ارزیابی مدل در یادگیری ماشین استفاده می شود ارزیابی عملکرد یک مدل و مقایسه مدل های مختلف به منظور انتخاب بهترین عملکرد. کتابخانه Scikit-learn Python ابزاری را برای کمک به امتیازدهی و ارزیابی عملکرد یک مدل یادگیری ماشین فراهم میکند.
در این آموزش نحوه استفاده از Sklearn برای ارزیابی مدل های یادگیری ماشین در پایتون را خواهیم آموخت. ما از ماژول متریک Scikit-learn برای ارزیابی عملکرد یک طبقه بندی، یک خوشه بندی و یک مشکلات رگرسیون استفاده خواهیم کرد.
چگونه یک مدل یادگیری ماشینی را در Scikit-Learn ارزیابی کنیم؟
تکنیکهای متعددی وجود دارد که میتوان از آنها برای ارزیابی یک مدل یادگیری ماشین در Scikit-learn استفاده کرد، بسته به نوع پروژه و اینکه آیا شما یک طبقهبندی، یک رگرسیون یا یک مدل یادگیری ماشینی خوشهبندی را ارزیابی میکنید. در اینجا یک ایده کلی از مراحل انجام ارزیابی مدل آمده است:
- مجموعه داده را بارگیری کنید
- داده ها را تقسیم کنید
- تنظیم فراپارامتر
- مدل را آموزش دهید
- پیش بینی کنید
- یک متریک عملکرد را انتخاب کنید
- مدل را ارزیابی کنید
- ماتریس سردرگمی را ترسیم کنید
- گزارش طبقه بندی را چاپ کنید
- منحنی ROC AUC را رسم کنید
ما از مجموعه داده سرطان پستان برای انجام یک طبقه بندی با استفاده از K-Nearest Neighbors استفاده می کنیم و سپس به شما نشان می دهیم که چگونه از معیارهای ارزیابی برای ارزیابی مدل استفاده کنید.
1. مجموعه داده را بارگذاری کنید
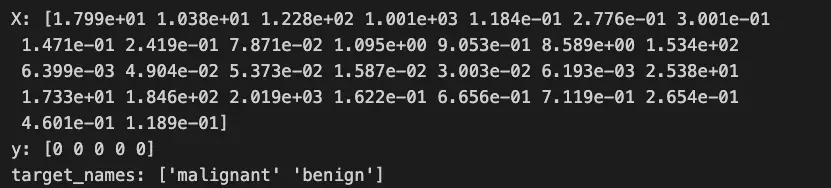
اولین قدم وارد کردن مجموعه داده با استفاده از load_breast_cancer() عملکرد از Scikit-learn داخلی datasets مدول.
# Step 1: Load the dataset
data = load_breast_cancer()
X = data.data
y = data.target
target_names = data.target_names
print('X:',X[0],'\ny:',y[:5],'\ntarget_names:',target_names)

برای درک داده هایی که مشاهده می کنید، می توانید داده ها را به عنوان یک Pandas DataFrame بارگیری کنید.
import pandas as pd
# Create a DataFrame from the data and target
df = pd.DataFrame(data.data, columns=data.feature_names)
df['target'] = data.target
# Optional: If you want to include the target names as well
df['target_names'] = data.target_names[df['target']]
# Print the DataFrame
df.head()
در آن DataFrame، خواهید دید که X متغیر تمام داده های موجود در جدول را به غیر از دو ستون آخر نشان می دهد. ستون هدف مقادیر the را نشان می دهد y متغیر و ستون target_names مقادیری را نشان می دهد target_names متغیر. وقتی پیش نمایش کردیم X[0]، مقادیر را از ردیف اول داده ها چاپ کردیم.

