
هنگام ساخت مدلهای یادگیری ماشین برای برنامههای کاربردی واقعی، باید ورودیهای چند روش را در نظر بگیریم تا بتوانیم جنبههای مختلف دنیای اطراف خود را به تصویر بکشیم. به عنوان مثال، صدا، ویدئو و متن همگی اطلاعات متنوع و مکملی را در مورد یک ورودی بصری ارائه می دهند. با این حال، ساخت مدلهای چندوجهی به دلیل ناهمگونی روشها چالش برانگیز است. برخی از روش ها ممکن است به خوبی در زمان همگام شوند (مثلاً صدا، ویدیو) اما با متن هماهنگ نباشند. علاوه بر این، حجم زیاد داده در سیگنالهای ویدئویی و صوتی بسیار بیشتر از متن است، بنابراین هنگام ترکیب آنها در مدلهای چندوجهی، ویدئو و صدا اغلب نمیتوانند به طور کامل مصرف شوند و نیاز به فشردهسازی نامتناسب دارند. این مشکل برای ورودی های ویدیویی طولانی تر تشدید می شود.
در “Mirasol3B: یک مدل خودرگرسیون چندوجهی برای مدالیتههای همسو با زمان و زمینهای”، ما یک مدل خودرگرسیون چندوجهی (Mirasol3B) را برای یادگیری در روشهای صوتی، تصویری و متنی معرفی میکنیم. ایده اصلی این است که مدلسازی چندوجهی را به مدلهای خودرگرسیون متمرکز جداگانه جدا کنیم و ورودیها را بر اساس ویژگیهای روشها پردازش کنیم. مدل ما متشکل از یک مؤلفه اتورگرسیو برای مدالیتههای همگامسازی زمانی (صوتی و ویدیویی) و یک مؤلفه اتورگرسیو جداگانه برای مدالیتههایی است که لزوماً همتراز با زمان نیستند، اما همچنان متوالی هستند، به عنوان مثال، ورودیهای متن، مانند عنوان یا توضیحات. علاوه بر این، روشهای همسو با زمان در زمان تقسیم میشوند که ویژگیهای محلی را میتوان به طور مشترک یاد گرفت. به این ترتیب ورودی های صوتی-تصویری به موقع مدل می شوند و پارامترهای نسبتاً بیشتری نسبت به کارهای قبلی به آنها اختصاص می یابد. با این رویکرد، میتوانیم بدون زحمت ویدیوهای بسیار طولانیتری (مثلاً 128-512 فریم) در مقایسه با سایر مدلهای چندوجهی مدیریت کنیم. در پارامترهای 3B، Mirasol3B در مقایسه با مدلهای قبلی فلامینگو (80B) و PaLI-X (55B) فشرده است. در نهایت، Mirasol3B از رویکردهای پیشرفته در پاسخگویی به سؤالات ویدیویی (ویدئو QA)، کیفیت کیفیت ویدیوی طولانی، و معیارهای صوتی-تصویری-متن بهتر عمل می کند.
