تحقیقات معماری کامپیوتر سابقه طولانی در توسعه شبیه سازها و ابزارهایی برای ارزیابی و شکل دادن به طراحی سیستم های کامپیوتری دارد. به عنوان مثال، شبیه ساز SimpleScalar در اواخر دهه 1990 معرفی شد و به محققان اجازه داد تا ایده های مختلف ریزمعماری را بررسی کنند. شبیه سازها و ابزارهای معماری کامپیوتر مانند gem5، DRAMSys و بسیاری دیگر نقش مهمی در پیشرفت تحقیقات معماری کامپیوتر ایفا کرده اند. از آن زمان، این منابع و زیرساخت های مشترک به نفع صنعت و دانشگاه بوده و محققان را قادر ساخته است که به طور سیستماتیک بر روی کار یکدیگر بسازند و منجر به پیشرفت های قابل توجهی در این زمینه شود.
با این وجود، تحقیقات معماری کامپیوتر در حال تکامل است و صنعت و دانشگاه به سمت بهینهسازی یادگیری ماشین (ML) روی آوردهاند تا نیازهای خاص دامنه را برآورده کنند، مانند ML برای معماری کامپیوتر، ML برای شتاب TinyML، بهینهسازی مسیر داده شتابدهنده DNN، کنترلکنندههای حافظه، مصرف انرژی. ، امنیت و حریم خصوصی. اگرچه کار قبلی مزایای ML را در بهینهسازی طراحی نشان داده است، فقدان خطوط پایه قوی و قابل تکرار مانع از مقایسه منصفانه و عینی در بین روشهای مختلف میشود و چندین چالش را برای استقرار آنها ایجاد میکند. برای اطمینان از پیشرفت پایدار، درک و مقابله با این چالش ها به طور جمعی ضروری است.
برای کاهش این چالشها، در «ArchGym: An Open-Source Gymnasium for Learning Assisted Architecture Design» که در ISCA 2023 پذیرفته شد، ArchGym را معرفی کردیم که شامل انواع شبیهسازهای معماری کامپیوتر و الگوریتمهای ML است. فعالسازی شده توسط ArchGym، نتایج ما نشان میدهد که با تعداد کافی نمونه، هر یک از مجموعه متنوعی از الگوریتمهای ML قادر به یافتن مجموعه بهینه پارامترهای طراحی معماری برای هر مسئله هدف هستند. هیچ راه حلی لزوما بهتر از دیگری نیست. این نتایج بیشتر نشان میدهد که انتخاب فراپارامترهای بهینه برای یک الگوریتم ML معین برای یافتن طراحی معماری بهینه ضروری است، اما انتخاب آنها بیاهمیت است. ما کد و مجموعه داده را در چندین شبیه سازی معماری کامپیوتر و الگوریتم های ML منتشر می کنیم.
چالشها در تحقیقات معماری به کمک ML
تحقیقات معماری به کمک ML چندین چالش را به همراه دارد، از جمله:
- برای یک مشکل خاص معماری کامپیوتر با کمک ML (به عنوان مثال، یافتن راه حل بهینه برای یک کنترل کننده DRAM) هیچ روش سیستماتیکی برای شناسایی الگوریتم ها یا فراپارامترهای بهینه ML وجود ندارد (به عنوان مثال، نرخ یادگیری، مراحل گرم کردن، و غیره). طیف گستردهتری از روشهای ML و اکتشافی، از راه رفتن تصادفی گرفته تا یادگیری تقویتی (RL) وجود دارد که میتواند برای کاوش فضای طراحی (DSE) استفاده شود. در حالی که این روش ها بهبود عملکرد قابل توجهی را نسبت به انتخاب خطوط پایه خود نشان داده اند، مشخص نیست که آیا این بهبودها به دلیل انتخاب الگوریتم های بهینه سازی یا فراپارامترها بوده است.
