بهینه سازی موتور جستجو (SEO) برای هر وب سایتی که امیدوار است در صفحات نتایج موتورهای جستجو (SERP) رتبه خوبی داشته باشد، حیاتی است. یکی از راههای بهبود سئو، استفاده از تکنیکهای یادگیری ماشینی برای تجزیه و تحلیل دادهها و شناسایی بهترین کلمات کلیدی و استراتژیها برای کمک به شما در رتبهبندی بالاتر در گوگل است.
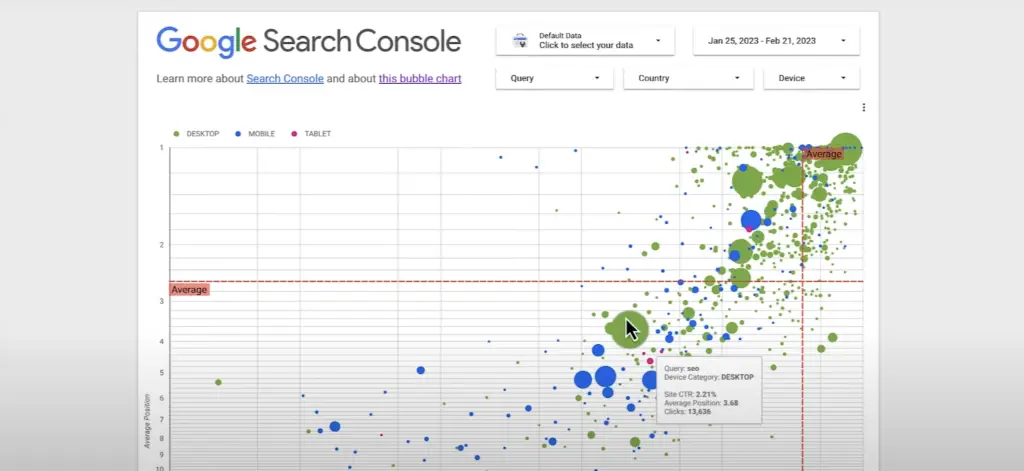
در یکی از قسمتهای آموزش جستجوی Google، دانیل ویزبرگ نحوه استفاده از نمودارهای حبابی را برای تجزیه و تحلیل دادههای عملکرد جستجو با Looker نشان میدهد.

نمودارهای حبابی یکی از مؤثرترین راه ها برای به دست آوردن بینش در مورد معیارها و ابعاد متعدد به طور همزمان است.
در این آموزش، ما به شما نشان می دهیم که چگونه نمودار حباب سه بعدی خود را از داده های کنسول جستجوی گوگل با Python و Plotly Express بسازید.

آنها به شناسایی الگوها و همبستگی ها در داده های شما و بهینه سازی پرس و جوهای شما کمک می کنند. در این ویدئو، نحوه تفسیر کلیک ها، نرخ کلیک و موقعیت متوسط برای دستگاه ها و پرس و جوهای مختلف را با استفاده از کنسول جستجو برای بهبود عملکرد وب سایت خود خواهید آموخت.
چه مبتدی و چه متخصص، تماشای این ویدیو برای هر کسی که علاقه مند به بهینه سازی سئوی وب سایت خود است، ضروری است.
خوشبختانه پایتون دارای کتابخانه های قوی مانند پانداها، scikit-learn و plotly.express است که ساخت مدل های یادگیری ماشین و تجسم داده ها را آسان می کند.
در این پست به شما نشان خواهیم داد که چگونه از این ابزارها برای ایجاد یک اسکریپت SEO استفاده کنید که می تواند به شما در بهینه سازی سایت و بهبود رتبه بندی SERP کمک کند.