 |
| معماری Mirasol3B متشکل از یک مدل اتورگرسیو برای مدالیتههای همتراز با زمان (صوتی و تصویری)، که به صورت تکهای تقسیمبندی شدهاند، و یک مدل اتورگرسیو جداگانه برای مدالیتههای زمینه بدون تراز (مثلاً متن) است. یادگیری ویژگی های مشترک توسط Combiner انجام می شود، که ویژگی های فشرده اما به اندازه کافی آموزنده را یاد می گیرد و امکان پردازش ورودی های ویدیویی/صوتی طولانی را فراهم می کند. |
هماهنگی روشهای همسو با زمان و زمینه
ویدئو، صوت و متن روش های متنوعی با ویژگی های متمایز هستند. برای مثال، ویدئو یک سیگنال بصری مکانی-زمانی با 30-100 فریم در ثانیه است، اما به دلیل حجم زیاد داده، معمولاً فقط 32-64 فریم است. در هر ویدیو توسط مدل های فعلی مصرف می شوند. صدا یک سیگنال زمانی یک بعدی است که با فرکانس بسیار بالاتر از ویدئو (مثلاً 16 هرتز) به دست میآید، در حالی که ورودیهای متنی که برای کل ویدیو اعمال میشود، معمولاً 200 تا 300 توالی کلمه هستند و به عنوان زمینهای برای صدا عمل میکنند. ورودی های ویدئویی برای این منظور، ما مدلی متشکل از یک مؤلفه اتورگرسیو را پیشنهاد میکنیم که سیگنالهای همسو با زمان را که در فرکانسهای بالا رخ میدهند و تقریباً همگامسازی میشوند، ترکیب میکند و به طور مشترک یاد میگیرد، و یک مؤلفه خودرگرسیون دیگر برای پردازش سیگنالهای غیر تراز. یادگیری بین مؤلفهها برای روشهای همسو با زمانی و زمینهای از طریق مکانیسمهای توجه متقابل هماهنگ میشود که به این دو اجازه میدهد در حین یادگیری در یک دنباله اطلاعات را بدون نیاز به همگامسازی در زمان، تبادل کنند.
مدلسازی خودرگرسیون همتراز با زمان ویدئو و صدا
ویدئوهای طولانی میتوانند اطلاعات و فعالیتهای غنی را که به صورت متوالی اتفاق میافتند، منتقل کنند. با این حال، مدلهای کنونی با استخراج همه اطلاعات به صورت یکجا، بدون اطلاعات زمانی کافی، به مدلسازی ویدیویی نزدیک میشوند. برای پرداختن به این موضوع، ما یک استراتژی مدلسازی خودرگرسیون را اعمال میکنیم که در آن بازنماییهای ویدیویی و صوتی مشترکی را برای یک بازه زمانی در بازنمایی ویژگیهای بازههای زمانی قبلی شرطی میکنیم. این اطلاعات زمانی را حفظ می کند.
ویدئو ابتدا به تکه های ویدئویی کوچکتر تقسیم می شود. هر قطعه خود می تواند 4 تا 64 فریم باشد. سپس ویژگیهای مربوط به هر قطعه توسط یک ماژول یادگیری به نام Combiner پردازش میشود (که در زیر توضیح داده شده است)، که یک نمایش ویژگی صوتی و تصویری مشترک در مرحله فعلی ایجاد میکند – این مرحله مهمترین اطلاعات را در هر قطعه استخراج و فشرده میکند. در مرحله بعد، این نمایش ویژگی مشترک را با یک ترانسفورماتور اتورگرسیو پردازش می کنیم، که توجه را به نمایش ویژگی قبلی اعمال می کند و نمایش ویژگی مشترک را برای مرحله بعدی ایجاد می کند. در نتیجه، مدل یاد میگیرد که چگونه نه تنها تک تک تکهها را نشان دهد، بلکه میآموزد که چگونه تکهها به صورت زمانی ارتباط دارند.
