جای تعجب نیست که انعطاف پذیری ابری یکی از مهمترین کلمات کلیدی فناوری اطلاعات در دهه 2020 است. اطمینان از انعطاف پذیری در برابر حملات سایبری و اخاذی باج افزار، و همچنین توانایی بازیابی سریع از اختلالات فناوری اطلاعات، از ضروریات حیاتی سازمانهای امروزی است. بدون زیرساخت IT و برنامه کاربردی، فرآیندهای تجاری عملیاتی مستعد خرابی هستند.
همه ارائه دهندگان ابر بزرگ خدمات و ویژگی هایی را برای انعطاف پذیری ارائه می دهند. با این حال، هیچ CIO یا متخصص IT نباید فرض کند که انتقال همه بارهای کاری به ابر، انعطاف پذیری کامل را تضمین می کند. ابرها بلوک های سازنده را ارائه می دهند، نه آماده بازی با قلعه های افسانه ای. در عوض، معماران امنیتی و کارشناسان مدیریت تداوم کسب و کار باید ویژگی ها و خدمات را هوشمندانه ترکیب کنند.
شکل 1 نقشه راه راهنما را ارائه می دهد که چهار سناریو مرکزی برای انعطاف پذیری ابر را برجسته می کند:
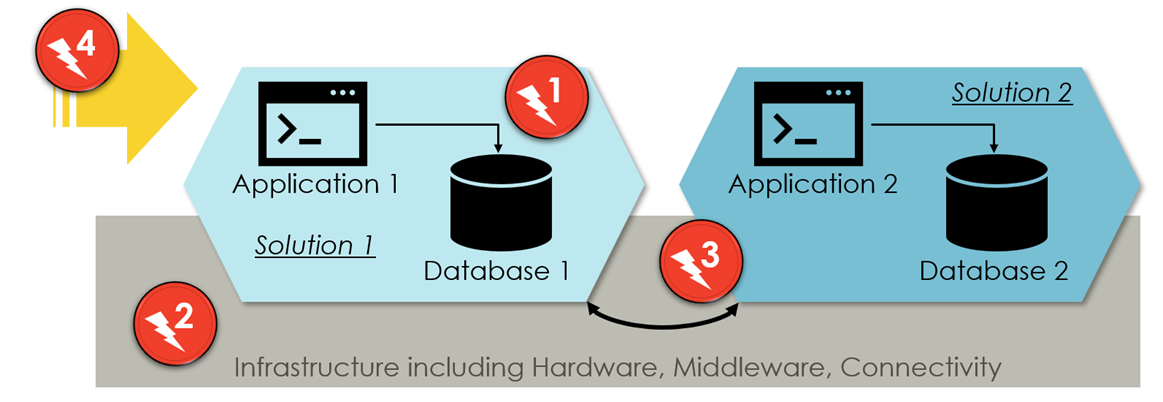
شکل 1 – سناریوهای انعطاف پذیری ابر
- راه حل-تاب آوری درونی (1) به چالشهای خراب شدن برنامهها یا پایگاههای داده بدون تأثیر رویدادها یا مسائل خارجی در زیرساخت زیربنایی یا تأثیر سایر مؤلفهها نگاه میکند.
- تاب آوری زیرساخت (2) به مشکلات موجود در لایه های سخت افزاری یا فناوری و شبکه می پردازد.
- انعطاف پذیری آبشار تصادف هدف (3) سرکوب اثرات دومینو است، به عنوان مثال، خرابی یک برنامه بر روی برنامه های دیگر تأثیر می گذارد.
- مقاومت در برابر حملات سایبری (4) برای مقابله با مهاجمان خارجی که به مستاجر مرکز داده ابری نفوذ می کنند.
سناریوی 1: راه حل-تاب آوری درونی
ریسکهای اصلی راهحل که انعطافپذیری داخلی باید پوشش دهد، خطاهای کدگذاری و پیکربندی، صور فلکی دادههای غیرمنتظره، و نیاز به منابع اوجگیری است.