2. داده ها را با Train_test_split تقسیم کنید
مجموعه داده خود را به یک مجموعه آموزشی و یک مجموعه آزمایشی تقسیم کنید. مجموعه آموزشی برای آموزش مدل و مجموعه آزمون برای ارزیابی استفاده می شود.
from sklearn.model_selection import train_test_split
# Step 2: Split the data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
3. تنظیم فراپارامتر
برای بهبود عملکرد مدل، تنظیم هایپرپارامتر را انجام دهید. می توانید از GridSearchCV برای یافتن بهترین ترکیبی از فراپارامترها استفاده کنید.
# Step 3: Perform hyperparameter tuning with GridSearchCV
# Instantiate the model
knn = KNeighborsClassifier()
# Tune hyper parameters with GridSearchCV
param_grid = {"n_neighbors": [3, 5, 7, 9]}
grid_search = GridSearchCV(knn, param_grid, cv=5)
grid_search.fit(X_train, y_train)
best_k = grid_search.best_params_["n_neighbors"]
4. مدل را آموزش دهید
آموزش مدل یادگیری ماشین بر روی داده های آموزشی با استفاده از fit() روش. بهترین تعداد همسایگان را از مرحله قبل تا مرحله ارائه کنید n_neighbors.
# Step 4: Train the model
knn = KNeighborsClassifier(n_neighbors=best_k)
knn.fit(X_train, y_train)
5. پیش بینی کنید
با استفاده از predict() روش بر روی knn شی مدل
# Step 5: Make predictions
y_pred = knn.predict(X_test)
یک متریک عملکرد را انتخاب کنید
یک معیار ارزیابی بر اساس نوع مشکل یادگیری ماشین، مانند دقت، دقت، یادآوری، امتیاز F1 یا سطح زیر منحنی ROC (ROC AUC) انتخاب کنید. انتخاب بستگی به این دارد که آیا مشکل طبقه بندی، رگرسیون یا خوشه بندی دارید.
برای انتخاب معیار عملکرد مناسب مطمئن شوید که شما هدف مدل خود را درک کنید و معیار مناسبی را برای نوع مشکل یادگیری ماشین انتخاب کنید. در برخی موارد ممکن است دقت و یادآوری و در برخی دیگر دقت بالاتری بخواهید. شما همچنین می خواهید معیار مناسبی را بر اساس نوع مشکل انتخاب کنید. شما باید بر اساس نوع مشکل ML از معیارهای مختلفی استفاده کنید. در اینجا دستورالعملی وجود دارد که به شما در انتخاب معیار مناسب بر اساس نوع مشکل یادگیری ماشین کمک می کند:
- طبقه بندی: دقت، دقت و فراخوان، امتیاز F1، ROC-AUC
- رگرسیون: میانگین مربعات خطا، میانگین خطای مطلق، ریشه MSE (RMSE)، مربع R
- خوشه بندی: شاخص رند تعدیل شده، اطلاعات متقابل
راهنمای ما را بررسی کنید که تمام معیارهای Scikit-learn را توضیح می دهد.
مدل را ارزیابی کنید
برچسبهای پیشبینیشده را با برچسبهای واقعی مجموعه اعتبارسنجی یا مجموعه آزمایشی مقایسه کنید. متریک عملکرد انتخابی را با استفاده از توابع مناسب مانند accuracy_score()، precision_score()، recall_score()، f1_score() یا roc_auc_score() محاسبه کنید.
from sklearn.metrics import (
accuracy_score,
precision_score,
recall_score,
f1_score,
roc_auc_score
)
# Step 6: Evaluate the model
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
roc_auc = roc_auc_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')
print(f'Precision: {precision}')
print(f'Recall: {recall}')
print(f'F1-Score: {f1}')
print(f'ROC AUC: {roc_auc}')

ماتریس سردرگمی طرح
ما مدل را با استفاده از ماژول متریک Scikit-learn ارزیابی خواهیم کرد. از آن ماژول، ما از آن استفاده خواهیم کرد confusion_matrix() تابع و ConfusionMatrixDisplay() کلاس برای نشان دادن و رسم ماتریس سردرگمی در پایتون.
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
# Step 6: Plot the confusion matrix
cm = confusion_matrix(y_test, y_pred)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=target_names)
disp.plot()
disp.ax_.set(title='Confusion Matrix')
plt.show()

چاپ گزارش طبقه بندی
در مرحله بعد، معیارهای مدل را با استفاده از گزارش طبقهبندی ارزیابی میکنیم sklearn.metrics.classification_report.
from sklearn.metrics import classification_report
# Step 7: View the Classification Report
print(classification_report(y_test, y_pred))

منحنی ROC AUC را رسم کنید
پس از آن، نرخ های مثبت کاذب و نرخ های مثبت واقعی را با رسم منحنی ROC AUC با استفاده از نمودار ارزیابی می کنیم. RocCurveDisplay کلاس sklearn.metrics. این نشان خواهد داد roc_auc_score() در آستانه های طبقه بندی مختلف
import matplotlib.pyplot as plt
from sklearn.metrics import RocCurveDisplay
# Step 8: Plot the ROC AUC curve
y_scores = knn.predict_proba(X_test)
roc_display = RocCurveDisplay.from_estimator(knn, X_test, y_test)
plt.plot([0, 1], [0, 1], 'k--')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC AUC Curve')
plt.show()