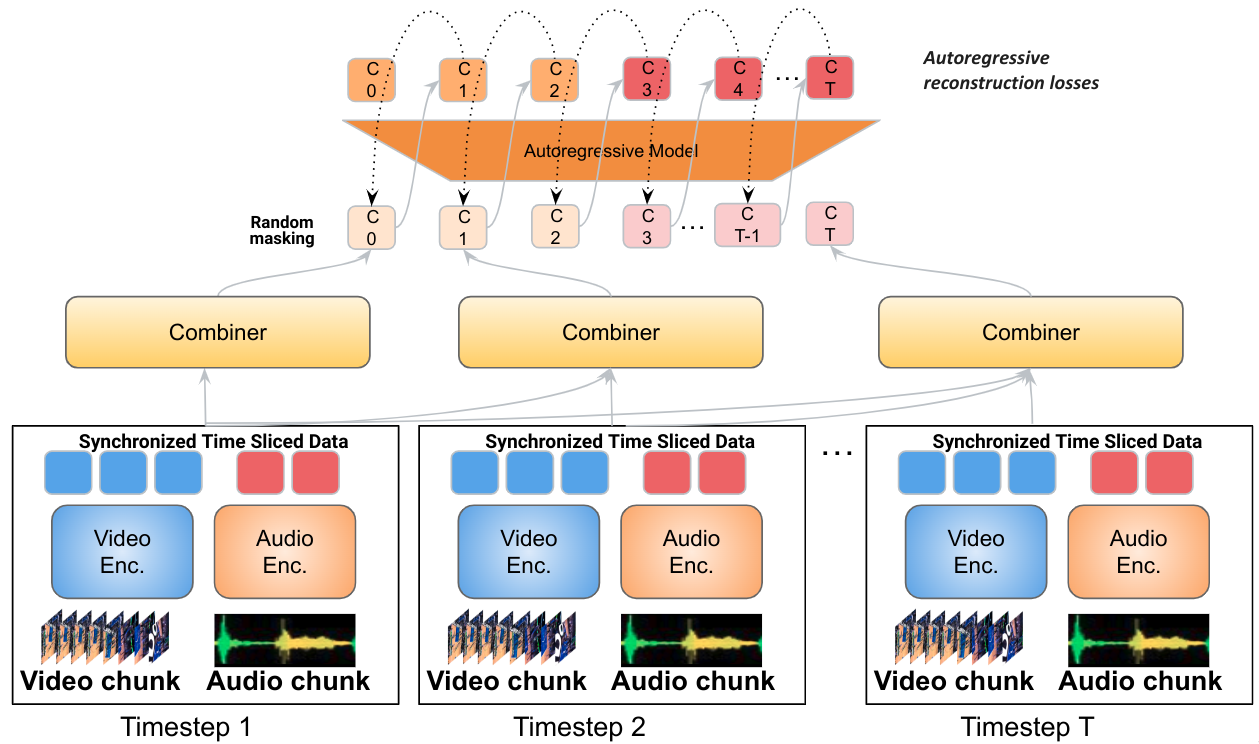 |
| ما از یک مدلسازی اتورگرسیو ورودیهای صوتی و تصویری استفاده میکنیم، آنها را در زمان پارتیشن بندی میکنیم و نمایش ویژگیهای مشترک را یاد میگیریم، که سپس بهطور خودرگرسیون به ترتیب یاد میگیریم. |
مدل سازی ویدیوهای طولانی با ترکیب کننده مدالیته
برای ترکیب سیگنالها از اطلاعات ویدیویی و صوتی در هر قطعه ویدیو، ما یک ماژول یادگیری به نام Combiner را پیشنهاد میکنیم. سیگنالهای صوتی و تصویری با گرفتن ورودیهای صوتی که با یک بازه زمانی خاص ویدیو مطابقت دارند، تراز میشوند. سپس ورودیهای صوتی و تصویری را بهصورت مکانی-زمانی پردازش میکنیم و اطلاعات مربوط به آن را استخراج میکنیم تغییرات در ورودی ها (برای ویدیوها از لولههای ویدیویی پراکنده استفاده میکنیم و برای صدا از نمایش طیفنگاری استفاده میکنیم که هر دو توسط یک Vision Transformer پردازش میشوند). ما این ویژگیها را به Combiner متصل کرده و وارد میکنیم، که برای یادگیری یک نمایش ویژگی جدید طراحی شده است که هر دو این ورودیها را ثبت میکند. برای رفع چالش حجم زیاد داده در سیگنالهای ویدیویی و صوتی، هدف دیگر Combiner کاهش ابعاد ورودیهای مشترک تصویر/صوت است که با انتخاب تعداد کمتری از ویژگیهای خروجی برای تولید انجام میشود. Combiner را می توان به سادگی به عنوان یک ترانسفورماتور علّی پیاده سازی کرد، که ورودی ها را در جهت زمان پردازش می کند، یعنی فقط با استفاده از ورودی های مراحل قبلی یا فعلی. از طرف دیگر، Combiner می تواند حافظه قابل یادگیری داشته باشد که در زیر توضیح داده شده است.