تاب آوری در مورد حجم کار به اوج می رسد دستیابی در فضای ابری بسیار ساده تر است. اول، بستههای پلتفرم بهعنوان سرویس (PaaS) مانند Cosmos DB دارای ویژگیهای مقیاسپذیری خودکار هستند. دوم، در دنیای ابری زیرساخت بهعنوان یک سرویس (IaaS)، متعادلکنندههای بار همراه با گروههایی از ماشینهای مجازی (مثلاً مجموعه مقیاس ماشین مجازی لاجورد یا Amazon EC2 Auto Scaling) یک راه حل آسان برای پیاده سازی است. این رویکرد تضمین میکند که همیشه ماشینهای مجازی کافی وجود داشته باشد، با افزایش و کاهش بسته به تقاضا و جایگزینی ماشینهای مجازی خراب با ماشینهای جدید.
با چنین ویژگی های پیشگیرانه قدرتمندی، الگوی اصلاحی کلاسیک – افزایش یا جایگزینی سخت افزار و منابع، بازیابی نسخه پشتیبان و راه اندازی مجدد برنامه – به پس زمینه می رود.
اقدامات پیشگیرانه اصلی برای افزایش تاب آوری برای کد نویسی، پیکربندی، یا صورت فلکی داده مسائل تست بیشتر و طراحی نرم افزار بهتری دارند. اگر اشکالات وارد تولید شوند و باعث خرابی شوند، رفع اشکال و استقرار مجدد کد، اقدام اصلاحی کتاب درسی دانشگاه است. در حالی که برای خرابی های مکرر ضروری است، راه اندازی مجدد برنامه – “آیا سعی کرده اید دوباره آن را خاموش و روشن کنید؟” – یک اقدام تاکتیکی فوری برای برگرداندن برنامه به صورت آنلاین است. Scale Sets و خدمات مشابه این راهاندازیهای خوددرمانی را خودکار میکنند، اگرچه تیمهای برنامه باید خرابیهای مکرر را بررسی کنند. در نهایت، مثل همیشه، بازیابی یک نسخه پشتیبان آخرین گزینه است، خواه پیکربندی، داده یا کد برنامه.

شکل 2 – استراتژی های تاب آوری ابرهای پیشگیری، مهار و بازیابی
سناریوی 2: انعطاف پذیری زیرساخت
خرابیها در لایههای سختافزاری یا شبکه مانند چیزی از دهه 1980 به نظر میرسند، اما امروزه هنوز یک مشکل هستند. در دنیای IaaS، تیم های برنامه باید رسیدگی کنند خرابی ماشین مجازی و دیسک. راه اندازی مجدد دستی گزینه پیش فرض (بازیابی) است. با این حال، مجموعههای مقیاس (و خدمات مشابه) که قبلاً ذکر شد، اقدامات پیشگیرانه مناسبی در فضای ابری برای به حداقل رساندن احتمال خاموشی هستند.
این رویکرد برای سرویسهای PaaS مانند حسابهای ذخیرهسازی، سطلهای آمازون S3، DBaaS یا توابع Lambda متفاوت است. بسیاری از آنها گزینه های افزونگی مختلفی را به مشتریان ارائه می دهند تا از بین آنها یکی را انتخاب کنند. در حالت ایده آل، تیم پلتفرم ابری یک سازمان حداقل الزامات را برای محیط های تولید تعریف و اجرا می کند. سپس، تمام مسئولیت های عملیاتی با ارائه دهنده ابر است.
را شبکه لایه وجوه بیشتری دارد. مشتریان تصمیم میگیرند که چگونه اتصال بین ابرها (به عنوان مثال، مستأجران AWS و Google Cloud آنها) و بین مراکز داده اولیه و ابر را تنظیم کنند. آیا یک سازمان از طریق اینترنت یا سرویس قابل اعتمادتر GCP Cloud Interconnect با GCP متصل می شود؟ و اگر با Cloud Interconnect، آیا سازمان به یک حامل شبکه متکی است یا با دو یا چند شرکت شریک است؟ مشتری تصمیم می گیرد. آنها همچنین مسیریابی و سرویس های DNS خود را تنظیم می کنند. با این حال، آنها به طور کامل به ارائه دهنده ابر در مورد لایه های پایین تر ستون فقرات شبکه و اتصال در مراکز داده متکی هستند.