اسکریپت پایتون برای ایجاد نمودار حباب از داده های GSC
کد زیر نحوه استفاده از کتابخانههای مختلف پایتون مانند پانداها، scikit-learn و plotly.express را برای ایجاد یک مدل یادگیری ماشین، پیشبینی و تجسم دادهها نشان میدهد.
import pandas as pd
import plotly.express as px
from sklearn.linear_model import LinearRegression
from sklearn.ensemble import RandomForestRegressor
from sklearn.neural_network import MLPRegressor
# Read data from CSV file
df = pd.read_csv("random-Queries.csv")
# Select the regression model (change the value of 'model_type' to use a different model)
model_type = 'neural_network'
if model_type == 'linear_regression':
model = LinearRegression()
elif model_type == 'random_forest':
model = RandomForestRegressor(n_estimators=100)
elif model_type == 'neural_network':
model = MLPRegressor(hidden_layer_sizes=(10,), activation='relu', solver='adam')
# Create a linear regression model using Clicks, CTR, Average Position, and Impressions to predict bubble potential
X = df[['CTR', 'Position', 'Impressions']]
y = df['Clicks']
model.fit(X, y)
# Make predictions on Clicks using the newly created model
df['prediction_Clicks'] = model.predict(X)
# Sort the bubbles based on predicted Clicks to identify those with the highest potential
df = df.sort_values(by=['prediction_Clicks'], ascending=True)
# Export the data to a new CSV file
df.to_csv('new_file.csv', index=False)
# Set negative values of the 'predicted_Clicks' object to zero (uncomment if the error occurs)
df.loc[df['prediction_Clicks'] < 0, 'prediction_Clicks'] = 0
# Create a 3D scatter plot with Plotly showing the Clicks predicted by the model
fig = px.scatter_3d(df, x="CTR", y="Position", z="Impressions", size="prediction_Clicks", hover_name="Top queries")
# Add the regression line to the plot
x_fit = [min(df['CTR']), max(df['CTR'])]
y_fit = [min(df['Position']), max(df['Position'])]
z_fit = [min(df['Impressions']), max(df['Impressions'])]
xyz_fit = pd.DataFrame({'CTR': x_fit, 'Position': y_fit, 'Impressions': z_fit})
df['prediction_Clicks'] = model.predict(X)
fig.add_trace(px.line_3d(xyz_fit, x=x_fit, y=y_fit, z=z_fit).data[0])
# Show the interactive plot
fig.show()
کد منبع
دستورالعمل استفاده
- CSV را با پرس و جوهایی که قرار است از کنسول جستجوی Google تجزیه و تحلیل شوند، صادر کنید یا با استفاده از Google Search Console API استخراج کنید.
- در CSV، ستون «CTR» را از فرمت % به قالب «تعداد» تغییر دهید.
- فایل را در این نوت بوک به Google Colab وارد کنید.
- رشته با نام فایل را به csv تغییر دهید.
- یکی از سه مدل یادگیری ماشینی را انتخاب کرده و در model_type قرار دهید.
- اسکریپت را اجرا کنید.
- اسکریپت یک CSV جدید با یک ستون اضافی که توسط مقادیر پیشبینیشده در مقایسه با فایل اصلی ارائه میشود، ایجاد میکند.
نمونه فایل CSV

مدل های یادگیری ماشینی مورد استفاده
- رگرسیون خطی: یک تکنیک تحلیلی است که برای تجزیه و تحلیل رابطه بین دو یا چند متغیر استفاده می شود. همیشه نمی توان رابطه بین متغیرها را به صورت گرافیکی نشان داد، اما اگر متغیرها عددی باشند، می توان یک نمودار پراکنده برای تجسم رابطه ترسیم کرد.
- جنگل تصادفی: جنگل تصادفی مجموعه ای از درختان تصمیم گیری مستقل است. نتایج تک تک درختان برای تولید یک پیشبینی نهایی ترکیب میشوند.
- شبکه های عصبی: شبکه های عصبی یک مدل یادگیری ماشینی بسیار پیچیده هستند که از عملکرد مغز انسان الهام گرفته شده است. شبکه های عصبی برای طبقه بندی، رگرسیون و بسیاری دیگر از فعالیت های یادگیری ماشین استفاده می شوند.
