
هر بایت و هر عملیاتی هنگام تلاش برای ساختن یک مدل سریعتر اهمیت دارد، بهویژه اگر مدل روی دستگاه اجرا شود. الگوریتمهای جستجوی معماری عصبی (NAS) معماریهای مدل پیچیدهای را با جستجو در یک فضای مدل بزرگتر از آنچه به صورت دستی امکانپذیر است، طراحی میکنند. الگوریتمهای مختلف NAS، مانند MNasNet و TuNAS، پیشنهاد شدهاند و چندین معماری مدل کارآمد از جمله MobileNetV3، EfficientNet را کشف کردهاند.
در اینجا ما LayerNAS را ارائه میدهیم، رویکردی که مسئله NAS چند هدفه را در چارچوب بهینهسازی ترکیبی مجدداً فرموله میکند تا پیچیدگی را تا حد زیادی کاهش دهد، که منجر به کاهش مرتبهای در تعداد مدلهایی که باید جستجو شوند، محاسبات کمتری لازم است. جستجوهای چند آزمایشی و کشف معماریهای مدلی که عملکرد کلی بهتری دارند. با استفاده از فضای جستجوی ساخته شده بر روی ستون فقرات گرفته شده از MobileNetV2 و MobileNetV3، مدل هایی را با دقت بالای 1 در ImageNet تا 4.9٪ بهتر از جایگزین های پیشرفته فعلی می یابیم.
فرمول مسأله
NAS با انواع مشکلات مختلف در فضاهای جستجوی مختلف مقابله می کند. برای اینکه بفهمیم LayerNAS چه چیزی را حل می کند، اجازه دهید با یک مثال ساده شروع کنیم: شما صاحب GBurger هستید و در حال طراحی برگر پرچمدار هستید که از سه لایه تشکیل شده است که هر کدام دارای چهار گزینه با هزینه های متفاوت است. طعم همبرگرها با مخلوط های مختلف گزینه ها متفاوت است. شما می خواهید خوشمزه ترین همبرگری را که می توانید با بودجه مشخصی تهیه کنید.
 |
| برگر خود را با گزینه های مختلف برای هر لایه آماده کنید که هر کدام هزینه های متفاوتی دارند و مزایای متفاوتی دارند. |
درست مانند معماری یک شبکه عصبی، فضای جستجو برای همبرگر عالی از یک الگوی لایه ای پیروی می کند، که در آن هر لایه دارای چندین گزینه با تغییرات متفاوت در هزینه و عملکرد است. این مدل ساده شده یک رویکرد رایج برای تنظیم فضاهای جستجو را نشان می دهد. برای مثال، برای مدلهای مبتنی بر شبکههای عصبی کانولوشن (CNN)، مانند MobileNet، الگوریتم NAS میتواند بین تعداد متفاوتی از گزینهها – فیلترها، گامها، یا اندازههای هسته و غیره – برای لایه کانولوشن انتخاب کند.
روش
ما رویکرد خود را بر اساس فضاهای جستجویی استوار میکنیم که دو شرط را برآورده میکنند:
- یک مدل بهینه را می توان با استفاده از یکی از نامزدهای مدل ایجاد شده از جستجوی لایه قبلی و اعمال آن گزینه های جستجو در لایه فعلی ساخت.
- اگر یک محدودیت FLOP بر روی لایه فعلی قرار دهیم، می توانیم با کاهش FLOP های لایه فعلی، محدودیت هایی را برای لایه قبلی تعیین کنیم.
