خواندن فواید زیادی برای دانشآموزان جوان دارد، مانند مهارتهای زبانی و زندگی بهتر، و نشان داده شده است که خواندن برای لذت با موفقیت تحصیلی مرتبط است. علاوه بر این، دانشآموزان بهزیستی عاطفی بهتر از خواندن، و همچنین دانش عمومی بهتر و درک بهتر فرهنگهای دیگر را گزارش کردهاند. با حجم وسیعی از مطالب خواندنی چه به صورت آنلاین و چه غیر آنلاین، یافتن محتوای مناسب با سن، مرتبط و جذاب میتواند یک کار چالش برانگیز باشد، اما کمک به دانشآموزان در انجام این کار گامی ضروری برای مشارکت دادن آنها در خواندن است. توصیههای مؤثری که مطالب خواندنی مرتبط را به دانشآموزان ارائه میکند، به خواندن دانشآموزان کمک میکند، و اینجاست که یادگیری ماشینی (ML) میتواند کمک کند.
ML به طور گسترده ای در ساخت سیستم های توصیه کننده برای انواع مختلف محتوای دیجیتال، از فیلم ها گرفته تا کتاب ها و اقلام تجارت الکترونیکی استفاده شده است. سیستمهای توصیهکننده در طیف وسیعی از پلتفرمهای دیجیتال برای کمک به ارائه محتوای مرتبط و جذاب برای کاربران استفاده میشوند. در این سیستمها، مدلهای ML آموزش داده میشوند تا بر اساس ترجیحات کاربر، تعامل کاربر و موارد تحت توصیه، موارد را به هر کاربر به صورت جداگانه پیشنهاد دهند. این دادهها یک سیگنال یادگیری قوی برای مدلها ارائه میکنند تا بتوانند مواردی را که احتمالاً مورد علاقه هستند توصیه کنند و در نتیجه تجربه کاربر را بهبود بخشند.
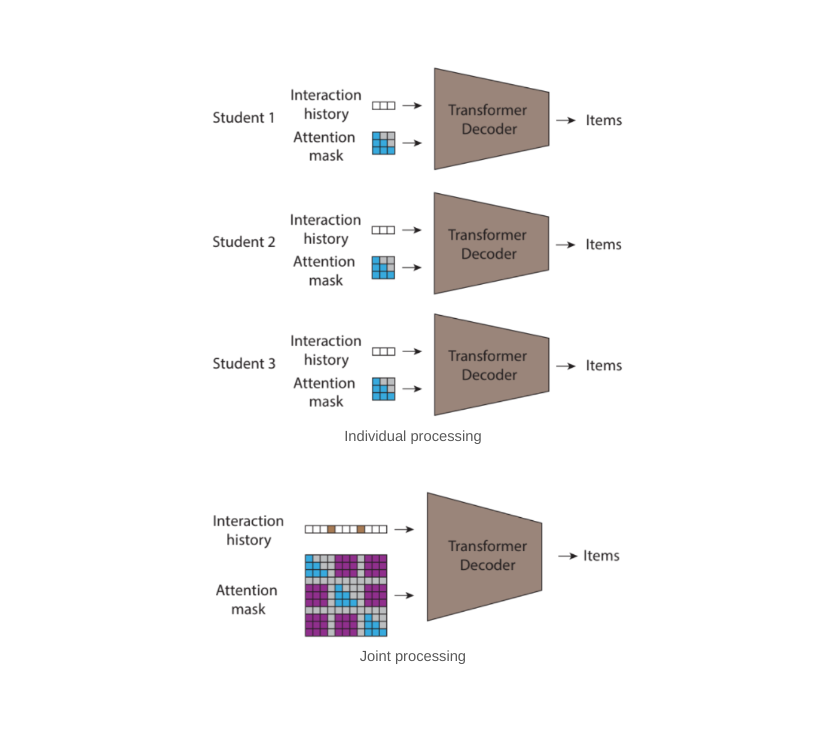
در «مطالعه: سیستمهای توصیهکننده رمزگشای موقتی آگاه اجتماعی»، ما یک سیستم توصیهکننده محتوا برای کتابهای صوتی را در یک محیط آموزشی با در نظر گرفتن ماهیت اجتماعی خواندن ارائه میکنیم. ما الگوریتم STUDY را با مشارکت Learning Ally، یک سازمان غیرانتفاعی آموزشی، با هدف ترویج خواندن در دانشآموزان نارساخوان، ایجاد کردیم که کتابهای صوتی را از طریق یک برنامه اشتراک در سطح مدرسه در اختیار دانشآموزان قرار میدهد. هدف ما با استفاده از طیف گسترده ای از کتاب های صوتی در کتابخانه Learning Ally، کمک به دانش آموزان برای یافتن محتوای مناسب برای کمک به افزایش تجربه خواندن و تعامل آنهاست. با انگیزه این واقعیت که آنچه که همسالان یک فرد در حال حاضر می خوانند تأثیرات قابل توجهی بر آنچه خواندن آنها برای آنها جالب است، دارد، ما به طور مشترک سابقه درگیری خواندن دانش آموزانی را که در یک کلاس درس هستند پردازش می کنیم. این به مدل ما اجازه میدهد تا از اطلاعات زنده در مورد آنچه که در حال حاضر در گروه اجتماعی محلی دانشآموزان، در این مورد، کلاس درس در حال انجام است، بهرهمند شود.