سبک های ترکیبی
یک نسخه ساده از Combiner معماری Transformer را تطبیق می دهد. به طور خاص، تمام ویژگیهای صوتی و تصویری از قطعه فعلی (و به صورت اختیاری تکههای قبلی) به یک ترانسفورماتور وارد میشوند و به ابعاد کمتری پیشبینی میشوند، یعنی تعداد کمتری از ویژگیها به عنوان ویژگیهای «ترکیب» خروجی انتخاب میشوند. در حالی که ترانسفورماتورها معمولاً در این زمینه استفاده نمی شوند، ما آن را برای کاهش ابعاد ویژگی های ورودی، با انتخاب آخرین مورد موثر می دانیم. متر خروجی ترانسفورماتور، اگر متر بعد خروجی مورد نظر است (در زیر نشان داده شده است). از طرف دیگر، Combiner می تواند یک جزء حافظه داشته باشد. به عنوان مثال، ما از ماشین تورینگ توکن (TTM) استفاده می کنیم که از یک واحد حافظه قابل تفکیک پشتیبانی می کند و ویژگی های تمام مراحل قبلی را جمع آوری و فشرده می کند. استفاده از یک حافظه ثابت به مدل این امکان را میدهد که در هر مرحله با مجموعهای از ویژگیهای فشردهتر کار کند، نه اینکه تمام ویژگیهای مراحل قبلی را پردازش کند، که محاسبات را کاهش میدهد.
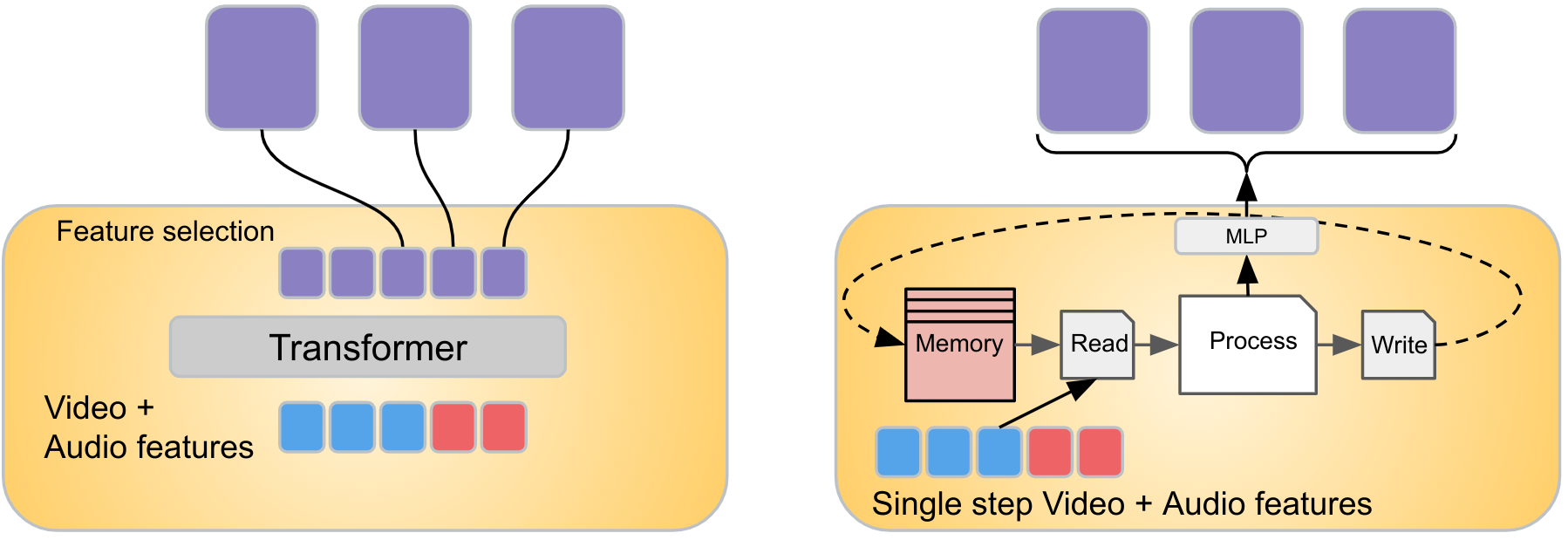 |
