


@mitilikrishnanمیتیلی کریشنان
رهبر علوم داده و نویسنده ثابت در نشریه رسانه “به سوی Datascience”
آیا تا به حال فکر کرده اید که چگونه مدل های یادگیری ماشین ساخته می شوند؟ امروز ما این را کشف خواهیم کرد و چند روش سریع در مورد چگونگی کشف اینکه کدام متغیرها بر روی نتایج مدل تأثیر می گذارند را یاد می گیریم.
ما از مجموعه داده های FIFA 2018 در Kaggle استفاده خواهیم کرد و مدل های زیر را کشف خواهیم کرد:
- مدل درخت تصمیم
- مدل جنگل تصادفی
این دستور کار امروز خواهد بود:
- برای آموزش مدل درخت تصمیم از مجموعه داده های FIFA استفاده کنید
- برای آموزش مدل جنگل تصادفی از مجموعه داده های FIFA استفاده کنید
- متغیرهای تأثیرگذار را در مدل ها کاوش کنید
- آستانه متغیرهای تأثیرگذار را پیدا کنید
بنابراین بدون هیچ زحمتی بیشتر بیایید شروع کنیم.
1. برای آموزش مدل درخت تصمیم از مجموعه داده های FIFA استفاده کنید
بگذارید ابتدا کمی درباره درختان تصمیم صحبت کنیم.
الگوریتم های درخت تصمیم با یک گره ریشه از یک نمونه داده شروع می شوند و سپس ویژگی ها را براساس معیارهایی مانند ناخالصی جینی یا افزایش اطلاعات انتخاب می کنند و گره های ریشه را به گره های برگ / گره های انتهایی تقسیم می کنند تا دیگر تقسیم امکان پذیر نباشد. این در نمودار زیر با یک درخت نمونه نشان داده شده است.
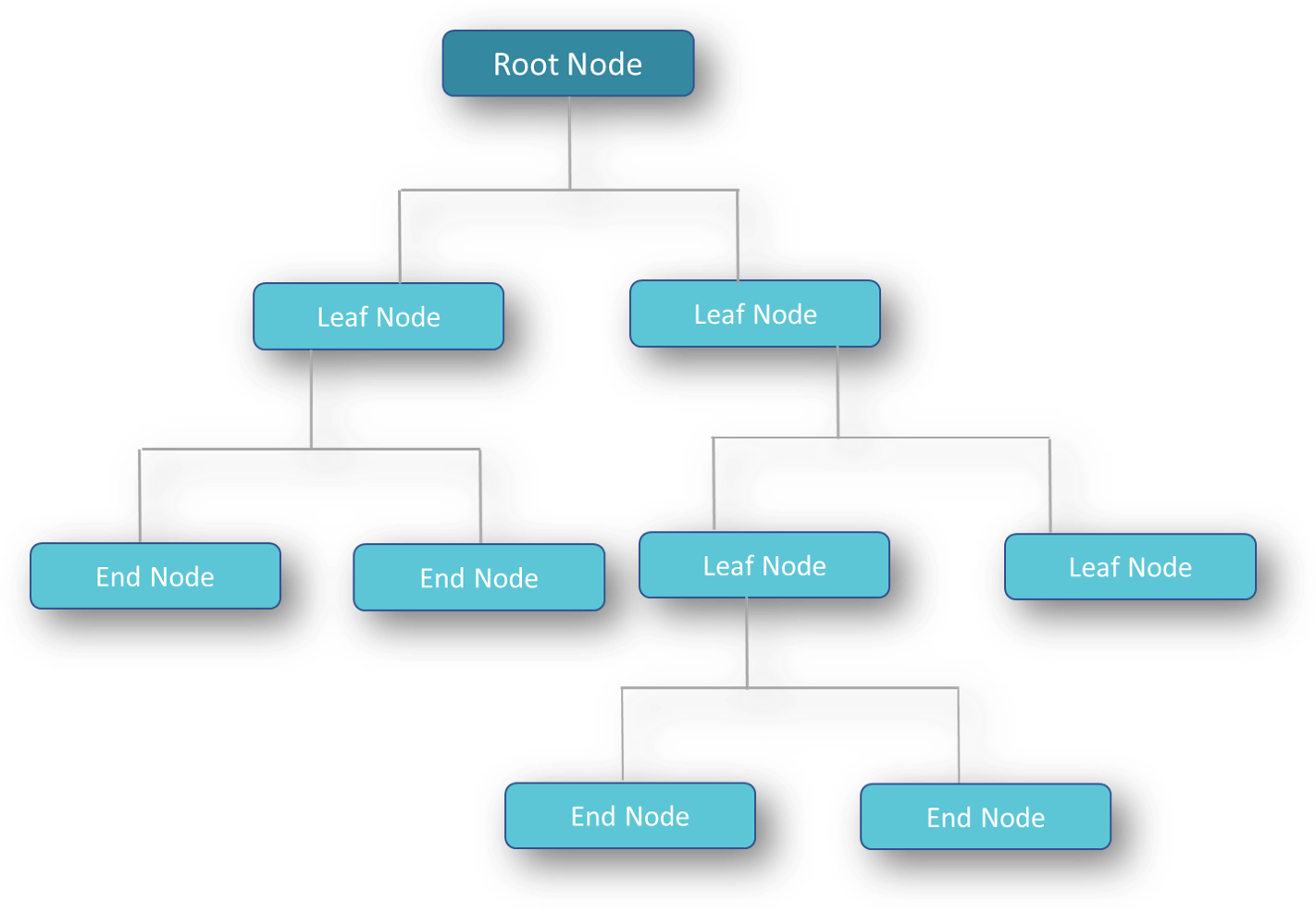
پس از وارد کردن داده ها و کتابخانه ها ، خطوط کد زیر به آموزش مدل درخت تصمیم کمک می کند.
#Create the dependent variable
y = (data['Man of the...