
در چند سال گذشته پیشرفت سریعی در سیستم هایی مشاهده شده است که می توانند به طور خودکار اسناد پیچیده تجاری را پردازش کرده و آنها را به اشیاء ساختاریافته تبدیل کنند. سیستمی که میتواند به طور خودکار دادهها را از اسناد استخراج کند، به عنوان مثال، رسیدها، مظنه بیمه و صورتهای مالی، این پتانسیل را دارد که با اجتناب از کار دستی مستعد خطا، کارایی جریانهای کاری را بهطور چشمگیری بهبود بخشد. مدل های اخیر، بر اساس معماری ترانسفورماتور، دستاوردهای چشمگیری در دقت نشان داده اند. مدلهای بزرگتر مانند PalM 2 نیز برای سادهسازی بیشتر این جریانهای کاری مورد استفاده قرار میگیرند. با این حال، مجموعه دادههای مورد استفاده در ادبیات دانشگاهی نمیتوانند چالشهایی را که در موارد استفاده در دنیای واقعی مشاهده میشود، به تصویر بکشند. در نتیجه، معیارهای آکادمیک دقت مدل قوی را گزارش میکنند، اما همین مدلها وقتی برای برنامههای پیچیده دنیای واقعی استفاده میشوند ضعیف عمل میکنند.
در «VRDU: معیاری برای درک سند غنی از بصری»، ارائه شده در KDD 2023، انتشار مجموعه داده جدید درک سند غنی بصری (VRDU) را اعلام می کنیم که هدف آن پر کردن این شکاف و کمک به محققان برای ردیابی بهتر پیشرفت در وظایف درک سند است. . ما بر اساس انواع اسناد دنیای واقعی که اغلب از مدلهای درک سند برای آنها استفاده میشود، پنج الزام برای یک معیار درک خوب سند را فهرست میکنیم. سپس، توضیح میدهیم که چگونه اکثر مجموعه دادههایی که در حال حاضر توسط جامعه تحقیقاتی استفاده میشوند، یک یا چند مورد از این الزامات را برآورده نمیکنند، در حالی که VRDU همه آنها را برآورده میکند. ما مشتاقیم که انتشار عمومی مجموعه داده VRDU و کد ارزیابی را تحت مجوز Creative Commons اعلام کنیم.
الزامات معیار
ابتدا، دقت مدل پیشرفته (مثلاً با FormNet و LayoutLMv2) را در موارد استفاده در دنیای واقعی با معیارهای آکادمیک (مانند FUNSD، CORD، SROIE) مقایسه کردیم. ما مشاهده کردیم که مدلهای پیشرفته با نتایج معیار آکادمیک مطابقت ندارند و دقت بسیار پایینتری در دنیای واقعی ارائه میدهند. در مرحله بعد، مجموعه دادههای معمولی را که مدلهای درک سند برای آنها اغلب با معیارهای آکادمیک استفاده میشوند، مقایسه کردیم و پنج مورد نیاز مجموعه داده را شناسایی کردیم که به یک مجموعه داده اجازه میدهد تا پیچیدگی برنامههای کاربردی دنیای واقعی را بهتر به تصویر بکشد:
- طرحواره غنی: در عمل، ما شاهد تنوع گسترده ای از طرحواره های غنی برای استخراج ساختاریافته هستیم. موجودیت ها انواع داده های مختلفی دارند (عددی، رشته ها، تاریخ ها، و غیره) که ممکن است مورد نیاز، اختیاری، یا تکرار در یک سند واحد باشند یا حتی ممکن است تو در تو باشند. وظایف استخراج بیش از طرحواره های مسطح ساده مانند (سرصفحه، سوال، پاسخ) منعکس کننده مشکلات معمولی نیستند که در عمل با آن مواجه می شوند.
- اسناد غنی از چیدمان: اسناد باید دارای عناصر چیدمان پیچیده باشند. چالشها در تنظیمات عملی از این واقعیت ناشی میشوند که اسناد ممکن است شامل جداول، جفتهای کلید-مقدار، جابهجایی بین طرحبندی تک ستونی و دو ستونی، دارای اندازه فونتهای مختلف برای بخشهای مختلف، شامل تصاویر با شرح و حتی پاورقی باشد. این را با مجموعههای دادهای که بیشتر اسناد در جملات، پاراگرافها و فصلها با سرصفحههای بخش سازماندهی میشوند مقایسه کنید – انواع اسنادی که معمولاً تمرکز ادبیات کلاسیک پردازش زبان طبیعی روی ورودیهای طولانی هستند.