بنابراین، برای اطمینان از تکرارپذیری و تسهیل پذیرش گسترده معماری DSE به کمک ML، لازم است یک روش معیارسنجی سیستماتیک ترسیم شود. - در حالی که شبیهسازهای معماری کامپیوتری ستون فقرات نوآوریهای معماری بودهاند، نیازی در حال ظهور برای پرداختن به مبادلات بین دقت، سرعت و هزینه در کاوش معماری وجود دارد. دقت و سرعت تخمین عملکرد به طور گسترده ای از یک شبیه ساز به شبیه ساز دیگر متفاوت است، بسته به جزئیات مدل سازی زیربنایی (به عنوان مثال، مدل های پراکسی دقیق در مقابل مدل های پروکسی مبتنی بر ML). در حالی که مدلهای پراکسی تحلیلی یا مبتنی بر ML به دلیل کنار گذاشتن جزئیات سطح پایین زیرک هستند، معمولاً از خطای پیشبینی بالایی رنج میبرند. همچنین، به دلیل مجوز تجاری، میتواند محدودیتهای سختی برای تعداد اجراهای جمعآوریشده از یک شبیهساز وجود داشته باشد. به طور کلی، این محدودیتها عملکرد متمایز را در مقایسه با بازده نمونه نشان میدهند که بر انتخاب الگوریتم بهینهسازی برای کاوش معماری تأثیر میگذارد.
تشریح نحوه مقایسه سیستماتیک اثربخشی الگوریتم های مختلف ML تحت این محدودیت ها چالش برانگیز است. - در نهایت، چشم انداز الگوریتم های ML به سرعت در حال تکامل است و برخی از الگوریتم های ML برای مفید بودن به داده نیاز دارند. علاوه بر این، ارائه نتیجه DSE به مصنوعات معنادار مانند مجموعه داده ها برای ترسیم بینش در مورد فضای طراحی بسیار مهم است.
در این اکوسیستم به سرعت در حال تکامل، اطمینان از چگونگی استهلاک سربار الگوریتمهای جستجو برای اکتشاف معماری ضروری است. نه آشکار است و نه به طور سیستماتیک مورد مطالعه قرار گرفته است که چگونه می توان از داده های اکتشافی استفاده کرد و در عین حال نسبت به الگوریتم جستجوی زیربنایی ناشناس بود.
طراحی ArchGym
ArchGym با ارائه یک چارچوب یکپارچه برای ارزیابی منصفانه الگوریتم های جستجوی مختلف مبتنی بر ML به این چالش ها می پردازد. این شامل دو جزء اصلی است: 1) محیط ArchGym و 2) عامل ArchGym. محیط یک کپسولهسازی از مدل هزینه معماری است – که شامل تأخیر، توان عملیاتی، مساحت، انرژی و غیره برای تعیین هزینه محاسباتی اجرای حجم کار، با توجه به مجموعهای از پارامترهای معماری – جفت شده با حجم کاری (های) هدف است. عامل یک کپسوله سازی از الگوریتم ML است که برای جستجو استفاده می شود و متشکل از فراپارامترها و یک خط مشی راهنما است. فراپارامترها ذاتی الگوریتمی هستند که مدل باید برای آن بهینه شود و می تواند به طور قابل توجهی بر عملکرد تأثیر بگذارد. از سوی دیگر، خط مشی تعیین می کند که چگونه عامل به طور مکرر یک پارامتر را برای بهینه سازی هدف هدف انتخاب می کند.