داده ها
Learning Ally یک کتابخانه دیجیتال بزرگ از کتابهای صوتی انتخابشده دارد که هدف آن دانشآموزان است، که آن را برای ایجاد یک مدل توصیه اجتماعی برای کمک به بهبود نتایج یادگیری دانشآموزان مناسب میسازد. ما دو سال داده مصرف کتاب صوتی ناشناس دریافت کردیم. همه دانشآموزان، مدارس و گروههای موجود در دادهها ناشناس بودند و تنها با شناسهای که بهطور تصادفی تولید شده بود شناسایی شدند که توسط Google قابل ردیابی نیست. علاوه بر این، تمام ابردادههای بالقوه قابل شناسایی فقط به صورت انبوه به اشتراک گذاشته شدند تا از دانشآموزان و مؤسسات در برابر شناسایی مجدد محافظت شود. داده ها شامل سوابق با مهر زمانی از تعامل دانش آموزان با کتاب های صوتی بود. برای هر تعامل، یک شناسه دانش آموز ناشناس (که شامل سطح نمره دانش آموز و شناسه مدرسه ناشناس است)، یک شناسه کتاب صوتی و یک تاریخ داریم. در حالی که بسیاری از مدارس دانشآموزان را در یک کلاس در چندین کلاس توزیع میکنند، ما از این فراداده استفاده میکنیم تا این فرض سادهتر را ایجاد کنیم که همه دانشآموزان در یک مدرسه و در یک سطح کلاس در یک کلاس درس هستند. در حالی که این پایه و اساس مورد نیاز برای ایجاد یک مدل توصیهگر اجتماعی بهتر را فراهم میکند، مهم است که توجه داشته باشیم که این امر ما را قادر به شناسایی مجدد افراد، گروههای طبقاتی یا مدارس نمیکند.
الگوریتم STUDY
ما مشکل توصیه را به عنوان یک مشکل پیشبینی نرخ کلیک در نظر گرفتیم، جایی که احتمال شرطی تعامل کاربر با هر مورد خاص مشروط به هر دو 1) ویژگیهای کاربر و مورد و 2) توالی سابقه تعامل آیتم برای کاربر مورد نظر را مدلسازی کردیم. . کار قبلی نشان میدهد که مدلهای مبتنی بر ترانسفورماتور، یک کلاس مدل پرکاربرد که توسط Google Research توسعه داده شده است، برای مدلسازی این مشکل مناسب هستند. هنگامی که هر کاربر به صورت جداگانه پردازش میشود، این به یک مشکل مدلسازی توالی اتورگرسیو تبدیل میشود. ما از این چارچوب مفهومی برای مدل سازی داده های خود استفاده می کنیم و سپس این چارچوب را برای ایجاد رویکرد STUDY گسترش می دهیم.