- قالب های متنوع: یک معیار باید شامل طرحبندیها یا قالبهای ساختاری مختلف باشد. برای یک مدل با ظرفیت بالا، استخراج از یک الگوی خاص با به خاطر سپردن ساختار، امری بی اهمیت است. با این حال، در عمل، فرد باید بتواند به الگوها/طرحبندیهای جدید تعمیم دهد، توانایی که تقسیم آزمون قطار در یک معیار باید آن را اندازهگیری کند.
- OCR با کیفیت بالا: اسناد باید دارای نتایج تشخیص کاراکتر نوری (OCR) با کیفیت بالا باشند. هدف ما از این معیار تمرکز بر روی خود وظیفه VRDU و حذف تغییرپذیری ناشی از انتخاب موتور OCR است.
- حاشیه نویسی در سطح نشانه: اسناد باید حاوی حاشیهنویسیهای واقعی باشند که میتوانند به متن ورودی مربوطه نگاشت شوند، به طوری که هر نشانه میتواند به عنوان بخشی از موجودیت مربوطه حاشیهنویسی شود. این در تضاد با ارائه متن مقداری است که باید برای موجودیت استخراج شود. این کلید برای تولید دادههای تمرینی تمیز است که در آن نیازی نیست نگران تطابقات تصادفی با مقدار داده شده باشیم. به عنوان مثال، در برخی از رسیدها، فیلد «کل قبل از مالیات» ممکن است همان مقدار فیلد «کل» باشد اگر مقدار مالیات صفر باشد. داشتن حاشیه نویسی در سطح نشانه، ما را از تولید داده های آموزشی که در آن هر دو نمونه از مقدار تطبیق به عنوان حقیقت پایه برای فیلد “کل” علامت گذاری شده اند، جلوگیری می کند، بنابراین نمونه های پر سر و صدا تولید می شود.
 |
مجموعه داده ها و وظایف VRDU
مجموعه داده VRDU ترکیبی از دو مجموعه داده عمومی در دسترس است، فرم های ثبت نام و فرم های آگهی خرید. این مجموعه دادهها نمونههایی را ارائه میدهند که نشاندهنده موارد استفاده در دنیای واقعی هستند و پنج الزامات معیار توصیف شده در بالا را برآورده میکنند.
مجموعه داده Forms Ad-buy شامل 641 سند با جزئیات تبلیغات سیاسی است. هر سند یا یک فاکتور یا رسید است که توسط یک ایستگاه تلویزیونی و یک گروه کمپین امضا شده است. اسناد از جداول، چند ستون و جفتهای کلید-مقدار برای ثبت اطلاعات آگهی مانند نام محصول، تاریخ پخش، قیمت کل و تاریخ و زمان انتشار استفاده میکنند.
مجموعه داده فرم های ثبت شامل 1915 سند با اطلاعاتی در مورد عوامل خارجی ثبت شده در دولت ایالات متحده است. هر سند اطلاعات ضروری در مورد عوامل خارجی درگیر در فعالیت هایی که نیاز به افشای عمومی دارند را ثبت می کند. محتویات شامل نام ثبتکننده، آدرس دفاتر مرتبط، هدف فعالیتها و سایر جزئیات است.
ما نمونهای تصادفی از اسناد را از سایتهای کمیسیون عمومی ارتباطات فدرال (FCC) و قانون ثبت نمایندگان خارجی (FARA) جمعآوری کردیم و تصاویر را با استفاده از OCR Google Cloud به متن تبدیل کردیم. تعداد کمی از اسناد را که چندین صفحه بودند دور انداختیم و پردازش در کمتر از دو دقیقه کامل نشد. این همچنین به ما امکان داد از ارسال اسناد بسیار طولانی برای حاشیه نویسی دستی اجتناب کنیم – کاری که برای یک سند ممکن است بیش از یک ساعت طول بکشد. سپس، طرح و دستورالعملهای برچسبگذاری متناظر را برای تیمی از حاشیهنویسان با تجربه در وظایف برچسبگذاری سند تعریف کردیم.