قابل ذکر است، ArchGym همچنین دارای یک رابط استاندارد است که این دو مؤلفه را به هم متصل می کند، در حالی که داده های کاوش را به عنوان مجموعه داده ArchGym ذخیره می کند. در هسته خود، رابط شامل سه سیگنال اصلی است: وضعیت سخت افزاری، پارامترهای سخت افزاری، و معیارهای. این سیگنال ها حداقل برای ایجاد یک کانال ارتباطی معنادار بین محیط و عامل هستند. با استفاده از این سیگنال ها، عامل وضعیت سخت افزار را مشاهده می کند و مجموعه ای از پارامترهای سخت افزاری را برای بهینه سازی مکرر یک پاداش (تعریف شده توسط کاربر) پیشنهاد می کند. پاداش تابعی از معیارهای عملکرد سخت افزار مانند عملکرد، مصرف انرژی و غیره است.
 |
| ArchGym شامل دو جزء اصلی است: محیط ArchGym و عامل ArchGym. محیط ArchGym مدل هزینه را در بر می گیرد و عامل انتزاعی از یک خط مشی و فراپارامترها است. با یک رابط استاندارد که این دو مؤلفه را به هم متصل می کند، ArchGym یک چارچوب یکپارچه برای ارزیابی الگوریتم های جستجوی مختلف مبتنی بر ML به طور منصفانه ارائه می دهد و در عین حال داده های کاوش را به عنوان مجموعه داده ArchGym ذخیره می کند. |
الگوریتم های ML می توانند به همان اندازه برای برآوردن مشخصات هدف تعریف شده توسط کاربر مطلوب باشند
با استفاده از ArchGym، ما به طور تجربی نشان میدهیم که در بین اهداف بهینهسازی مختلف و مشکلات DSE، حداقل یک مجموعه از فراپارامترها وجود دارد که عملکرد سخت افزاری مشابهی با سایر الگوریتم های ML دارد.. یک فراپارامتر ضعیف (انتخاب تصادفی) برای الگوریتم ML یا خط پایه آن می تواند منجر به یک نتیجه گمراه کننده شود که یک خانواده خاص از الگوریتم های ML بهتر از دیگری است. ما نشان میدهیم که با تنظیم فراپارامتر کافی، الگوریتمهای جستجوی مختلف، حتی پیادهروی تصادفی (RW)، قادر به شناسایی بهترین پاداش ممکن هستند. با این حال، توجه داشته باشید که یافتن مجموعه ای از فراپارامترهای مناسب ممکن است به جستجوی جامع یا حتی شانس برای رقابتی کردن آن نیاز داشته باشد.
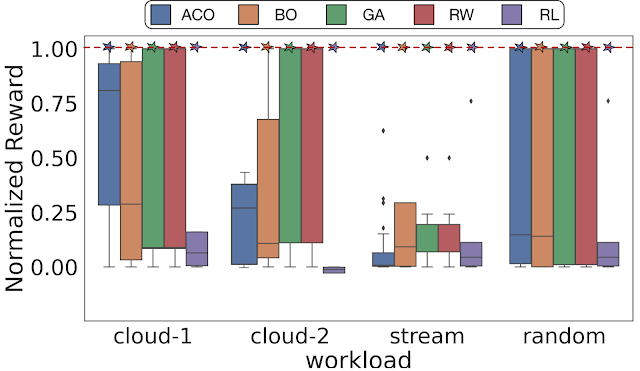 |
| با تعداد کافی نمونه، حداقل یک مجموعه از فراپارامترها وجود دارد که منجر به عملکرد یکسان در طیف وسیعی از الگوریتمهای جستجو میشود. در اینجا خط چین نشان دهنده حداکثر پاداش نرمال شده است. Cloud-1، ابر-2، جریان، و تصادفی چهار ردیابی حافظه مختلف را برای DRAMSys (چارچوب اکتشاف فضای طراحی زیرسیستم DRAM) نشان می دهد. |