| ما از یک Combiner ساده مبتنی بر ترانسفورماتور (ترک کرد) و یک ترکیب کننده حافظه (درستبر اساس ماشین تورینگ توکن (TTM)، که از حافظه برای فشردهسازی تاریخچه قبلی ویژگیها استفاده میکند. |
نتایج
ما رویکرد خود را بر روی چندین معیار، MSRVTT-QA، ActivityNet-QA و NeXT-QA، برای تکلیف QA ویدیو، که در آن یک سؤال مبتنی بر متن در مورد یک ویدیو صادر میشود و مدل باید به آن پاسخ دهد، ارزیابی میکنیم. این توانایی مدل را برای درک هر دو سؤال مبتنی بر متن و محتوای ویدیویی و ایجاد پاسخ، با تمرکز تنها بر اطلاعات مرتبط ارزیابی می کند. از بین این معیارها، دو مورد آخر ورودیهای ویدیویی طولانی را هدف قرار میدهند و سوالات پیچیدهتری دارند.
ما همچنین رویکرد خود را در محیط چالشبرانگیزتر تولید متن با پایان باز ارزیابی میکنیم، که در آن مدل پاسخها را به شکلی نامحدود به صورت متن آزاد تولید میکند، که نیاز به تطابق دقیق با پاسخ حقیقت پایه دارد. در حالی که این ارزیابی دقیق تر مترادف ها را نادرست به حساب می آورد، ممکن است توانایی یک مدل را برای تعمیم بهتر منعکس کند.
نتایج ما نشاندهنده عملکرد بهبود یافته نسبت به رویکردهای پیشرفته برای اکثر معیارها، از جمله همه با ارزیابی نسل باز است – قابل توجه با توجه به اینکه مدل ما فقط پارامترهای 