در حالی که این رویکرد برای پیشبینی نرخ کلیک میتواند وابستگیهای بین ترجیحات آیتمهای گذشته و آینده را برای یک کاربر خاص مدل کند و میتواند الگوهای شباهت بین کاربران را در زمان قطار بیاموزد، نمیتواند وابستگیها را بین کاربران مختلف در زمان استنتاج مدلسازی کند. برای شناخت ماهیت اجتماعی خواندن و رفع این نقص، مدل STUDY را توسعه دادیم، که توالی های متعددی از کتاب های خوانده شده توسط هر دانش آموز را در یک توالی واحد به هم متصل می کند که داده های چند دانش آموز را در یک کلاس درس جمع آوری می کند.
با این حال، اگر قرار است توسط ترانسفورماتورها مدلسازی شود، این نمایش دادهها به دقت دقیق نیاز دارد. در ترانسفورماتورها، ماسک توجه ماتریسی است که کنترل میکند از کدام ورودیها میتوان برای اطلاع از پیشبینیهای کدام خروجی استفاده کرد. الگوی استفاده از تمام نشانه های قبلی در یک دنباله برای اطلاع از پیش بینی یک خروجی منجر به ماتریس توجه مثلثی بالایی می شود که به طور سنتی در رمزگشاهای علّی یافت می شود. با این حال، از آنجایی که توالی وارد شده به مدل STUDY به طور موقت مرتب نیست، حتی اگر هر یک از دنبالههای تشکیلدهنده آن باشد، رمزگشای علی استاندارد دیگر برای این دنباله مناسب نیست. هنگام تلاش برای پیشبینی هر نشانه، مدل مجاز نیست به هر نشانهای که در دنباله آن قبل از آن است توجه کند. برخی از این نشانهها ممکن است دارای مهر زمانی باشند که متأخر هستند و حاوی اطلاعاتی هستند که در زمان استقرار در دسترس نیستند.
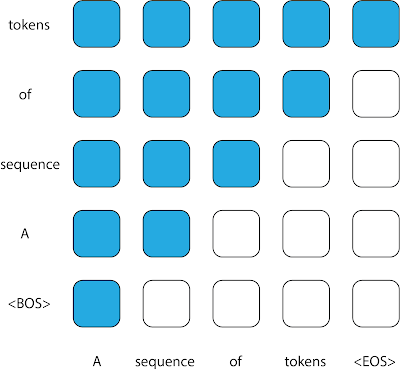 |
| در این شکل ماسک توجه که معمولاً در رمزگشاهای علّی استفاده می شود را نشان می دهیم. هر ستون یک خروجی و هر ستون نشان دهنده یک خروجی است. مقدار 1 (به صورت آبی نشان داده شده است) برای یک ورودی ماتریس در یک موقعیت خاص نشان می دهد که مدل می تواند ورودی آن ردیف را هنگام پیش بینی خروجی ستون مربوطه مشاهده کند، در حالی که مقدار 0 (به صورت سفید نشان داده شده است) خلاف آن را نشان می دهد. . |
مدل STUDY با جایگزینی ماسک توجه ماتریس مثلثی با یک ماسک توجه انعطافپذیر با مقادیر مبتنی بر مهرهای زمانی بر روی ترانسفورماتورهای علّی بنا میشود تا به دنبالههای مختلف توجه شود. در مقایسه با یک ترانسفورماتور معمولی، که اجازه توجه در میان دنبالههای مختلف را نمیدهد و دارای یک ماسک ماتریس مثلثی در داخل دنباله است، STUDY یک ماتریس توجه مثلثی علّی را در یک دنباله حفظ میکند و دارای مقادیر انعطافپذیر در سراسر دنبالهها با مقادیری است که به مهرهای زمانی بستگی دارد. از این رو، پیشبینیها در هر نقطه خروجی در دنباله توسط تمام نقاط ورودی که در گذشته رخ دادهاند نسبت به نقطه زمانی فعلی، بدون توجه به اینکه قبل یا بعد از ورودی فعلی در دنباله ظاهر میشوند، مطلع میشوند. این محدودیت علّی مهم است زیرا اگر در زمان قطار اجرا نشود، مدل به طور بالقوه میتواند پیشبینیهایی را با استفاده از اطلاعات آینده، که برای استقرار در دنیای واقعی در دسترس نخواهد بود، یاد بگیرد.