آموزش ساخت مجموعه داده و مدل پراکسی با کیفیت بالا
ایجاد یک رابط یکپارچه با استفاده از ArchGym همچنین ایجاد مجموعه داده هایی را امکان پذیر می کند که می توانند برای طراحی مدل های هزینه معماری پروکسی مبتنی بر داده مبتنی بر داده بهتر برای بهبود سرعت شبیه سازی معماری استفاده شوند. برای ارزیابی مزایای مجموعههای داده در ساخت یک مدل ML برای تقریبی هزینههای معماری، از توانایی ArchGym برای ثبت دادهها از هر اجرا از DRAMSys برای ایجاد چهار نوع مجموعه داده، هر کدام با تعداد نقاط داده متفاوت، استفاده میکنیم. برای هر نوع، ما دو دسته ایجاد میکنیم: (الف) مجموعه دادههای متنوع، که دادههای جمعآوریشده از عوامل مختلف (ACO، GA، RW، و BO) را نشان میدهد، و (ب) فقط ACO، که دادههای جمعآوریشده منحصراً از ACO را نشان میدهد. agent که هر دو به همراه ArchGym منتشر می شوند. ما یک مدل پراکسی را روی هر مجموعه داده با استفاده از رگرسیون جنگل تصادفی با هدف پیشبینی تأخیر طرحها برای شبیهساز DRAM آموزش میدهیم. نتایج ما نشان می دهد که:
- با افزایش اندازه مجموعه داده، میانگین میانگین مربعات ریشه نرمال شده خطا (RMSE) اندکی کاهش می یابد.
- با این حال، همانطور که تنوع در مجموعه داده را معرفی می کنیم (به عنوان مثال، جمع آوری داده ها از عوامل مختلف)، 9× تا 42× RMSE کمتری را در اندازه های مختلف داده مشاهده می کنیم.
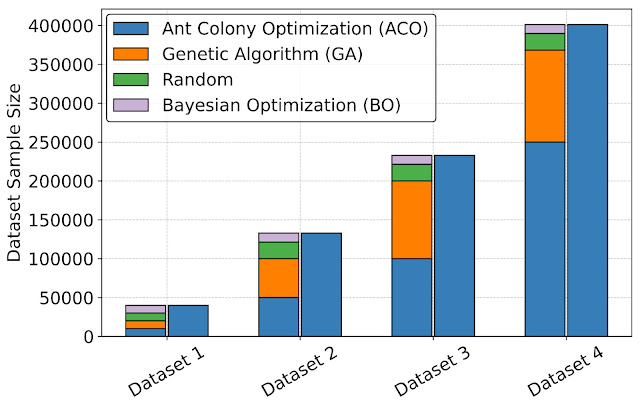 |
| مجموعه داده های متنوع در میان عوامل مختلف با استفاده از رابط ArchGym. |
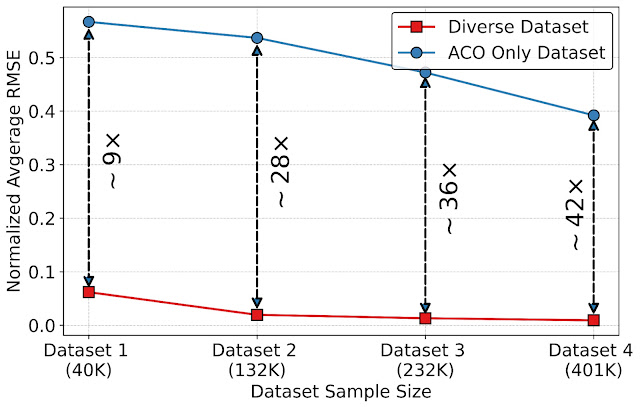 |
| تأثیر یک مجموعه داده متنوع و اندازه مجموعه بر روی RMSE نرمال شده. |
نیاز به یک اکوسیستم جامعه محور برای تحقیقات معماری به کمک ML
در حالی که، ArchGym یک تلاش اولیه برای ایجاد یک اکوسیستم منبع باز است که (1) طیف گسترده ای از الگوریتم های جستجو را به شبیه سازهای معماری کامپیوتر به شیوه ای یکپارچه و با قابلیت گسترش آسان متصل می کند، (2) تحقیق در کامپیوتر به کمک ML را تسهیل می کند. معماری، و (3) داربستی را برای توسعه خطوط پایه قابل تکرار تشکیل می دهد، چالش های باز زیادی وجود دارد که نیاز به حمایت در سطح جامعه دارند. در زیر برخی از چالش های باز در طراحی معماری به کمک ML را بیان می کنیم. پرداختن به این چالش ها مستلزم یک تلاش هماهنگ و یک اکوسیستم جامعه محور است.