3B است، به طور قابلتوجهی کوچکتر از رویکردهای قبلی، به عنوان مثال، Flamingo 80B. ما فقط از ورودی های ویدئو و متن استفاده کردیم تا با کارهای دیگر قابل مقایسه باشد. نکته مهم این است که مدل ما میتواند 512 فریم را بدون نیاز به افزایش پارامترهای مدل پردازش کند، که برای مدیریت ویدیوهای طولانیتر بسیار مهم است. در نهایت با TTM Combiner، ما شاهد عملکرد بهتر یا قابل مقایسه با کاهش 18 درصدی محاسبه هستیم.
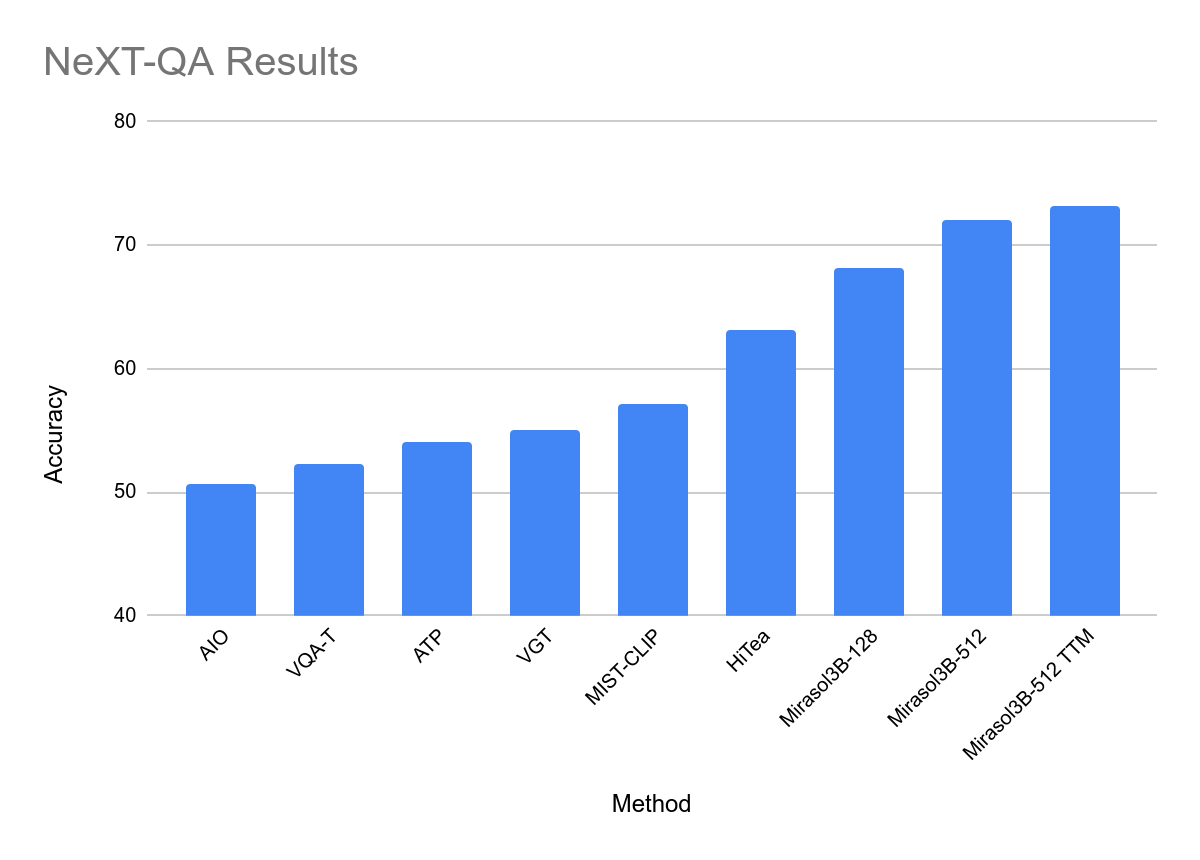 |
| نتایج در معیار NeXT-QA، که دارای ویدیوهای طولانی برای وظیفه QA ویدیویی است. |
نتایج در مورد معیارهای صوتی و تصویری
نتایج مجموعه دادههای صوتی-تصویری محبوب VGG-Sound و EPIC-SOUNDS در زیر نشان داده شده است. از آنجایی که این معیارها فقط طبقه بندی هستند، ما آنها را به عنوان یک تنظیم متن باز تولید می کنیم که در آن مدل ما متن کلاس مورد نظر را تولید می کند. به عنوان مثال، برای شناسه کلاس مربوط به فعالیت “درام نواختن”، انتظار داریم که مدل متن “درام نواختن” را تولید کند. در برخی موارد، رویکرد ما با حاشیههای زیادی از وضعیت قبلی پیشی میگیرد، حتی اگر مدل ما نتایج را در یک محیط باز تولیدی خروجی میدهد.