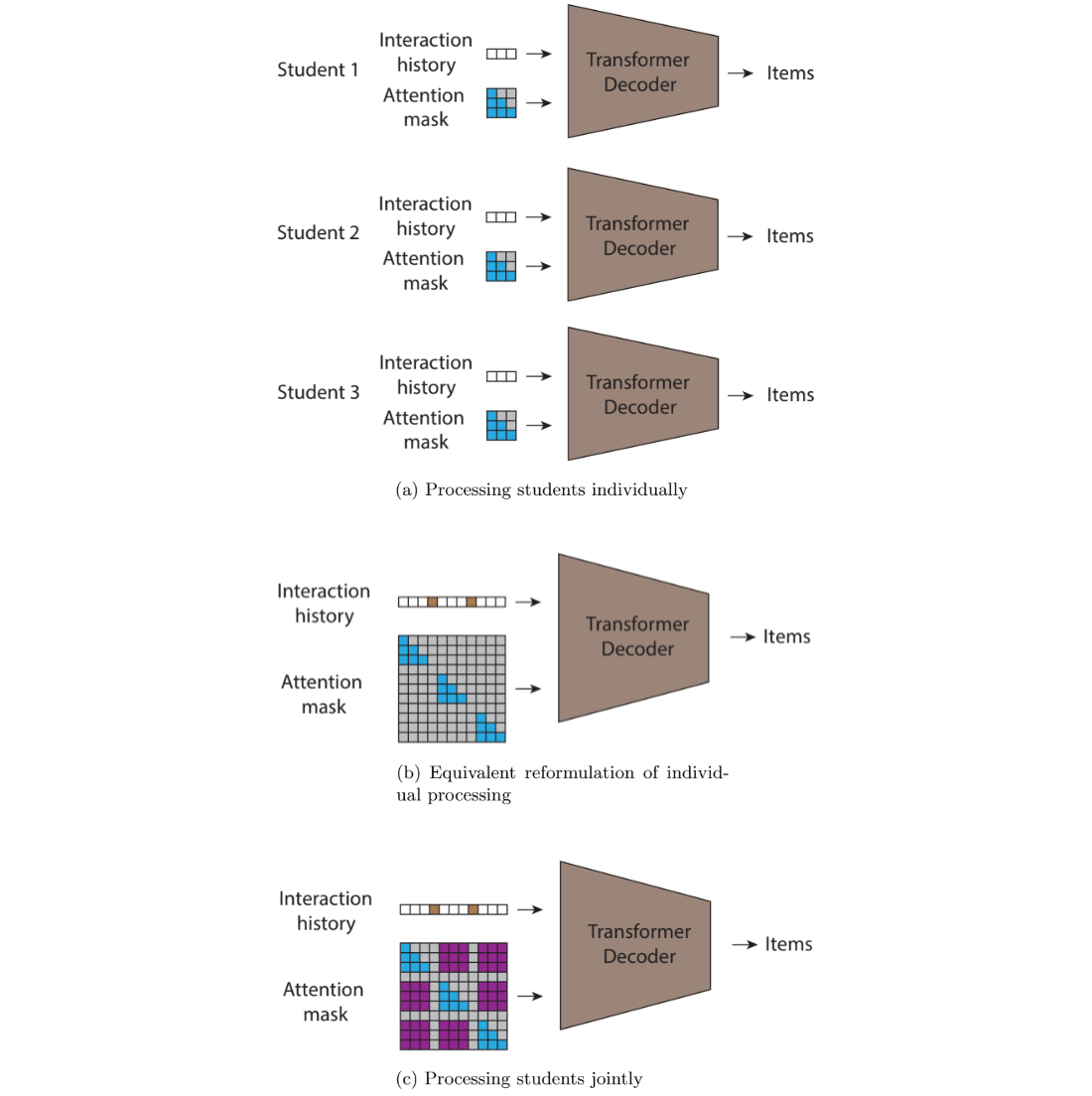 |
| در (الف) ما یک ترانسفورماتور اتورگرسیو متوالی را با توجه علّی نشان می دهیم که هر کاربر را به صورت جداگانه پردازش می کند. در (ب) یک پاس مشترک رو به جلو معادل را نشان میدهیم که به همان محاسبات (a) منجر میشود. و در نهایت، در (c) نشان میدهیم که با معرفی مقادیر جدید غیر صفر (به رنگ بنفش) به ماسک توجه، اجازه میدهیم اطلاعات در بین کاربران جریان یابد. ما این کار را با اجازه دادن به یک پیشبینی برای شرطی کردن همه تعاملات با مهر زمانی قبلی انجام میدهیم، صرف نظر از اینکه تعامل از همان کاربر بوده است یا خیر. |
آزمایش
ما از مجموعه داده Learning Ally برای آموزش مدل STUDY به همراه چندین خط پایه برای مقایسه استفاده کردیم. ما یک رمزگشای ترانسفورماتور نرخ کلیک اتورگرسیو را پیاده سازی کردیم که به آن “انفرادی” می گوییم. ک-نزدیکترین همسایه پایه (KNN)، و یک خط پایه اجتماعی قابل مقایسه، شبکه حافظه توجه اجتماعی (SAMN). ما از داده های سال تحصیلی اول برای آموزش و از داده های سال تحصیلی دوم برای اعتبار سنجی و آزمایش استفاده کردیم.
ما این مدلها را با اندازهگیری درصد زمانی که مورد بعدی که کاربر واقعاً با آن تعامل داشت در بالای مدل قرار داشت ارزیابی کردیم. n توصیه ها، به عنوان مثال، بازدید @n برای مقادیر مختلف از n. علاوه بر ارزیابی مدلها در کل مجموعه