سناریو 3: تاب آوری آبشارها سقوط می کند
انعطافپذیری آبشار تصادف به این ضرورت پاسخ میدهد که خرابی یک برنامه نباید بر برنامههای دیگر تأثیر بگذارد، در نتیجه باعث خرابی برنامههای آبشاری به سبک دومینو میشود. به عنوان مثال، یک بانک باید اطمینان حاصل کند که مسائل در سیستم بانکداری اصلی بر راه حل ATM تأثیر نمی گذارد، که برداشت پول از مشتریان در سراسر جهان را به صورت بلادرنگ، 24/7 تأیید می کند (یا رد می کند). با این حال، معماران و مدیران باید درک کنند که محدودیتهای واضحی وجود دارد.
الگوهای تاب آوری می توانند در این زمینه زمان بخرند – شاید پنج دقیقه، پنج ساعت یا پنج روز. شرط این است که برنامه قبل از اینکه روی دیگران تأثیر بگذارد دوباره آنلاین شود. مانند مثال برداشت پول، چنین الگوهایی تنها می توانند راه حل های موقتی باشند. هیچ برنامه ATM نمی تواند هفته ها بدون به روز رسانی موجودی حساب مشتری و تغییرات امتیازدهی اعتباری کار کند.
یک الگوی پیاده سازی ساده است: الگوهای ادغام ناهمزمان برای تعاملات برنامه، به عنوان مثال، فرآیندهای دسته ای، صف های پیام، و pub-sub. در مقابل، فراخوانی های API (Rest-) به سادگی شیطانی هستند. آنها باعث می شوند که برنامه ها با شکست مواجه شوند حتی اگر سیستم طرف مقابل فقط برای یک ثانیه از کار بیفتد (یا برنامه ها باید منطق پیچیده مدیریت خرابی را پیاده سازی کنند). فقط یک پاورقی حیاتی برای الگوهای ادغام ناهمزمان وجود دارد. آنها معمولاً به میان افزار (پیام رسانی) متکی هستند. در دسترس بودن این میان افزار برای چشم انداز کلی برنامه حیاتی است.
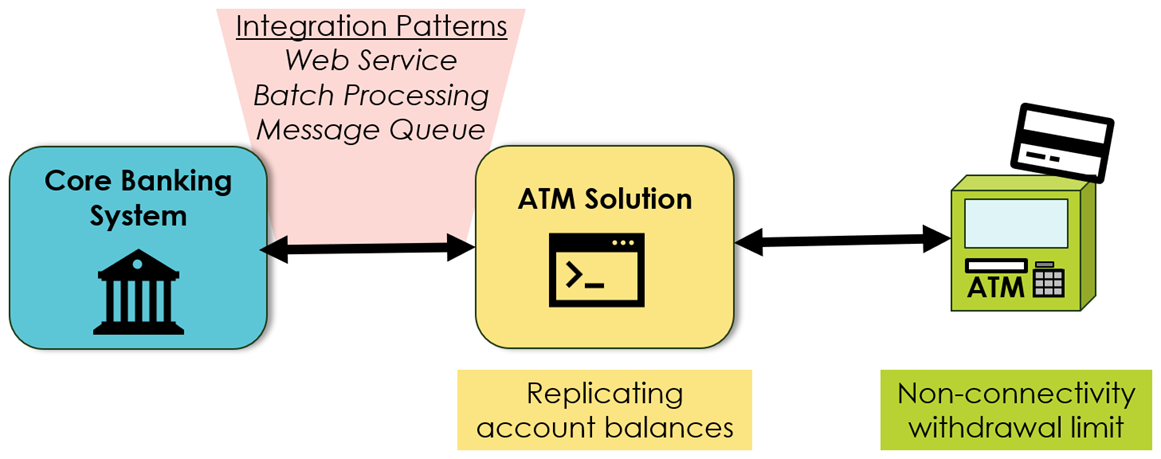
شکل 3 – خرابی های آبشاری و مثال ATM
در پایان، ابر تغییر دهنده بازی برای این سناریوی انعطافپذیری نیست، اگرچه ابرها میانافزار آماده برای استفاده را فراهم میکنند و محدودیتهای اتصال ناخواسته و مستقیم بین برنامهای را کاهش میدهند، که برنامهها را مجبور به استفاده از دروازههای میانافزار میکند. علاوه بر این، انعطافپذیری در برابر آبشارهای تصادف، مختص برنامههای کاربردی است و حتی تا حدی یک موضوع فناوری اطلاعات و بیشتر یک موضوع طراحی تجاری است. آیا کسبوکار به راهکارهای خودپرداز اجازه میدهد در صورت از کار افتادن سیستم بانکی مرکزی، برداشتهای نقدی را بر اساس دادههای دیروز تأیید کند؟ آیا حتی اگر دستگاه خودپرداز نتواند به راه حل ATM برسد، برداشت محدود امکان پذیر است؟ تنها کسب و کار، با همکاری فناوری اطلاعات، می تواند چنین منطق تجاری را تعریف کند، که می تواند به طور گسترده به ثبات کلی اکوسیستم برنامه کمک کند.