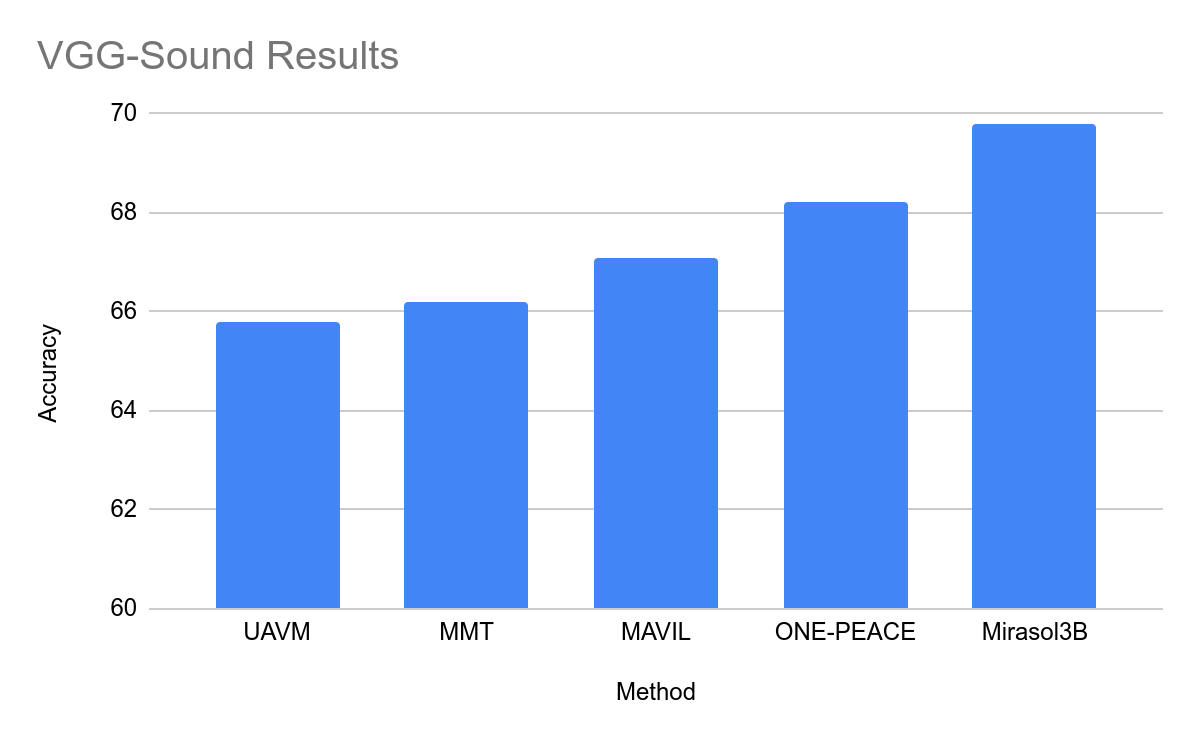 |
| نتایج مربوط به مجموعه داده VGG-Sound (کیفیت صوتی و تصویری). |
مزایای مدل سازی اتورگرسیو
ما یک مطالعه فرسایشی انجام میدهیم که رویکرد خود را با مجموعهای از خطوط پایه مقایسه میکند که از اطلاعات ورودی یکسان اما با روشهای استاندارد (یعنی بدون خودرگرسیون و ترکیبکننده) استفاده میکنند. ما همچنین اثرات قبل از تمرین را با هم مقایسه می کنیم. از آنجایی که روشهای استاندارد برای پردازش ویدیوی طولانیتر مناسب نیستند، این آزمایش فقط برای 32 فریم و چهار تکه، در همه تنظیمات برای مقایسه منصفانه انجام میشود. می بینیم که پیشرفت های Mirasol3B هنوز برای ویدیوهای نسبتاً کوتاه معتبر است.
