروهی از موارد و گروههای کنترل اندازهگیری میکند. پیوندهای ژنتیکی که به این روش کشف میشوند میتوانند به توسعه دارویی که فعالیت یا محصولات یک ژن را تغییر میدهند، و همچنین درک ما از زیستشناسی یک بیماری را گسترش دهند.
ما با روش فنوتایپینگ ML خود نشان دادیم که نه تنها تقریباً همه انواع شناخته شده COPD که با فنوتیپ دستی یافت می شوند را دوباره کشف می کنیم، بلکه بسیاری از گونه های ژنتیکی جدید را نیز می یابیم که به طور قابل توجهی با COPD مرتبط هستند. علاوه بر این، ما توافق خوبی را در مورد اندازه اثر برای انواع کشف شده توسط هر دو روش ML ما و روش دستی مشاهده می کنیم (R2= 0.93)، که شواهد قوی برای اعتبار انواع تازه یافت شده ارائه می دهد.
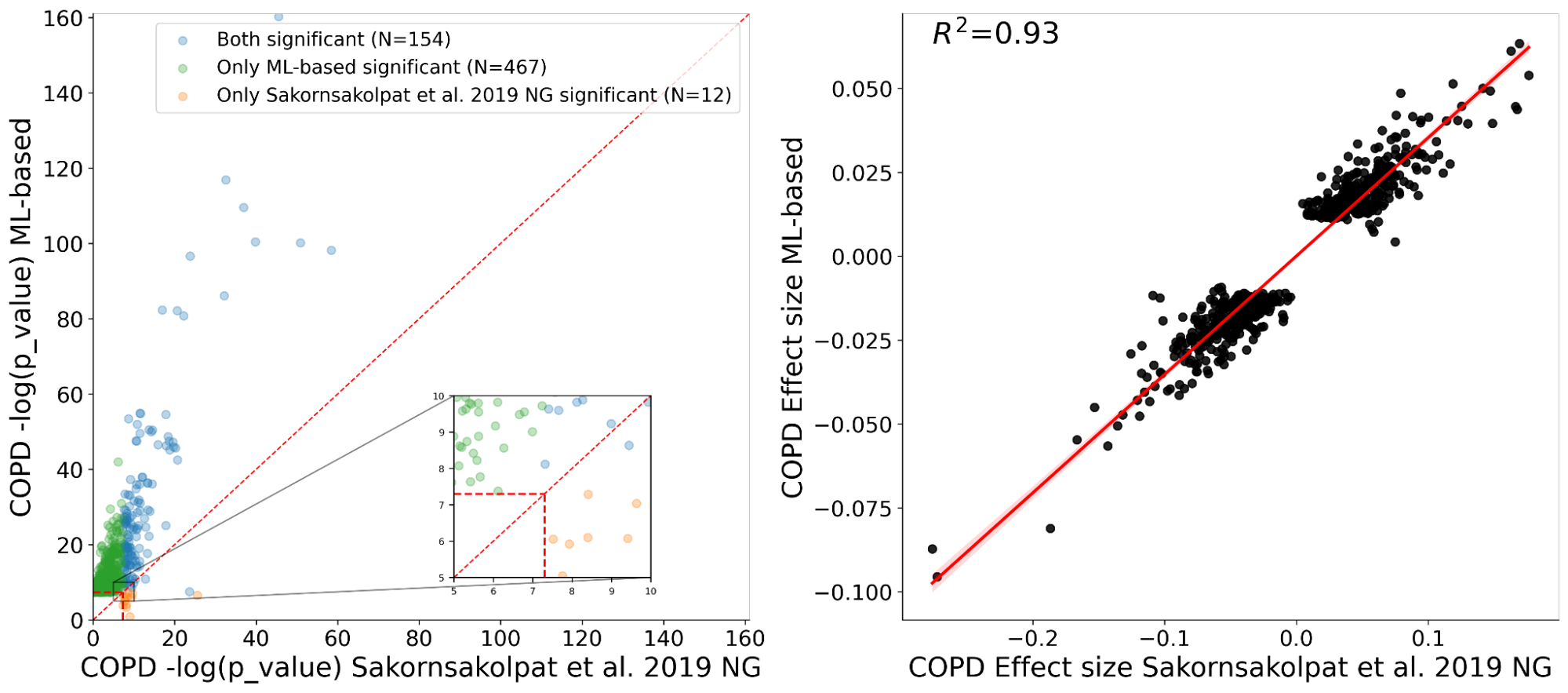 |
| ترک کرد: نمودار مقایسه قدرت آماری کشف ژنتیکی با استفاده از برچسب ها برای مدل ML ما (محور y) با توان آماری از برچسب های دستی از یک مطالعه سنتی (ایکس-محور). مقدار بالاتر از y = ایکس خط نشان دهنده قدرت آماری بیشتر در روش ما است. نقاط سبز نشان دهنده یافته های قابل توجهی در روش ما است که با استفاده از رویکرد سنتی یافت نمی شوند. نقاط نارنجی در رویکرد سنتی قابل توجه است اما در رویکرد ما نه. نقاط آبی در هر دو قابل توجه است. درست: برآورد اثر ارتباط بین روش ما (yمحور) و روش سنتی (ایکس-محور). توجه داشته باشید که مقادیر نسبی بین مطالعات قابل مقایسه هستند اما اعداد مطلق قابل مقایسه نیستند. |
در نهایت، همکاران ما در دانشکده پزشکی هاروارد و بریگهام و بیمارستان زنان، با ارائه بینشهایی در مورد نقش بیولوژیکی احتمالی انواع جدید در توسعه و پیشرفت COPD، بیشتر قابل قبول بودن این یافتهها را بررسی کردند (شما میتوانید بحث بیشتر در مورد این بینشها را در مقاله ببینید. ).