سناریو 4: مقاومت در برابر حملات سایبری
مقاومت در برابر حملات سایبری چهارمین و آخرین سناریو در اینجا است. متخصصان امنیت سایبری و CISO برای چندین دهه بر روی این مشکل کار کرده اند. بنابراین، بسیاری از سازمان ها در حال حاضر ابزارها و فرآیندهای بالغی را در اختیار دارند.
پیشگیری کردن و تشخیص حملات سایبری شامل سختسازی سیستم، تست نفوذ، کنترل دسترسی، حفاظت از بدافزار و سیستمهای تشخیص نفوذ است. ابرها دارای ویژگیهای مختلفی هستند که مشتریان میتوانند به سرعت آنها را فعال کنند، که اجرای کنترلهای امنیتی را در مقایسه با دنیای قدیمی و قدیمی افزایش میدهد.
برای مهاردو رویکرد مکمل وجود دارد: جداسازی ناحیه و تشخیص و پاسخ نقطه پایانی E (EDR). ابزارهای EDR لپتاپها، سرورها و ماشینهای مجازی آلوده را جدا و قرنطینه میکنند. متقابلا، جداسازی مناطق شبکه یک رویکرد دیوار تقسیم آتش با هدف جلوگیری از حرکت جانبی با خاموش کردن اتصال است. بنابراین، اگر شبکه یک شرکت در استرالیا به خطر بیفتد، آنها اتصال به مناطق شبکه سنگاپور و سوئیس را قطع می کنند. سپس، مهندسان قبل از برقراری مجدد اتصال با سنگاپور و سوئیس، سرورها را در استرالیا تمیز می کنند. این یک رویکرد محکم است، اما تنها در صورتی که برنامه ها و کسب و کار خیلی در هم تنیده نشده باشند.
پس از مهار فرا می رسد بهبودیعنی بازیابی حالت قبل از حمله از پشتیبان گیری یا استقرار مجدد برنامه ها با خطوط لوله CI/CD. با این حال، شرکت ها باید آگاه باشند که مهاجمان در مورد پشتیبان گیری اطلاعات دارند و سعی می کنند آنها را حذف کنند. بنابراین، پشتیبانگیری غیرقابل تغییر یک ضرورت است، یعنی پشتیبانهایی که هیچکس نمیتواند حذف کند، حتی مدیران. برای پیچیده تر کردن مسائل، در حالی که ابزارهای مهار و بازیابی “بالغ” هستند، پوشش برای بارهای کاری غیر VM – کانتینرها و خدمات بومی ابری مانند AWS Lambda یا AWS S3 Buckets – می تواند محدود شود.
نتیجه
کاوش ما در چهار سناریو حیاتی – انعطافپذیری داخلی راهحل، انعطافپذیری زیرساخت، انعطافپذیری آبشارهای تصادف و انعطافپذیری حملات سایبری – روش چندوجهی برای پیادهسازی مناظر فناوری اطلاعات و برنامههای کاربردی واقعاً انعطافپذیر را نشان میدهد.
در حالی که ابر عمومی وقتی به دنبال افزونگی و ابزارهای امنیتی سریع فعال میشوند، تسکین میدهد، جلوگیری از خرابی برنامههای آبشاری به سبک دومینو همچنان در معماریهای برنامههای جداگانه باقی میماند. طراحی اپلیکیشن و فرآیندهای تجاری آنها تصمیم میگیرد که آیا جدا شدن موقت از سایر برنامهها و محافظت از آنها در برابر خرابیهای خارجی امکانپذیر است یا خیر – یک کابوس برای مدیرانی که امیدوار به راهحلهای سریع هستند، یک رویا برای معماران جاهطلبی که دوست دارند روی چالشهای واقعی کار کنند.