در این شرایط امکان جستجوی خطی از لایه 1 به لایه وجود دارد n دانستن این موضوع هنگام جستجوی بهترین گزینه برای لایه من، تغییر در هر لایه قبلی باعث بهبود عملکرد مدل نمی شود. سپس میتوانیم کاندیداها را بر اساس هزینههایشان سطل کنیم، به طوری که فقط تعداد محدودی از نامزدها در هر لایه ذخیره میشوند. اگر دو مدل FLOP یکسان داشته باشند، اما یکی دقت بهتری داشته باشد، ما فقط مدل بهتر را نگه می داریم و فرض می کنیم که این روی معماری لایه های بعدی تاثیری نخواهد داشت. در حالی که فضای جستجوی یک درمان کامل به طور تصاعدی با لایهها گسترش مییابد، زیرا طیف کاملی از گزینهها در هر لایه موجود است، رویکرد مبتنی بر هزینه لایهای ما به ما اجازه میدهد تا فضای جستجو را به میزان قابل توجهی کاهش دهیم، در حالی که میتوانیم به طور دقیق بر پیچیدگی چند جملهای استدلال کنیم. از الگوریتم ارزیابی تجربی ما نشان میدهد که در این محدودیتها میتوانیم مدلهای با عملکرد برتر را کشف کنیم.
NAS به عنوان یک مسئله بهینه سازی ترکیبی
با اعمال رویکرد هزینه لایه لایه، NAS را به یک مسئله بهینه سازی ترکیبی کاهش می دهیم. یعنی برای لایه من، می توانیم هزینه و پاداش را پس از آموزش با یک جزء داده شده محاسبه کنیم اسمن . این به مشکل ترکیبی زیر اشاره دارد: چگونه میتوانیم بهترین پاداش را دریافت کنیم اگر در هر لایه یک انتخاب را با بودجه هزینه انتخاب کنیم؟ این مشکل را می توان با روش های مختلفی حل کرد که یکی از ساده ترین آنها استفاده از برنامه نویسی پویا است که در شبه کد زیر توضیح داده شده است:
while True: # select a candidate to search in Layer i candidate = select_candidate(layeri) if searchable(candidate): # Use the layerwise structural information to generate the children. children = generate_children(candidate) reward = train(children) bucket = bucketize(children) if memorial_table[i][bucket] < reward: memorial_table[i][bucket] = children move to next layer |
| شبه کد LayerNAS. |
 |
| تصویری از رویکرد LayerNAS برای مثال تلاش برای ایجاد بهترین برگر با بودجه 7 تا 9 دلار. ما چهار گزینه برای لایه اول داریم که منجر به چهار کاندید برگر می شود. با اعمال چهار گزینه در لایه دوم، در مجموع 16 نامزد داریم. سپس آنها را در محدوده های 1 تا 2 دلار، 3 تا 4 دلار، 5 تا 6 دلار و 7 تا 8 دلار سطل می کنیم و فقط خوشمزه ترین همبرگر را در هر یک از سطل ها نگه می داریم، یعنی چهار نامزد. سپس، برای آن چهار نامزد، 16 نامزد را با استفاده از گزینه های از پیش انتخاب شده برای دو لایه اول و چهار گزینه برای هر نامزد برای لایه سوم می سازیم. دوباره آنها را سطل می کنیم، همبرگرها را در محدوده بودجه انتخاب می کنیم و بهترین ها را نگه می داریم. |
نتایج تجربی
هنگام مقایسه الگوریتمهای NAS، معیارهای زیر را ارزیابی میکنیم:
- کیفیت: دقیق ترین مدلی که الگوریتم می تواند پیدا کند کدام است؟
- ثبات: انتخاب یک مدل خوب چقدر پایدار است؟ آیا می توان مدل های با دقت بالا را به طور مداوم در آزمایش های متوالی الگوریتم کشف کرد؟
- بهره وری: چقدر طول می کشد تا الگوریتم مدلی با دقت بالا پیدا کند؟
ما الگوریتم خود را بر روی معیار استاندارد NATS-Bench با استفاده از 100 اجرای NAS ارزیابی میکنیم و با سایر الگوریتمهای NAS که قبلاً در مقاله NATS-Bench شرح داده شدهاند مقایسه میکنیم: جستجوی تصادفی، تکامل منظم و بهینهسازی سیاست نزدیک. در زیر، تفاوتهای بین این الگوریتمهای جستجو را برای معیارهایی که در بالا توضیح داده شد، تجسم میکنیم. برای هر مقایسه، میانگین دقت و تنوع در دقت را ثبت میکنیم (تغییرات با ناحیه سایهدار مربوط به محدوده بین چارکی 25 تا 75 درصد مشخص میشود).