به حاشیه نویسان نیز چند نمونه سند با برچسب ارائه شد که ما خودمان آنها را برچسب گذاری کردیم. این کار مستلزم آن بود که حاشیه نویس ها هر سند را بررسی کنند، یک کادر محدود در اطراف هر رخداد یک موجودیت از طرح هر سند ترسیم کنند، و آن کادر محدود کننده را با موجودیت هدف مرتبط کنند. پس از اولین دور برچسبگذاری، گروهی از کارشناسان برای بررسی نتایج تعیین شدند. نتایج تصحیح شده در مجموعه داده VRDU منتشر شده گنجانده شده است. لطفاً برای جزئیات بیشتر در مورد پروتکل برچسبگذاری و طرح هر مجموعه داده، مقاله را ببینید.
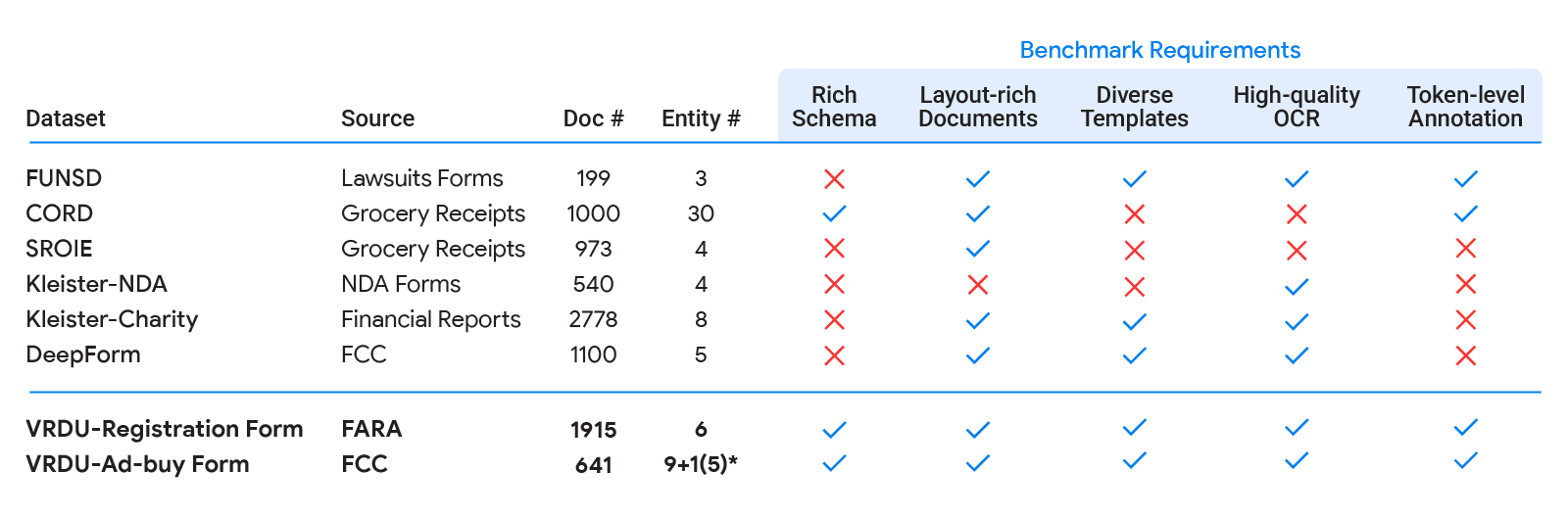 |
| معیارهای آکادمیک موجود (FUNSD، CORD، SROIE، Kleister-NDA، Kleister-Charity، DeepForm) در یک یا چند مورد از پنج الزامی که ما برای یک معیار درک خوب سند شناسایی کردهایم، کوتاهی میکنند. VRDU همه آنها را راضی می کند. مقاله ما را برای پیشینه هر یک از این مجموعه داده ها و بحث در مورد اینکه چگونه آنها یک یا چند مورد از الزامات را برآورده نمی کنند، ببینید. |
ما چهار مجموعه آموزشی مدل مختلف به ترتیب با 10، 50، 100 و 200 نمونه ساختیم. سپس، مجموعه دادههای VRDU را با استفاده از سه کار (که در زیر توضیح داده شده است) ارزیابی کردیم: (1) یادگیری الگوی واحد، (2) یادگیری الگوی ترکیبی، و (3) یادگیری الگوی دیده نشده. برای هر یک از این وظایف، ما 300 مدرک را در مجموعه تست قرار دادیم. ما مدل ها را با استفاده از امتیاز F1 در مجموعه تست ارزیابی می کنیم.