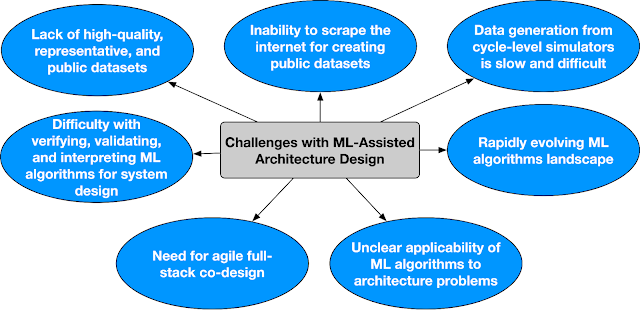 |
| چالش های کلیدی در طراحی معماری به کمک ML |
ما این اکوسیستم را معماری 2.0 می نامیم. ما چالشهای کلیدی و چشماندازی را برای ایجاد یک اکوسیستم فراگیر از محققان بینرشتهای برای مقابله با مشکلات باز طولانی مدت در استفاده از ML برای تحقیقات معماری رایانه ترسیم میکنیم. اگر علاقه مند به کمک به شکل گیری این اکوسیستم هستید، لطفا نظرسنجی علاقه مندی را پر کنید.
نتیجه
ArchGym یک ورزشگاه منبع باز برای معماری ML DSE است و یک رابط استاندارد را فعال می کند که می تواند به راحتی برای موارد استفاده مختلف گسترش یابد. علاوه بر این، ArchGym مقایسه منصفانه و قابل تکرار بین الگوریتمهای مختلف ML را امکانپذیر میکند و به ایجاد خطوط پایه قویتر برای مشکلات تحقیقاتی معماری کامپیوتر کمک میکند.
ما از جامعه معماری کامپیوتر و همچنین جامعه ML دعوت می کنیم تا فعالانه در توسعه ArchGym شرکت کنند. ما بر این باوریم که ایجاد محیطی از نوع ورزشگاه برای تحقیقات معماری کامپیوتر، گامی مهم به جلو در این زمینه خواهد بود و بستری را برای محققان فراهم میکند تا از ML برای تسریع تحقیقات و هدایت به طرحهای جدید و نوآورانه استفاده کنند.
سپاسگزاریها
این وبلاگ بر اساس کار مشترک با چندین نویسنده مشترک در گوگل و دانشگاه هاروارد است. مایلیم Srivatsan Krishnan (هاروارد) را که با همکاری Shvetank Prakash (هاروارد)، Jason Jabbour (هاروارد)، Ikechukwu Uchendu (هاروارد)، Susobhan Ghosh (Harvardians) و Boroujerd (بهزادارد)، ایده های متعددی در این پروژه ارائه کرده است، قدردانی و برجسته کنیم. دانیل ریچینز (هاروارد)، دواشری تریپاتی (هاروارد)، و تیری تامبه (هاروارد). علاوه بر این، ما همچنین میخواهیم از جیمز لادون، داگلاس اک، کلیف یانگ و الکساندرا فاوست برای حمایت، بازخورد و انگیزهشان برای این کار تشکر کنیم. همچنین مایلیم از جان گیلارد برای فیگور متحرک استفاده شده در این پست تشکر کنیم. امیر یزدان بخش در حال حاضر دانشمند تحقیقاتی در گوگل دیپ مایند و ویجی جاناپا ردی دانشیار دانشگاه هاروارد هستند.