جستجوی اندازه NATS-Bench یک مدل 5 لایه CNN را تعریف میکند، که در آن هر لایه میتواند از بین هشت گزینه مختلف، هر کدام با کانالهای متفاوتی در لایههای کانولوشن انتخاب کند. هدف ما یافتن بهترین مدل با 50 درصد FLOPهای مورد نیاز بزرگترین مدل است. عملکرد LayerNAS متمایز است زیرا مشکل را به روشی متفاوت فرموله می کند و هزینه و پاداش را از هم جدا می کند تا از جستجوی تعداد قابل توجهی از معماری های مدل نامربوط جلوگیری شود. ما دریافتیم که مدلهای کاندید با کانالهای کمتر در لایههای قبلی عملکرد بهتری دارند، که توضیح میدهد که چگونه LayerNAS مدلهای بهتر را بسیار سریعتر از سایر الگوریتمها کشف میکند، زیرا از صرف زمان برای مدلهای خارج از محدوده هزینه مورد نظر جلوگیری میکند. توجه داشته باشید که منحنی دقت پس از جستجوی طولانیتر به دلیل عدم همبستگی بین دقت اعتبارسنجی و دقت تست، کمی کاهش مییابد، یعنی برخی از معماریهای مدل با دقت اعتبارسنجی بالاتر، دقت تست پایینتری در جستجوی اندازه NATS-Bench دارند.
ما فضاهای جستجو را بر اساس MobileNetV2، MobileNetV2 1.4x، MobileNetV3 Small و MobileNetV3 Large میسازیم و معماری مدل بهینه را تحت محدودیتهای مختلف #MADD (تعداد ضرب-افزودن در هر تصویر) جستجو میکنیم. در بین تمام تنظیمات، LayerNAS مدلی با دقت بهتر در ImageNet پیدا می کند. برای جزئیات بیشتر به مقاله مراجعه کنید.
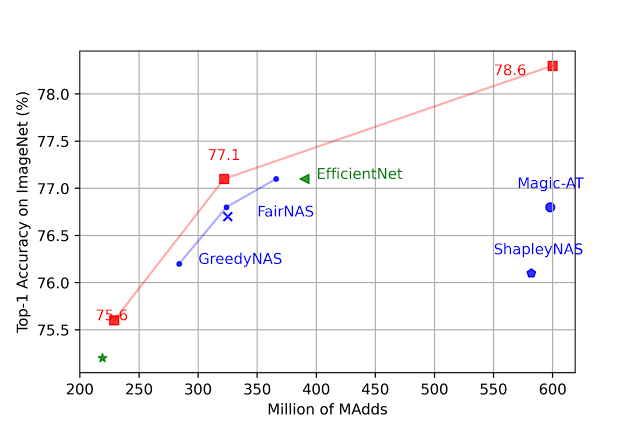 |
| مقایسه مدلهای تحت #MAds مختلف. |
نتیجه
در این پست، نحوه فرمول بندی مجدد NAS را به یک مسئله بهینه سازی ترکیبی نشان دادیم و LayerNAS را به عنوان راه حلی پیشنهاد کردیم که فقط به پیچیدگی جستجوی چند جمله ای نیاز دارد. ما LayerNAS را با الگوریتم های محبوب NAS موجود مقایسه کردیم و نشان دادیم که می تواند مدل های بهبود یافته را در NATS-Bench پیدا کند. ما همچنین از این روش برای یافتن معماری های بهتر مبتنی بر MobileNetV2 و MobileNetV3 استفاده می کنیم.
سپاسگزاریها
مایلیم از جینگیو شن، کشاو کومار، دایی پنگ، مینگ شینگ تان، استبان رئال، پیتر یانگ، ویجون وانگ، قیفی وانگ، ژوانی دونگ، شین وانگ، یینگجی میائو، یون لانگ، ژو وانگ، دا-چنگ خوان، دکیانگ تشکر کنیم. چن، فوتیس ایلیوپولوس، هان بیول کیم، رینو لی، اندرو هوارد، اریک وی، رینا پانیگراهی، راوی کومار و اندرو تامکینز برای کمک، همکاری و مشاوره.