تجسم داده ها برای تجزیه و تحلیل داده ها حیاتی است. بدون آن، به اشتراک گذاشتن بینش در مورد داده های خود چالش برانگیز و یا حتی گاهی غیرممکن است. در این آموزش، ما با محبوب ترین کتابخانه های پایتون برای تجسم داده ها آشنا می شویم: Matplotlib، Seaborn و Plotly.
اگر بخشی اساسی از فرآیند علم داده است. هیچ مدل جدی یادگیری ماشینی بدون تجسم داده ساخته نشده است.
محبوب ترین کتابخانه های تجسم داده
قبل از اینکه به ایجاد تجسم ها بپردازیم، بیایید کتابخانه های مختلفی را که از آنها استفاده خواهیم کرد، بحث کنیم.
Matplotlib
Matplotlib پرکاربردترین کتابخانه برای تجسم داده ها در پایتون است. طیف گسترده ای از نمودارها، از جمله نمودارهای خطی، نمودارهای پراکنده، نمودارهای نواری و هیستوگرام را ارائه می دهد.
متولد دریا
متولد دریا یک کتابخانه تجسم داده در پایتون است که بر روی بسته Matplotlib ساخته شده است. این توابع بصری را برای کمک به حل اکثر مشکلاتی که سایر کتابخانه ها با آن مواجه می شوند به ارمغان می آورد.
توطئه
توطئه یک کتابخانه تجسم داده های تعاملی است. نه تنها تجسم های آن زیباتر از Matplotlib و Seaborn هستند، بلکه می توانید با آنها تعامل داشته باشید. با Plotly می توانید نمودارهای مختلفی مانند نمودارهای پراکنده، نمودارهای خطی، نمودارهای نواری و غیره ایجاد کنید.
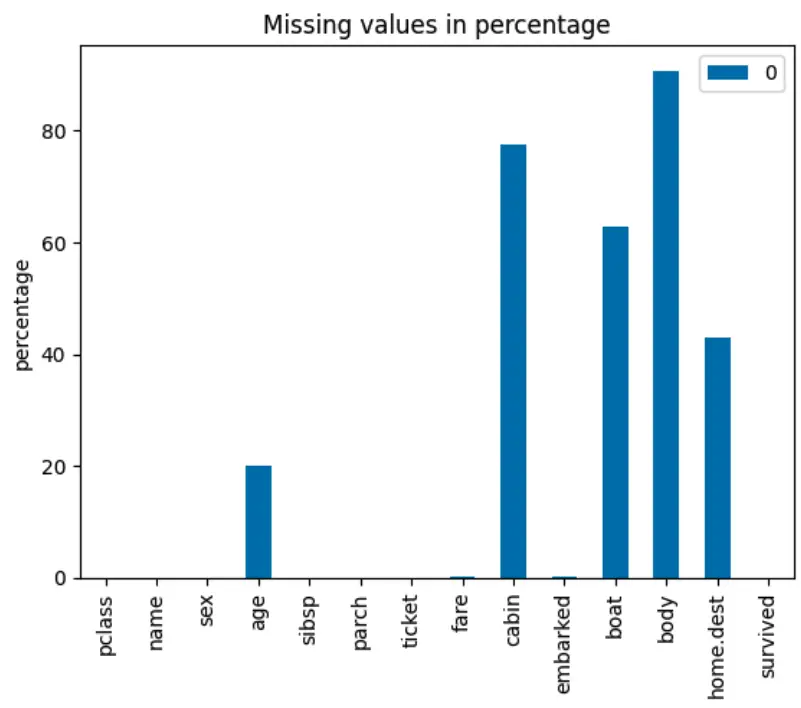
نمونه ای از تجسم Matplotlib در پایتون
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.datasets import fetch_openml
# load dataset
titanic = fetch_openml('titanic', version=1, as_frame=True)
df = titanic['data']
df['survived'] = titanic['target']
miss_vals = pd.DataFrame(df.isnull().sum() / len(df) * 100)
miss_vals.plot(kind='bar',
title='Missing values in percentage',
ylabel='percentage'
)
plt.show()

نمونه ای از تجسم Seaborn در پایتون
در Seaborn میتوانید تجسمهایی مانند countplot ایجاد کنید.
import seaborn as sns
import matplotlib.pyplot as plt
colors = ['Blue','Blue','Red','Red','Red','Yellow','Yellow','Yellow','Yellow','Yellow']
sns.countplot(x=colors)
plt.show()

نمونه ای از تجسم Plotly در پایتون
import plotly.express as px
import pandas as pd
# Load the dataset (in this case, the Iris dataset from seaborn)
iris_df = pd.read_csv('https://raw.githubusercontent.com/mwaskom/seaborn-data/master/iris.csv')
# Create a scatter plot using Plotly Express
fig = px.scatter(iris_df, x='sepal_length', y='sepal_width', color='species')
# Set the title and axis labels
fig.update_layout(title='Sepal Length vs. Sepal Width', xaxis_title='Sepal Length', yaxis_title='Sepal Width')
# Show the plot
fig.show()

مقالات پایتون با استفاده از تجسم داده ها

استراتژیست سئو در Tripadvisor، Seek سابق (ملبورن، استرالیا). متخصص در سئو فنی. در تلاش برای سئوی برنامهریزی شده برای سازمانهای بزرگ از طریق استفاده از پایتون، R و یادگیری ماشین.