آزمون، ما همچنین نمرات مدلها را در دو زیر مجموعه از مجموعه آزمون که چالشبرانگیزتر از کل مجموعه دادهها هستند، گزارش میکنیم. ما مشاهده کردیم که دانشآموزان معمولاً در چندین جلسه با یک کتاب صوتی ارتباط برقرار میکنند، بنابراین توصیه ساده آخرین کتابی که کاربر خوانده است توصیهای بیاهمیت خواهد بود. از این رو، اولین زیرمجموعه آزمایشی، که ما از آن به عنوان “غیر ادامه” یاد می کنیم، جایی است که ما فقط به عملکرد هر مدل بر اساس توصیه ها نگاه می کنیم که دانش آموزان با کتاب هایی متفاوت از تعامل قبلی تعامل داشته باشند. همچنین مشاهده میکنیم که دانشآموزان کتابهایی را که در گذشته خواندهاند دوباره بازدید میکنند، بنابراین عملکرد قوی در مجموعه آزمون میتواند با محدود کردن توصیههای ارائه شده برای هر دانشآموز فقط به کتابهایی که در گذشته خواندهاند به دست آورد. اگرچه ممکن است توصیه موارد دلخواه قدیمی به دانشآموزان ارزشمند باشد، اما ارزش زیادی از سیستمهای توصیهگر ناشی از نمایش محتوای جدید و ناشناخته برای کاربر است. برای اندازهگیری این، مدلهای زیرمجموعهای از مجموعه آزمون را ارزیابی میکنیم که دانشآموزان برای اولین بار با یک عنوان تعامل دارند. نام این زیر مجموعه ارزیابی را «رمان» گذاشتیم.
ما متوجه شدیم که STUDY از همه مدلهای آزمایششده دیگر در تقریباً هر برشی که با آن ارزیابی کردیم، بهتر عمل میکند.