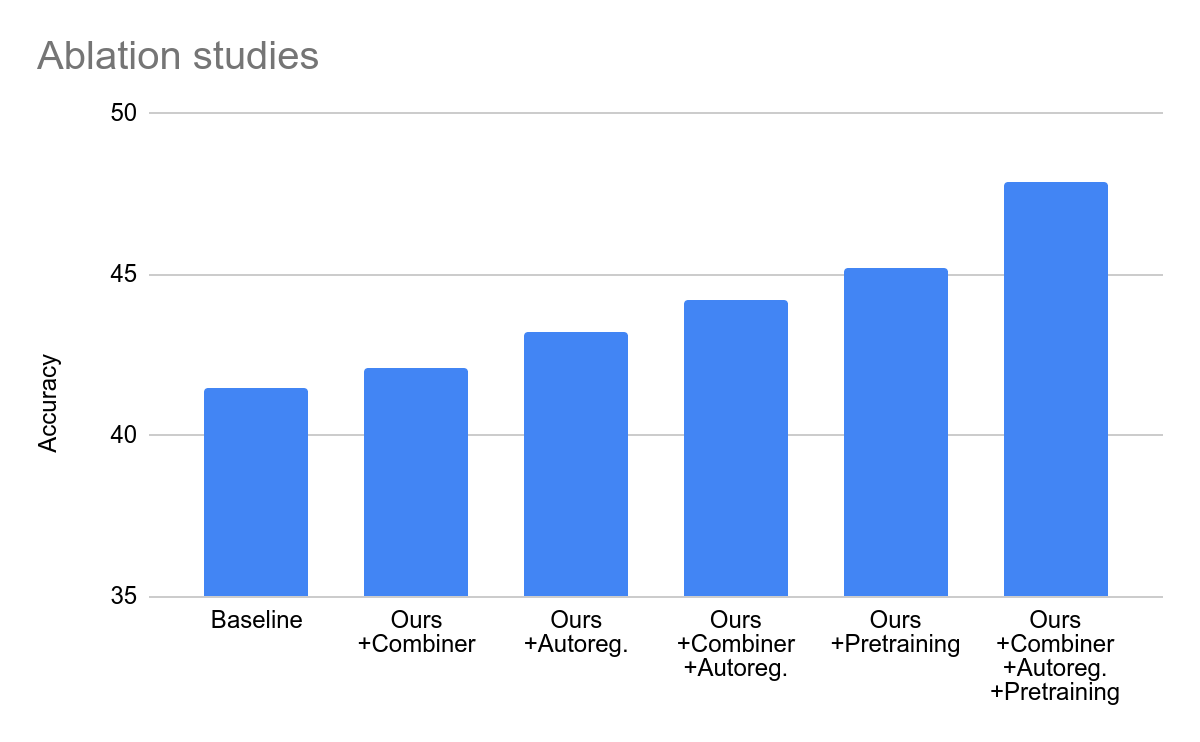 |
| آزمایشهای فرسایشی با مقایسه اجزای اصلی مدل ما. استفاده از Combiner، مدلسازی اتورگرسیو و پیشآموزش همگی عملکرد را بهبود میبخشند. |
نتیجه
ما یک مدل خودرگرسیون چندوجهی را ارائه میدهیم که چالشهای مرتبط با ناهمگونی دادههای چندوجهی را با هماهنگ کردن یادگیری بین روشهای همتراز با زمان و ناهمسو با زمان بررسی میکند. مدالیتههای همتراز با زمان، بهطور خودکار در زمان با یک Combiner پردازش میشوند و طول توالی را کنترل میکنند و نمایشهای قدرتمندی تولید میکنند. ما نشان میدهیم که یک مدل نسبتاً کوچک میتواند ویدیوی طولانی را با موفقیت نشان دهد و به طور مؤثر با سایر روشها ترکیب شود. ما از روشهای پیشرفته (از جمله برخی مدلهای بسیار بزرگتر) در پاسخگویی به سؤالات ویدیویی و صوتی و تصویری بهتر عمل میکنیم.
سپاسگزاریها
این تحقیق توسط AJ Piergiovanni، Isaac Noble، Dahun Kim، Michael Ryoo، Victor Gomes و Anelia Angelova نوشته شده است. از کلر کوی، تانیا بدراکس-وایس، ابهیجیت اوگال، یون سوان سونگ، چینگ چونگ چانگ، ماروین ریتر، کریستینا توتانوا، مینگ وی چانگ، آشیش تاپلیال، ژیانگ لو، وایچنگ کو، آرن جانسن، برایان سیبولد، ابراهیمسین آلاب، سپاسگزاریم. جیالین وو، لوک فریدمن، ترور واکر، کیرتانا گوپالاکریشنان، جیسون بالدریج، رادو سوریکوت، مجتبی سیدحسینی، الکساندر دامور، الیور وانگ، پل ناتسف، تام دوریگ، یونگهوی وو، اسلاو پتروف، زوبین قهرمانی و حمایت از آنها. همچنین از تام اسمال برای تهیه انیمیشن تشکر می کنیم.