ارزیابی مدل طبقه بندی با Scikit-Learn
بیایید سعی کنیم عملکرد یک مدل یادگیری ماشین را در مسائل طبقه بندی با استفاده از یکی از توابع امتیازدهی زیر از sklearn.metrics ارزیابی کنیم:
- accuracy_score(),
- precision_score()،
- recall_score()،
- f1_score()،
- roc_auc_score()
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import (
confusion_matrix,
ConfusionMatrixDisplay,
classification_report,
accuracy_score,
precision_score,
recall_score,
f1_score,
roc_auc_score,
RocCurveDisplay
)
# Step 1: Load the dataset
data = load_breast_cancer()
X = data.data
y = data.target
target_names = data.target_names
# Step 2: Split the data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Step 3: Perform hyperparameter tuning with GridSearchCV
# Instantiate the model to be tuned
knn = KNeighborsClassifier()
# Tune hyper parameters with GridSearchCV
param_grid = {"n_neighbors": [3, 5, 7, 9]}
grid_search = GridSearchCV(knn, param_grid, cv=5)
grid_search.fit(X_train, y_train)
best_k = grid_search.best_params_["n_neighbors"]
# Step 4: Train the model
knn = KNeighborsClassifier(n_neighbors=best_k)
knn.fit(X_train, y_train)
# Step 5: Make predictions
y_pred = knn.predict(X_test)
# Step 6: Evaluate the model
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
roc_auc = roc_auc_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')
print(f'Precision: {precision}')
print(f'Recall: {recall}')
print(f'F1-Score: {f1}')
print(f'ROC AUC: {roc_auc}')
# Step 6: Plot the confusion matrix
cm = confusion_matrix(y_test, y_pred)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=target_names)
disp.plot()
disp.ax_.set(title='Confusion Matrix')
plt.show()
# Step 7: View the Classification Report
print(classification_report(y_test, y_pred))
# Step 8: Plot the ROC AUC curve
y_scores = knn.predict_proba(X_test)
roc_display = RocCurveDisplay.from_estimator(knn, X_test, y_test)
plt.plot([0, 1], [0, 1], 'k--')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC AUC Curve')
plt.show()
ارزیابی مدل رگرسیون با Scikit-Learn
بیایید سعی کنیم عملکرد یک مدل یادگیری ماشین را در مسائل رگرسیونی ارزیابی کنیم، از یکی از توابع امتیازدهی زیر از sklearn.metrics استفاده کنیم:
- mean_absolute_error()،
- خطای میانگین مربعات()،
- r2_score()
import matplotlib.pyplot as plt
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.neighbors import KNeighborsRegressor
from sklearn.metrics import (
mean_squared_error,
mean_absolute_error,
r2_score,
)
# Step 1: Load the dataset
data = load_diabetes()
X = data.data
y = data.target
# Step 2: Split the data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Step 3: Perform hyperparameter tuning with GridSearchCV
# Instantiate the model to be tuned
knn = KNeighborsRegressor()
# Tune hyperparameters with GridSearchCV
param_grid = {"n_neighbors": [3, 5, 7, 9]}
grid_search = GridSearchCV(knn, param_grid, cv=5)
grid_search.fit(X_train, y_train)
best_k = grid_search.best_params_["n_neighbors"]
# Step 4: Train the model
knn = KNeighborsRegressor(n_neighbors=best_k)
knn.fit(X_train, y_train)
# Step 5: Make predictions
y_pred = knn.predict(X_test)
# Step 6: Evaluate the model
mse = mean_squared_error(y_test, y_pred)
mae = mean_absolute_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f'Mean Squared Error: {mse}')
print(f'Mean Absolute Error: {mae}')
print(f'R^2 Score: {r2}')
# Step 7: Plot the predicted values vs. true values
plt.scatter(y_test, y_pred)
plt.xlabel('True Values')
plt.ylabel('Predicted Values')
plt.title('Predicted Values vs. True Values')
plt.show()


خوشه بندی مدل ارزیابی با Scikit-Learn
بیایید سعی کنیم عملکرد یک مدل یادگیری ماشینی را در مسائل خوشهبندی ارزیابی کنیم، از یکی از توابع امتیازدهی زیر از sklearn.metrics استفاده کنیم:
- silhouette_score()،
- calinski_harabasz_score()،
- davies_bouldin_score()
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.cluster import KMeans
from sklearn.metrics import (
silhouette_score,
calinski_harabasz_score,
davies_bouldin_score
)
# Step 1: Load the dataset
data = load_iris()
X = data.data
# Step 2: Split the data into training and test sets (not used in clustering)
X_train, X_test = train_test_split(X, test_size=0.3, random_state=42)
# Step 3: Perform hyperparameter tuning with GridSearchCV
# Instantiate the model to be tuned
kmeans = KMeans()
# Tune hyperparameters with GridSearchCV
param_grid = {"n_clusters": [2, 3, 4, 5]}
grid_search = GridSearchCV(kmeans, param_grid, cv=5)
grid_search.fit(X)
# Step 4: Train the model with the best hyperparameters
best_k = grid_search.best_params_["n_clusters"]
kmeans = KMeans(n_clusters=best_k)
kmeans.fit(X)
# Step 5: Make predictions (labels) for the entire dataset
labels = kmeans.predict(X)
# Step 6: Evaluate the model
silhouette = silhouette_score(X, labels)
calinski_harabasz = calinski_harabasz_score(X, labels)
davies_bouldin = davies_bouldin_score(X, labels)
print(f'Silhouette Score: {silhouette}')
print(f'Calinski-Harabasz Score: {calinski_harabasz}')
print(f'Davies-Bouldin Score: {davies_bouldin}')
# Step 7: Plot the cluster assignments
plt.scatter(X[:, 0], X[:, 1], c=labels)
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Cluster Assignments')
plt.show()


نتیجه
این پایان این آموزش ارزیابی مدل یادگیری ماشین با Scikit-learn و Python است. برای جزئیات بیشتر، مستندات Scikit-learn در مورد ارزیابی مدل را بررسی کنید.

استراتژیست سئو در Tripadvisor، Seek سابق (ملبورن، استرالیا). متخصص در سئو فنی. در تلاش برای سئوی برنامهریزی شده برای سازمانهای بزرگ از طریق استفاده از پایتون، R و یادگیری ماشین.