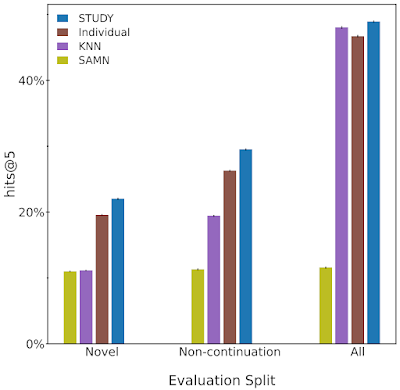 |
| در این شکل عملکرد چهار مدل Study، Individual، KNN و SAMN را با هم مقایسه می کنیم. ما عملکرد را با hits@5 اندازهگیری میکنیم، یعنی چقدر احتمال دارد که مدل عنوان بعدی را که کاربر در 5 توصیه برتر مدل بخواند پیشنهاد دهد. ما مدل را در کل مجموعه آزمایشی (همه) و همچنین تقسیمهای جدید و غیرادامهی ارزیابی میکنیم. ما می بینیم که STUDY به طور مداوم از سه مدل دیگر ارائه شده در همه تقسیم ها بهتر عمل می کند. |
اهمیت گروه بندی مناسب
در قلب الگوریتم STUDY، سازماندهی کاربران به گروهها و استنتاج مشترک بر روی چندین کاربر که در یک گروه هستند در یک پاس رو به جلو مدل است. ما یک مطالعه فرسایشی انجام دادیم که در آن به اهمیت گروهبندیهای واقعی مورد استفاده در عملکرد مدل نگاه کردیم. در مدل ارائه شده ما همه دانش آموزانی را که در یک سطح کلاس و مدرسه هستند با هم گروه بندی می کنیم. سپس با گروههایی که توسط همه دانشآموزان در همان سطح کلاس و منطقه تعریف شدهاند آزمایش میکنیم و همچنین همه دانشآموزان را در یک گروه واحد با یک زیرمجموعه تصادفی که برای هر پاس رو به جلو استفاده میشود، قرار میدهیم. ما همچنین این مدل ها را با مدل فردی برای مرجع مقایسه می کنیم.
ما دریافتیم که استفاده از گروههایی که بیشتر بومیسازی شده بودند مؤثرتر بود، به طوری که گروهبندی سطح مدرسه و کلاس بهتر از گروهبندی سطح منطقه و کلاس بود. این امر از این فرضیه پشتیبانی می کند که مدل STUDY به دلیل ماهیت اجتماعی فعالیت هایی مانند خواندن موفق است – انتخاب های خواندن افراد احتمالاً با انتخاب های خواندن اطرافیانشان مرتبط است. هر دوی این مدل ها از دو مدل دیگر (تک گروهی و انفرادی) که در آن سطح پایه برای گروه بندی دانش آموزان استفاده نمی شود، عملکرد بهتری داشتند. این نشان می دهد که داده های کاربران با سطوح خواندن و علایق مشابه برای عملکرد مفید است.
کار آینده
این کار محدود به توصیههای مدلسازی برای جمعیتهای کاربر است که در آن ارتباطات اجتماعی همگن فرض میشود. در آینده، مدل سازی یک جمعیت کاربر که در آن روابط همگن نیستند، به عنوان مثال، جایی که به طور قطعی انواع مختلفی از روابط وجود دارد یا قدرت یا تأثیر نسبی روابط مختلف شناخته شده است، مفید خواهد بود.
سپاسگزاریها
این کار شامل تلاشهای مشترک یک تیم چند رشتهای متشکل از محققان، مهندسان نرمافزار و کارشناسان موضوع آموزشی بود. از نویسندگان همکارمان: دیانا مینکو، لورن هارل و کاترین هلر از Google تشکر میکنیم. همچنین از همکارانمان در Learning Ally، جف هو، آکشات شاه، ارین واکر، و تایلر باستیان، و همکارانمان در گوگل، مارک رپنیک، آکی استرلا، فرناندو دیاز، اسکات سانر، امیلی سالکی و لو پرولیف تشکر میکنیم.