نتیجه
ما نشان دادیم که روشهای قبلی ما برای فنوتیپ کردن با ML را میتوان به طیف وسیعی از بیماریها گسترش داد و میتواند بینشهای جدید و ارزشمندی را ارائه دهد. ما دو مشاهدات کلیدی را با استفاده از آن برای پیشبینی COPD از اسپیروگرامها و کشف بینشهای ژنتیکی جدید انجام دادیم. اول، دانش دامنه برای پیشبینی از دادههای خام پزشکی ضروری نبود. جالب توجه است، ما نشان دادیم که دادههای پزشکی خام احتمالاً مورد استفاده قرار نمیگیرند و مدل ML میتواند الگوهایی را در آن بیابد که توسط اندازهگیریهای تعریفشده توسط متخصص ثبت نشدهاند. دوم، ما نیازی به برچسب های درجه بندی پزشکی نداریم. در عوض، برچسب های پر سر و صدا تعریف شده از سوابق پزشکی به طور گسترده در دسترس می توانند برای ایجاد امتیاز خطر بالینی پیش بینی کننده و ژنتیکی مورد استفاده قرار گیرند. ما امیدواریم که این کار به طور گسترده توانایی این زمینه را برای استفاده از برچسب های پر سر و صدا گسترش دهد و درک جمعی ما از عملکرد و بیماری ریه را بهبود بخشد.
قدردانی
این کار خروجی ترکیبی از چندین مشارکت کننده و مؤسسه است. ما از همه مشارکت کنندگان: جاستین کوسنتینو، بابک علی پناهی، زکری آر. مککاو، کوری وای مکلین، فرهاد هرمزدیاری (گوگل)، داوین هیل (دانشگاه شمال شرقی)، تائه هوی شوانتز-آن و دانگبینگ لای (دانشگاه ایندیانا)، برایان دی تشکر میکنیم. هابز و مایکل اچ چو (بیمارستان زنان و بریگام و دانشکده پزشکی هاروارد). ما همچنین از تد یون و نیک فورولوت برای بررسی نسخه خطی، گرگ کورادو و شراویا شتی برای حمایت، و هوارد یانگ، کاویتا کولکارنی و تامی هوین برای کمک به تدارکات انتشارات تشکر می کنیم.