- آموزش قالب تک (STL): این سادهترین سناریویی است که در آن مجموعههای آموزش، آزمایش و اعتبارسنجی فقط شامل یک الگو هستند. این کار ساده برای ارزیابی توانایی یک مدل برای مقابله با یک الگوی ثابت طراحی شده است. به طور طبیعی، ما انتظار امتیازات بسیار بالایی در فرمول یک (0.90+) برای این کار داریم.
- آموزش الگوهای ترکیبی (MTL): این کار شبیه کاری است که اکثر مقالات مرتبط از آن استفاده می کنند: مجموعه های آموزشی، آزمایشی و اعتبارسنجی همگی حاوی اسنادی هستند که به مجموعه ای از الگوها تعلق دارند. ما بهطور تصادفی از مجموعههای داده اسناد را نمونهبرداری میکنیم و تقسیمبندیها را میسازیم تا مطمئن شویم توزیع هر الگو در طول نمونهگیری تغییر نکرده است.
- آموزش الگوی دیده نشده (UTL): این چالش برانگیزترین تنظیمات است، که در آن ارزیابی می کنیم که آیا مدل می تواند به الگوهای دیده نشده تعمیم یابد یا خیر. برای مثال، در مجموعه دادههای فرمهای ثبت، مدل را با دو قالب از سه الگو آموزش میدهیم و مدل را با یکی دیگر آزمایش میکنیم. اسناد موجود در مجموعههای آموزش، آزمایش و اعتبارسنجی از مجموعههای متفاوتی از الگوها استخراج میشوند. طبق دانش ما، معیارها و مجموعه داده های قبلی به صراحت چنین وظیفه ای را برای ارزیابی توانایی مدل برای تعمیم به الگوهایی که در طول آموزش دیده نمی شوند، ارائه نمی دهند.
هدف این است که بتوانیم مدل ها را بر اساس کارایی داده ها ارزیابی کنیم. در مقاله خود، دو مدل اخیر را با استفاده از وظایف STL، MTL و UTL مقایسه کردیم و سه مشاهده انجام دادیم. اولا، برخلاف سایر معیارها، VRDU چالش برانگیز است و نشان میدهد که مدلها فضای زیادی برای بهبود دارند. دوم، ما نشان میدهیم که عملکرد چند شات حتی برای مدلهای پیشرفته بهطور شگفتانگیزی پایین است و حتی بهترین مدلها امتیاز کمتر از F1 0.60 دارند. سوم، ما نشان میدهیم که مدلها برای مقابله با زمینههای تکراری ساختاریافته و عملکرد ضعیفی در آنها تلاش میکنند.
نتیجه
ما مجموعه داده جدید Visually Rich Document Understanding (VRDU) را منتشر می کنیم که به محققان کمک می کند پیشرفت را در وظایف درک سند بهتر پیگیری کنند. ما توضیح می دهیم که چرا VRDU چالش های عملی در این حوزه را بهتر منعکس می کند. ما همچنین آزمایشهایی را ارائه میکنیم که نشان میدهد وظایف VRDU چالشبرانگیز هستند، و مدلهای اخیر در مقایسه با مجموعه دادههایی که معمولاً در ادبیات استفاده میشوند با امتیازات F1 0.90+ فضای قابل توجهی برای بهبود دارند. ما امیدواریم انتشار مجموعه داده VRDU و کد ارزیابی به تیمهای تحقیقاتی کمک کند تا در درک اسناد پیشرفت کنند.
سپاسگزاریها
با تشکر فراوان از Zilong Wang، Yichao Zhou، Wei Wei و Chen-Yu Lee که همراه با Sandeep Tata این مقاله را نوشتند. با تشکر از مارک ناجورک، ریهام منصور و شرکای متعدد در سرتاسر Google Research و تیم Cloud AI برای ارائه بینش ارزشمند. با تشکر از جان گیلیارد برای ساخت انیمیشن های این پست.