با من به جزئیات نحوه استفاده از RAG برای ایجاد نتایج جالب برای سوالات مربوط به یک دامنه خاص بدون نیاز به تنظیم دقیق مدل خود بپردازید.
RAG چیست؟
RAG یا Retrieval Augmented Generation یک روش واقعاً پیچیده برای گفتن “پایه دانش + LLM” است. سیستمی را توصیف می کند که قبل از پرس و جو از LLM، علاوه بر آنچه کاربر ارائه کرده است، داده های اضافی را اضافه می کند. این اطلاعات اضافی از کجا آمده است؟ این می تواند از تعدادی منابع مختلف مانند پایگاه های داده برداری، موتورهای جستجو، سایر LLM های از پیش آموزش دیده و غیره باشد.
\ برای اطلاعات بیشتر در مورد RAG می توانید مقاله من را بخوانید.
در عمل چگونه کار می کند؟
1. بدون RAG، با نام مستعار کیس پایه
قبل از اینکه به RAG برسیم، باید در مورد “زنجیره ها” – دلیل وجود لانگ صحبت کنیم.زنجیروجود از مستندات Langchain، Chains به دنباله ای از تماس ها اشاره دارد – چه به یک LLM، یک ابزار، یا یک مرحله پیش پردازش داده. جزئیات بیشتر را می توانید در بخش آزمایشات مشاهده کنید.
\ یک زنجیر ساده که می توانید تنظیم کنید چیزی شبیه به –
chain = prompt | llm | output
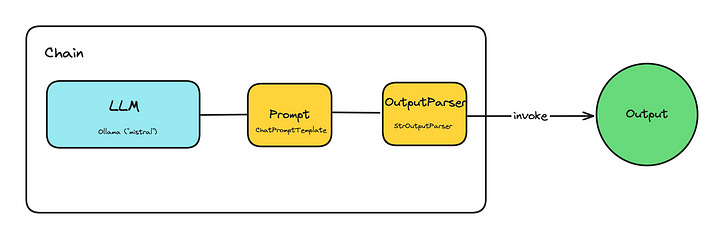
همانطور که می بینید، این بسیار ساده است. شما در حال ارسال یک اعلان به یک LLM انتخابی هستید و سپس از یک تجزیه کننده برای تولید خروجی استفاده می کنید. شما از مفهوم Langchain از “زنجیره” برای کمک به ترتیب دادن این عناصر استفاده می کنید، بسیار شبیه …