چگونه کار می کند
این اسکریپت از یک مدل رگرسیون شبکه عصبی برای پیشبینی پتانسیل حباب بر اساس کلیکها، CTR، موقعیت متوسط و برداشتها استفاده میکند. سپس داده ها را مرتب می کند تا پرس و جوهایی را با بالاترین پتانسیل شناسایی کند و آن را به یک فایل CSV صادر می کند.
در اینجا توضیح مختصری از کاری که کد انجام می دهد آورده شده است:
- اول، از pandas برای خواندن داده ها از یک فایل CSV که شامل پرس و جوهای تصادفی است استفاده می شود.
- سپس یک مدل رگرسیونی با تنظیم مقدار model_type انتخاب می شود. این را می توان برای استفاده از یک مدل متفاوت، مانند رگرسیون خطی یا جنگل تصادفی تغییر داد.
- سپس مدل MLPRegressor با استفاده از ویژگیهای CTR، Position و Impressions روی دادهها آموزش داده میشود تا پتانسیل حباب را بر اساس کلیکها پیشبینی کند.
- پیشبینیها برای کلیکها با استفاده از مدل آموزشدیده انجام میشوند و به ترتیب صعودی مرتب میشوند تا جستجوهایی با بالاترین پتانسیل شناسایی شوند.
- داده ها با استفاده از پانداها به یک فایل CSV جدید صادر می شوند.
- مقادیر منفی در شیء ‘predicted_Clicks’ روی صفر تنظیم شده است (اگر خطا رخ داد، اظهار نظر نکنید)، تا از پیش بینی های منفی جلوگیری شود.
- در نهایت، Plotly برای ایجاد یک نمودار پراکندگی سه بعدی تعاملی که تعداد کلیک های پیش بینی شده برای هر پرس و جو را بر اساس پیش بینی های مدل نشان می دهد، استفاده می شود. یک خط رگرسیون نیز به طرح اضافه شده است.
به طور کلی، این کد قدرت و انعطاف پذیری پایتون و کتابخانه های مختلف آن را برای تجزیه و تحلیل داده ها و یادگیری ماشین نشان می دهد. با استفاده از پایتون در ارتباط با این کتابخانه ها، می توان به سرعت و کارآمد راه حل هایی برای مسائل پیچیده ایجاد کرد و نتایج را به روشی معنادار و تعاملی تجسم کرد.
طرح پراکندگی سه بعدی تعاملی با Plotly
اما این همه ماجرا نیست! این اسکریپت همچنین یک نمودار پراکنده سه بعدی تعاملی با Plotly ایجاد می کند که تعداد کلیک های پیش بینی شده برای هر پرس و جو را بر اساس پیش بینی های مدل نشان می دهد. یک خط رگرسیون نیز به طرح اضافه شده است، که به راحتی می توانید رتبه بندی های پیش بینی شده خود را تجسم کنید.
با استفاده از این اسکریپت، می توانید بهترین کلمات کلیدی را برای وب سایت خود شناسایی کنید و محتوایی ایجاد کنید که برای آن کلمات کلیدی بهینه شده باشد. این می تواند به شما کمک کند رتبه بالاتری در SERP داشته باشید و در نهایت ترافیک بیشتری را به سایت خود هدایت کنید.
به طور خلاصه
در پایان، استفاده از یادگیری ماشین و کتابخانه های پایتون مانند پانداها، scikit-learn و plotly.express می تواند ابزار قدرتمندی برای بهبود سئوی شما باشد. با ایجاد یک مدل رگرسیون و تجسم داده های خود با نمودار، می توانید بهترین کلمات کلیدی و استراتژی ها را برای بهینه سازی سایت خود برای رتبه بالاتر در SERP شناسایی کنید. امروز آن را امتحان کنید و ببینید چقدر ترافیک بیشتری می توانید به سایت خود برسانید!

متخصص SEO برای مهمان نوازی لوکس، من عاشق تحقیق و تجزیه و تحلیل به اندازه یک ویسکی اسکاچ خوب، بازی شطرنج و زندگی با موسیقی هستم.